Apache Solr 4.4官方指南:深度解析与安装教程
需积分: 10 108 浏览量
更新于2024-07-25
收藏 4.38MB PDF 举报
Apache Solr Reference Guide 4.4 是一份详尽的指南,专为Apache Solr 4.4版本量身打造。该手册由Apache Software Foundation (ASF)发行,遵循Apache License, Version 2.0。这份文档旨在为读者提供对Solr这款开源搜索解决方案的深入理解,特别适合那些希望在实际操作和配置中掌握Solr技术的专业人士。
Solr是一款强大的全文搜索引擎,它建立在Lucene库之上,为网站和应用程序提供高效的搜索功能。本指南覆盖了从安装和设置开始,帮助用户逐步了解Solr的基础架构、配置选项以及如何优化搜索性能。通过阅读此指南,读者可以学习到以下关键知识点:
1. **许可协议**:文档明确指出,Solr是根据Apache License 2.0发布的,这意味着它可以在符合许可证条款的情况下自由下载和使用,但需保持版权信息,并且软件在没有明确同意的情况下是“原样”提供的,即不附带任何保证或条件。
2. **主要内容**:
- **入门指南**:这部分内容为新手提供了安装和配置Solr的基本步骤,包括如何获取最新版本的Solr,可能涉及下载、环境配置、依赖管理等关键环节。
- **系统架构**:深入解析Solr的核心组件,如Searcher、IndexWriter、Query Parser等,帮助理解索引和查询处理的原理。
- **配置与管理**:涵盖了索引配置文件(如schema.xml)、数据导入(如Data Import Handler)、查询参数调整等内容,以实现定制化的搜索体验。
- **性能优化**:介绍如何调整索引设置、优化查询性能、使用缓存、分布式部署等策略来提高搜索效率。
- **高级特性**:探讨如Cloud Search、Facets、Spell Checking等高级功能的使用方法和实现原理。
3. **资源获取**:指南指明了访问Apache Solr官方网站 <http://lucene.apache.org/solr/> 的路径,那里能找到最新的Solr文档、下载链接以及社区支持。
Apache Solr Reference Guide 4.4 是一个不可或缺的参考资料,无论你是初学者还是经验丰富的开发者,都能从中获得深入理解和实用技巧,以便有效地将Solr融入到项目中,提升搜索服务的质量和性能。

16Apache Solr Reference Guide 4.4
The Main Logging Screen
While this example shows logged messages for only one core, if you have multiple cores in a single instance, they will each be listed, with the
level for each.
Selecting a Logging Level
When you select the link on the left, you see theLevel
hierarchy of classpaths and classnames for your instance. A
row highlighted in yellow indicates that the class has logging
capabilities. Click on a highlighted row, and a menu will
appear to allow you to change the log level for that class.
Characters in boldface indicate that the class will not be
affected by level changes to root.
For an explanation of the various logging levels, see
.Configuring Logging
Cloud Screens
When running in SolrCloud mode, an option will appear in
the Admin UI between Logging and Core Admin for Cloud.
It's not possible at the current time to manage the nodes of
the SolrCloud cluster, but you can view them and open the Solr Admin UI on each node to view the status and statistics for the node and each
core on each node.
