Tensorflow协调器与Wavenet模型实践:从安装问题到数据导入
需积分: 0 90 浏览量
更新于2024-08-04
收藏 484KB DOCX 举报
本周的IT行业周报由王旭撰写,主要内容聚焦于使用TensorFlow构建Wavenet模型的实践过程。以下是报告中的关键知识点:
1. **建立TensorFlow协调器**:
王旭在构建Wavenet模型时,首先面临的问题是创建一个协调器(Coordinator),这是在多线程环境中管理和控制分布式计算的重要组件。通过协调器,可以确保线程之间的同步,避免数据竞争和一致性问题。
2. **处理VCTK数据集**:
使用VCTK原始数据集作为输入是模型训练的关键步骤。VCTK是一个大型的语音数据集,由于数据量大(14GB),王旭不得不先压缩传输部分文件(约2GB)到服务器。他导入数据并解压到指定路径,但在后续操作中遇到了问题。
3. **TensorFlow环境问题**:
在尝试运行代码时,王旭遇到了与TensorFlow的兼容性问题,具体表现为无法调用。他通过网络搜索找到可能的原因,涉及到CUDA安装和环境配置,最终通过重新安装TensorFlow解决了这个错误。
4. **模型试运行及调试**:
试运行过程中,王旭发现代码能够运行但报错,提示找不到wav文件。尽管文件存在,这表明在数据路径设置或数据加载上存在问题。这部分工作因错误而中断,需要进一步检查和修正。
5. **Wavenet源代码结构**:
Wavenet项目的代码主要集中在train.py、generate.py和wavenet文件夹。train.py负责模型训练,generate.py用于生成语音,wavenet文件夹则提供了模型构建和音频处理的辅助类和函数。特别是model.py中的create_variables()、create_causal_layer()和create_dilation_layer()等函数,展示了模型构建的核心技术。
6. **因果卷积和多线程**:
对于Wavenet模型中的因果卷积和扩大卷积,王旭提到它们涉及到复杂的多线程技术。这些技术在模型设计中起到重要作用,但目前他还未能完全理解。这部分知识的深入学习将是他下一步的重点。
7. **train.py代码解析**:
train.py文件包含了参数设置、模型保存和加载功能,以及核心的main()方法。其中,参数设置涉及到模型训练的细节,如超参数、数据路径等,而save()和load()方法分别用于模型的存档和加载,以支持持续训练和复现研究。
