Spark中ASL实现用户协同过滤与物品协同过滤算法详解
需积分: 9 109 浏览量
更新于2024-09-09
收藏 187KB DOCX 举报
协同过滤算法是一种广泛应用在推荐系统中的技术,它主要通过分析用户的行为数据,找到具有相似兴趣的个体,从而推荐可能感兴趣的项目。在本文中,我们将重点讨论两种常见的协同过滤方法:用户协同过滤(User-based Collaborative Filtering, UCF)和物品协同过滤(Item-based Collaborative Filtering, ICF),以及如何在Apache Spark框架中使用矩阵分解技术——最小二乘法(Alternating Least Squares, ALS)进行实现。
1. **用户协同过滤(UCF)**:
UCF以用户为中心,通过计算用户之间的相似度,找出与目标用户兴趣相似的其他用户。例如,如您提供的流程图所示,用户A和用户C在兴趣上较为接近,如果用户A未对物品D进行评价,那么基于用户相似性,算法可能会推荐物品D给用户A。这种推荐策略依赖于用户历史行为数据,旨在为用户提供他们可能尚未发现但与他们喜好相符的内容。
2. **物品协同过滤(ICF)**:
相反,ICF则是以物品为焦点,寻找同时被多个用户关注的物品。假设所有看过物品A的用户也常常关注物品C,那么在ICF的逻辑下,将把物品C推荐给用户C,即使用户本身未直接交互过这个物品。这种方法更关注物品之间的关联性,而非用户间的直接联系。
3. **Spark中的实现——最小二乘法(ALS)**:
在Apache Spark的机器学习库MLlib中, ALS( Alternating Least Squares)提供了一种高效的矩阵分解方法,用于处理大规模数据集上的推荐问题。在`JavaALSExample`代码示例中,通过创建一个`Rating`类来表示用户的评分记录,然后创建` ALSModel`对象,训练模型并使用`RegressionEvaluator`评估模型性能。用户可以通过输入用户的ID和物品ID来获取个性化推荐,利用ALS的预测功能找到与用户兴趣匹配的潜在物品。
4. **实战应用**:
在实际应用中,用户协同过滤和物品协同过滤可以单独使用,也可以结合使用,以提高推荐的准确性和多样性。Spark的Java API简化了这些操作,使得开发人员能够轻松地在分布式环境中构建实时推荐系统。