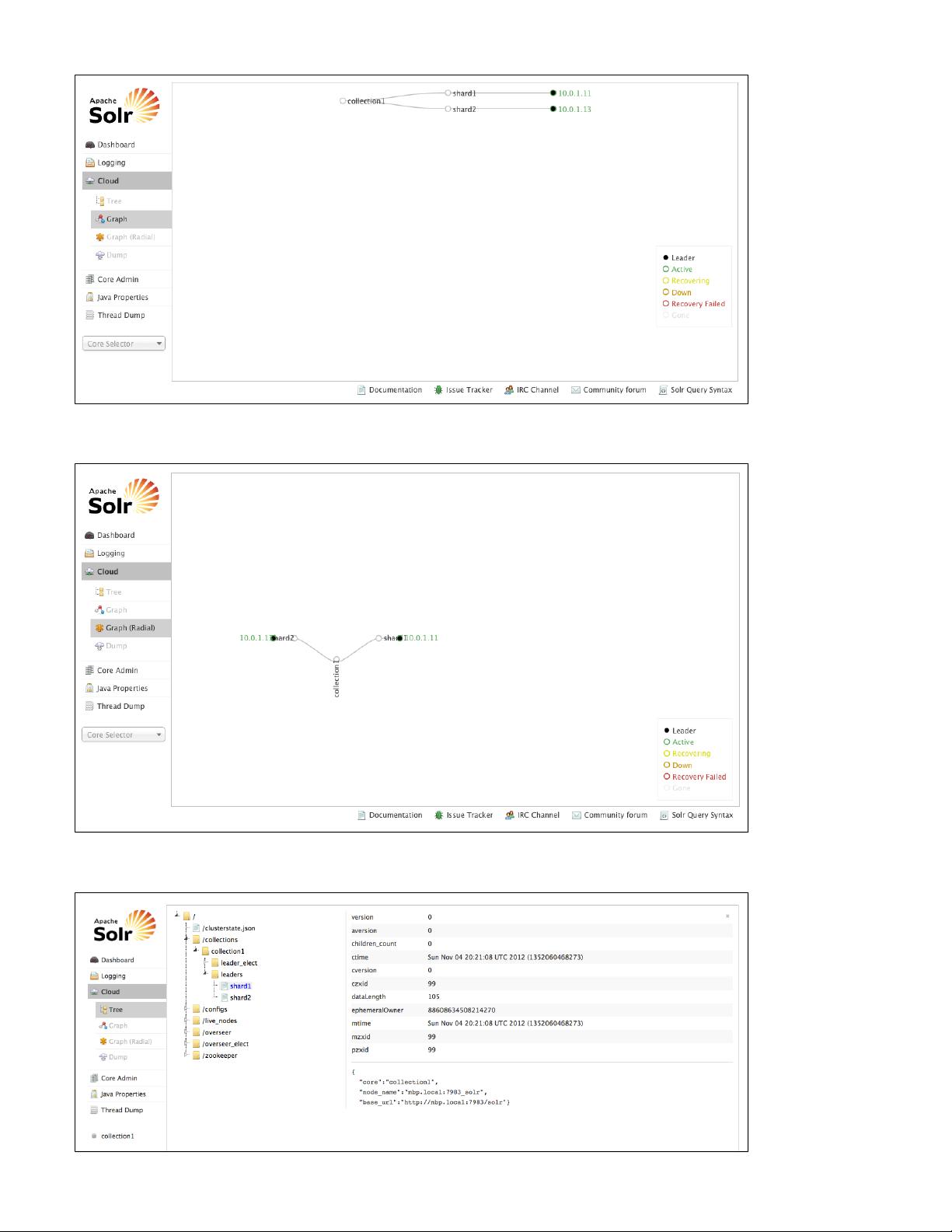
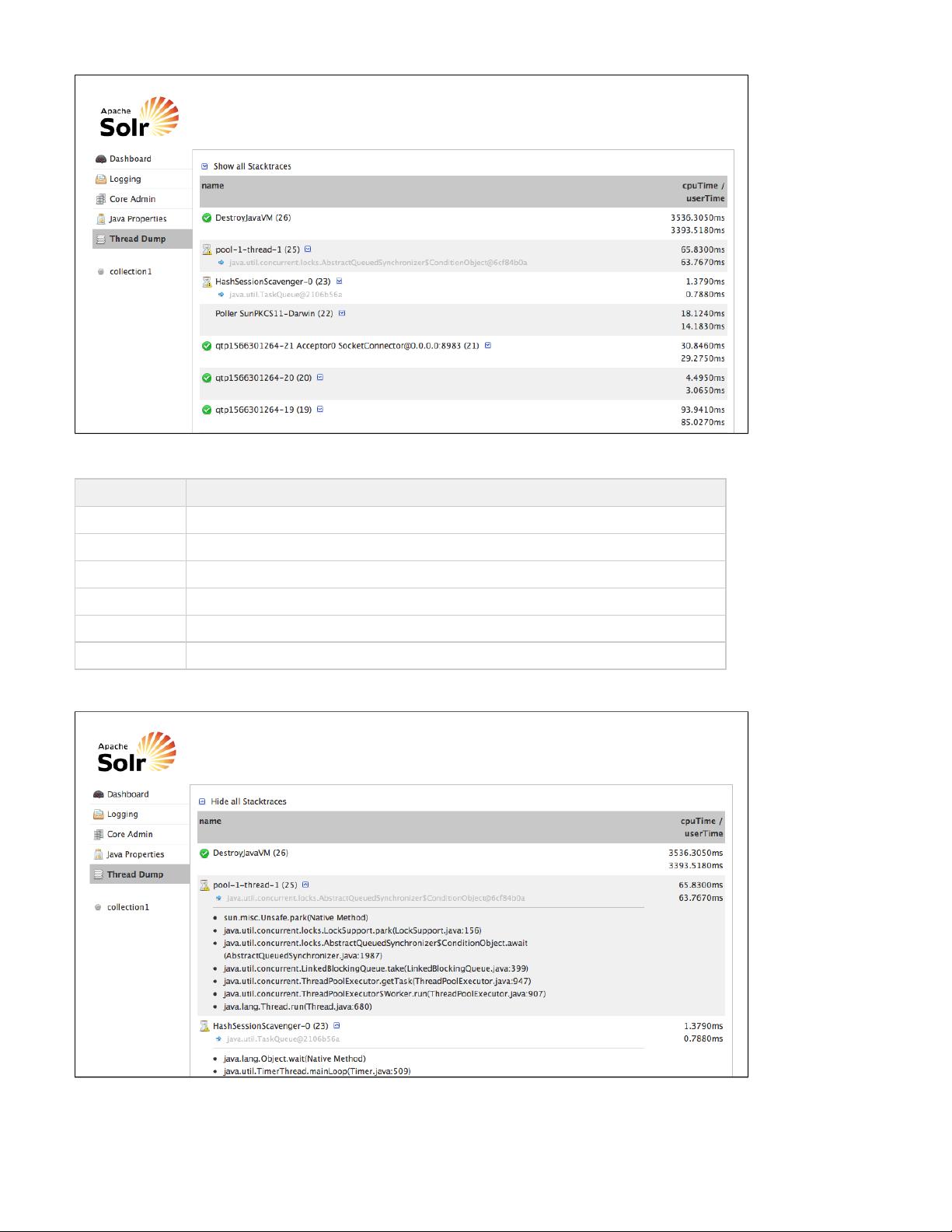
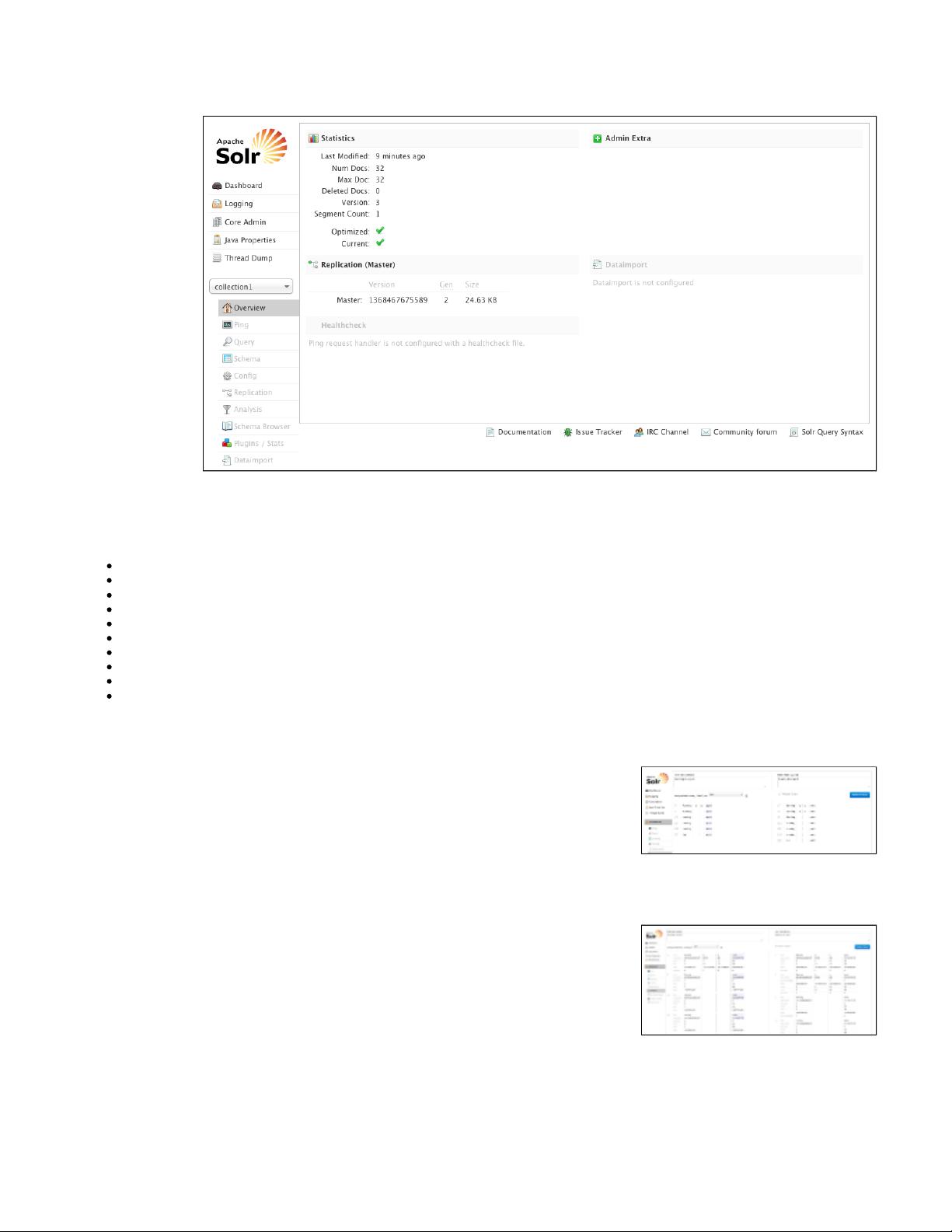
Click on the Cloud option in the left-hand navigation, and a small sub-menu appears with options called "Tree", "Graph", "Graph (Radial)" and
"Dump". The default view (which is "Tree") shows a graph of each core and the addresses of each node. This example shows a very simple
two-node cluster with a single core:

剩余340页未读,继续阅读
114 浏览量
2018-04-13 上传
105 浏览量
2012-04-15 上传
115 浏览量
140 浏览量
108 浏览量
2013-05-17 上传
2014-11-06 上传

manorn
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android底部导航栏实现教程与示例
- 基于FLD的人脸识别系统_V2版本发布
- React应用的构建与测试入门指南
- MongoDB与Node.js构建电子商务平台功能详解
- 轻狂PDF工具包v1.1.1.0:免费制作与管理PDF的强大软件包
- KodiMm.github.io: 探索我的第一个主机项目
- JS+CSS实现图片列表响应式布局技巧
- STM32控制HC-SR04模块实现超声波测距
- 全面解析SAP JCO3在各操作系统下的版本特性
- Delphi实现的unigui虚拟键盘
- 一步导入IntelliJ IDEA全局设置,简化配置流程
- 探索HTML与GitHub.io的结合运用
- 解决Windows 10 U盘识别问题的官方驱动工具
- 微信风格C#飞机大战游戏开发与改进计划
- 掌握文件编码检测与转码技术
- JavaScript交互式控制台应用:管理任务