综上,这份周报记录了作者在构建Wavenet模型过程中遇到的技术挑战,包括TensorFlow协调器的使用、数据处理、环境配置和源代码的理解。王旭将继续深入研究网络结构和相关算法,以便解决遇到的问题并推进项目进展。
WaveNet 试运行与源码简单解析
Wavenet 试运行
本周我尝试运行了一下 wavenet。首先是在自己的笔记本上尝试,但由于
librosa 包装不上,我就在之前 magneta 的服务器上试着安装。当安装好了 librosa
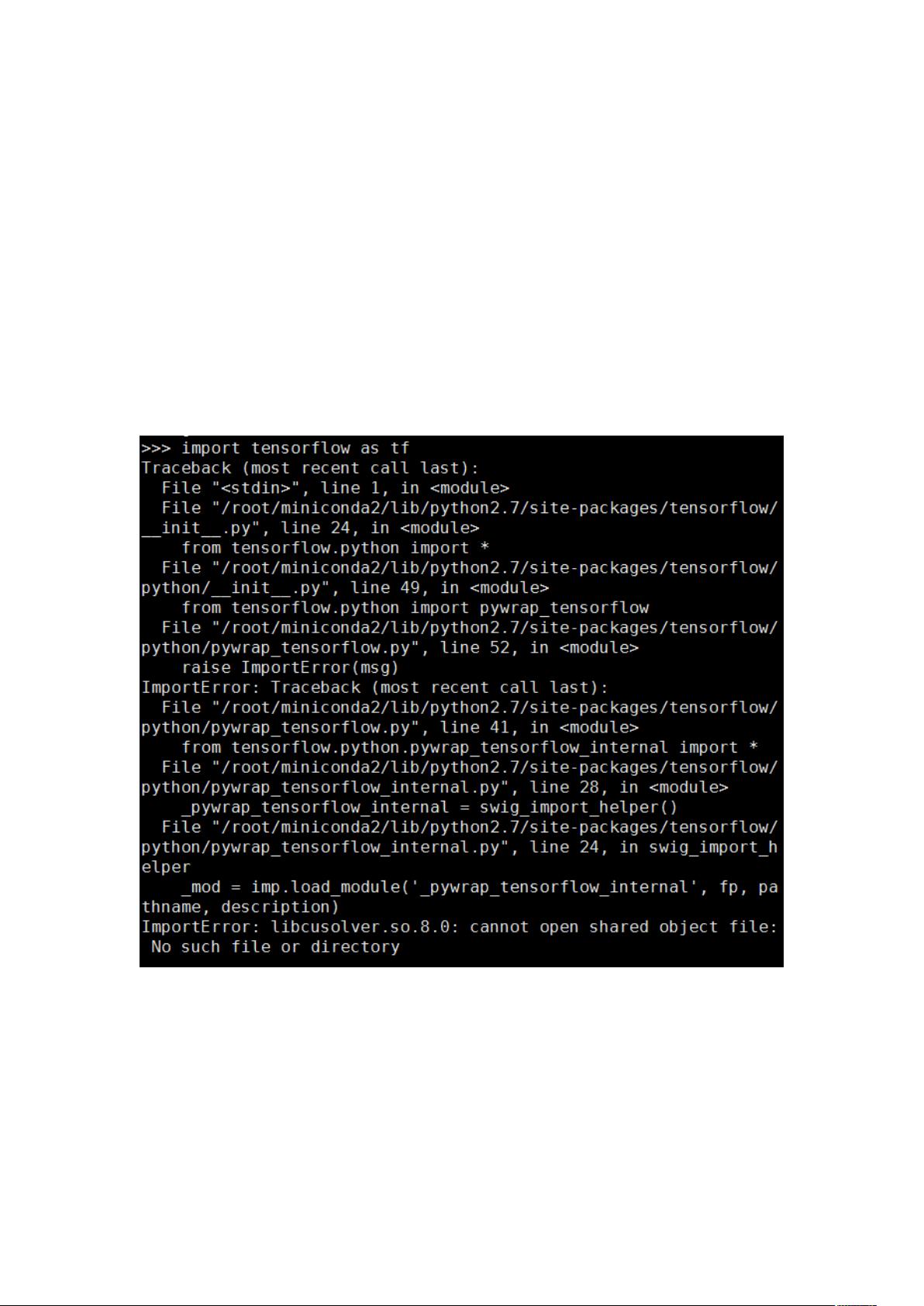
之后,发现在试运行的时候,无法调用 tensorflow(之前弄 magenta 时并没有出
现这个问题)。遇到的问题截图如下:
针对此时出现的问题,我上网查看了半天相似错误的解决办法,比如如下的
解决办法:
下载后可阅读完整内容,剩余7页未读,立即下载
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2021-06-24 上传
2015-04-26 上传

陈后主
- 粉丝: 39
- 资源: 340
 我的内容管理
展开
我的内容管理
展开







最新资源
- react_website
- HCMGIS_Caytrong_Local
- 毕业设计&课设--毕业设计之鲜花销售网站的设计与实现.zip
- django-compiling-loader:Django的编译模板加载器
- Excel模板送货单EXCEL模板.zip
- tfbert:一个使用tf2复现的bert模型库
- 商用服务机器人行业研究报告-36氪-2019.8-47页.rar
- 愤怒的小鸟
- recommend-go:用户偏好推荐系统
- react-selenium-ui-test-example:示例项目显示了如何将Selenium Webdriver与Mocha结合使用以在本地环境中运行UI级别测试
- AttachmentManager:附件管理器库从Android设备中选择文件图像
- Excel模板财务报表-现金收支日记账.zip
- jquery-browserblacklist:处理浏览器黑名单的 jQuery 插件
- 毕业设计&课设--毕业设计--在线挂号系统APP(VUE).zip
- 017.长治市行政区、公交线路、 物理站点、线路站点、建成区分布卫星地理shp文件(2021.3.28)
- yfcmf-tp6:yfcmf新版本,基于thinkphp6.0和fastadmin