总结来说,协同过滤算法的核心在于发现用户或物品之间的隐含关系,并利用这些关系进行个性化推荐。在Spark中,利用矩阵分解技术(如ALS)的高效性能,使得这种算法在大数据场景下变得更为实用。理解并掌握这些原理和实现细节,对于构建高质量的推荐系统至关重要。
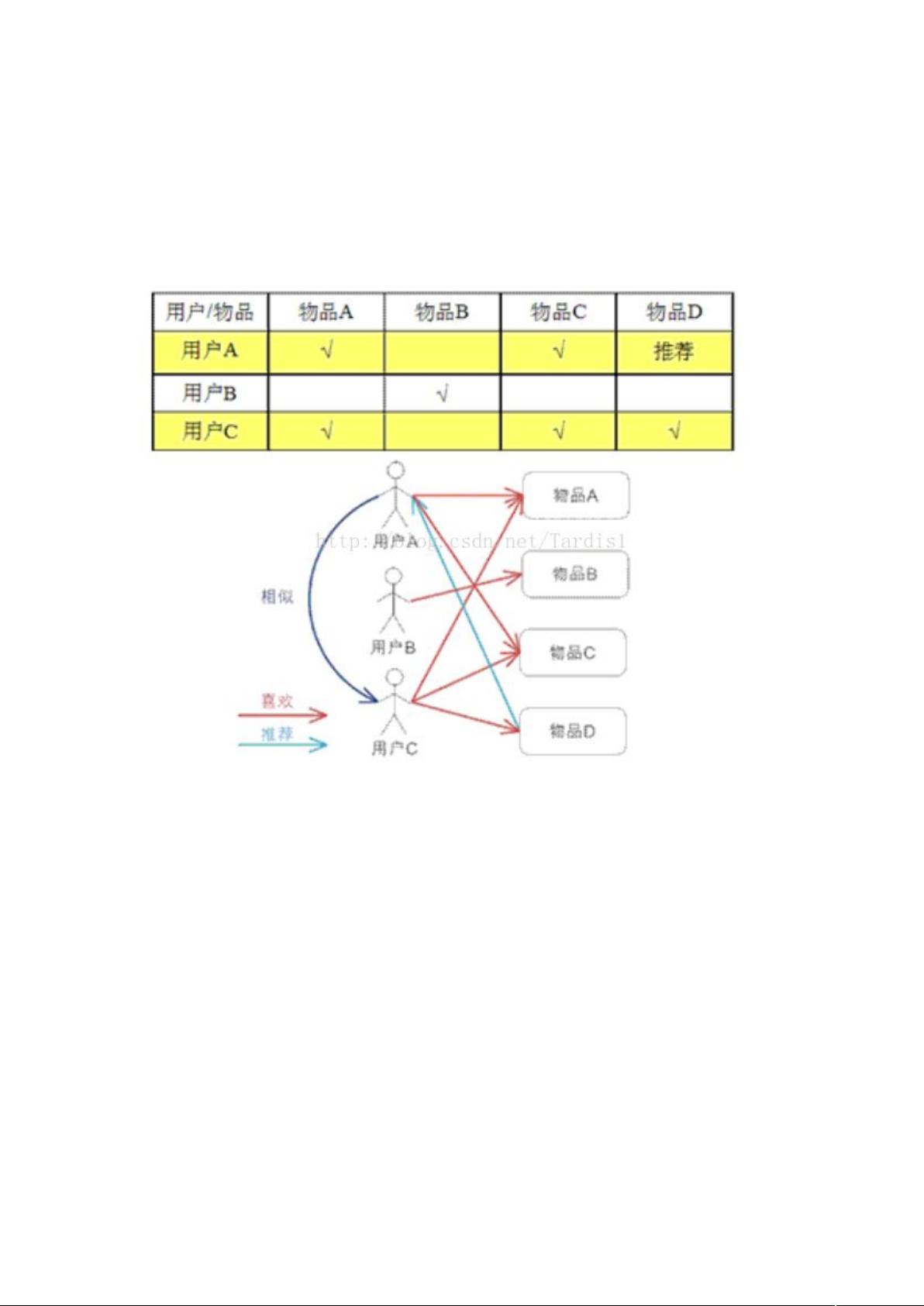
常用的推荐算法用户协同过滤法,通常有 以用户为主体,通过算法得到和本用户类
似的用户,找出类似用户喜欢的,但本用户还没有接触的物体进行推荐 和 以物品为主
体,推荐与此物体同时被关注的物体两种方式。
方法:如下图,用户 和用户 比较类似,并且用户 没有关注过物品 ,因此按照
的逻辑,会推荐物品 给用户
算法如下图,看过物品 的都看过物品 ,因此将物品 推荐给用户
下载后可阅读完整内容,剩余7页未读,立即下载
2024-02-22 上传
2023-10-09 上传
2024-05-19 上传
2024-01-17 上传
2024-01-20 上传
2024-05-16 上传
2011-03-21 上传
2024-01-10 上传
2024-11-16 上传

年轻_就是资本
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- java版商城源码-4sg:小而简单的SVGSankey生成器(使用XSLT)
- FPGA实现推箱子游戏.7z
- Single-Price-Grid-Component
- RaspberryPi 安装 WindowsArm 驱动 20200315drv_rpi4.zip
- PiperBlocklyLibrary:CircuitPython库支持使用RP Pico微控制器的块编码
- 易语言图片任意旋转源码.zip易语言项目例子源码下载
- Grades_Calc
- cschool:基本的Rails应用程序中的基本代码学校-谁想要雄心勃勃的人都可以免费打开手提袋
- 码
- data-structure
- 行业文档-设计装置-一种笔尾设置可折叠掏耳勺的方便笔.zip
- 华为简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- usov.tech
- 蒂莫·格拉斯特拉
- Webcam Fun +-开源
- semaphore_nuxt
