Flume高级配置与实战指南
需积分: 10 171 浏览量
更新于2024-07-28
收藏 994KB PDF 举报
"Flume配置使用指南,涵盖了从基础到高级的配置方法,包括单节点快速启动、事件结构、分布式模式、故障转移策略、逻辑配置、安全集成等内容,旨在帮助用户深入理解和应用Flume."
Flume是Apache开发的一款用于收集、聚合和移动大量日志数据的工具,它支持高可用性和容错性。Flume配置是其核心部分,理解和掌握Flume配置能够有效优化数据流处理。
**1. 单节点快速启动 (flumesinglenodequickstart)**
在单节点设置中,一个Flume节点既是source也是sink,用于简单测试和快速上手。配置文件通常包含source、channel和sink的定义,如读取文本文件、跟踪文件尾部(tail和multitail)或使用合成源(synth)。
**2. 事件 Anatomy of an Event**
Flume中的基本数据单位是事件,它由header和body组成。Header存储元数据,而Body则包含实际的数据内容。
**3. 分布式模式**
Flume支持两种分布式模式:伪分布和全分布。
- **Pseudo-distributed Mode**: 在此模式下,Flume节点通过指定主节点进行配置。配置可以通过主节点推送给各个节点。
- **Fully-distributed Mode**: 在全分布模式中,节点可以直接与其他节点通信,无需中央主节点。这增加了系统的健壮性和可扩展性。
**4. 高级配置策略**
- **Aggregated Configurations**: 集成多个配置,允许更复杂的数据流管理。
- **Tiering Flume Nodes: Agents and Collectors**: 通过层级化节点设计,实现数据的多级处理和传输。
- **Manually Specifying Failover Chains** 和 **Automatic Failover Chains**: 提供故障转移机制,确保数据流动的连续性。
- **Logical Configurations** 包括Logical Sources and Logical Sinks,允许抽象出逻辑上的数据源和数据接收器,简化复杂网络环境下的配置。
**5. 流控与隔离 (Flow Isolation)**
Flume支持流的独立控制,使得不同数据流可以并行处理,互不影响。
**6. 多主节点配置 (Multiple Masters)**
Flume可以配置连接到多个主服务器,提高系统的可靠性。
**7. 配置存储 (Configuration Stores)**
配置存储允许在外部系统中存储和检索Flume配置,例如ZooKeeper。
**8. 集成ZooKeeper (Configuring the ZBCS)**
Flume可以利用ZooKeeper进行集群协调和配置管理。
**9. Gossip in Distributed Mode**
Flume节点间的通信采用gossip协议,以高效地传播状态信息。
**10. 命令行界面 (The Flume Command Shell)**
提供交互式的命令行工具,方便用户管理和监控Flume节点。
**11. Sink Decorators**
Sink Decorators允许在数据到达最终目的地之前对其进行修改或增强,如添加自定义元数据。
**12. 自定义元数据提取 (Custom Metadata Extraction)**
允许开发人员实现自己的逻辑来解析事件并提取元数据。
**13. Flume与HDFS的安全集成 (Flume and HDFSSecurity Integration)**
Flume可以与Hadoop的HDFS安全环境无缝配合,确保数据传输的安全性。
**14. 环境变量 (Flume Environment Variables)**
通过设置环境变量,可以影响Flume的行为和配置。
Flume的配置使用涉及到多个层面,从简单的数据采集到复杂的分布式环境管理,理解并熟练运用这些配置能有效地优化日志处理和数据流动,为大数据分析提供稳定可靠的基础。
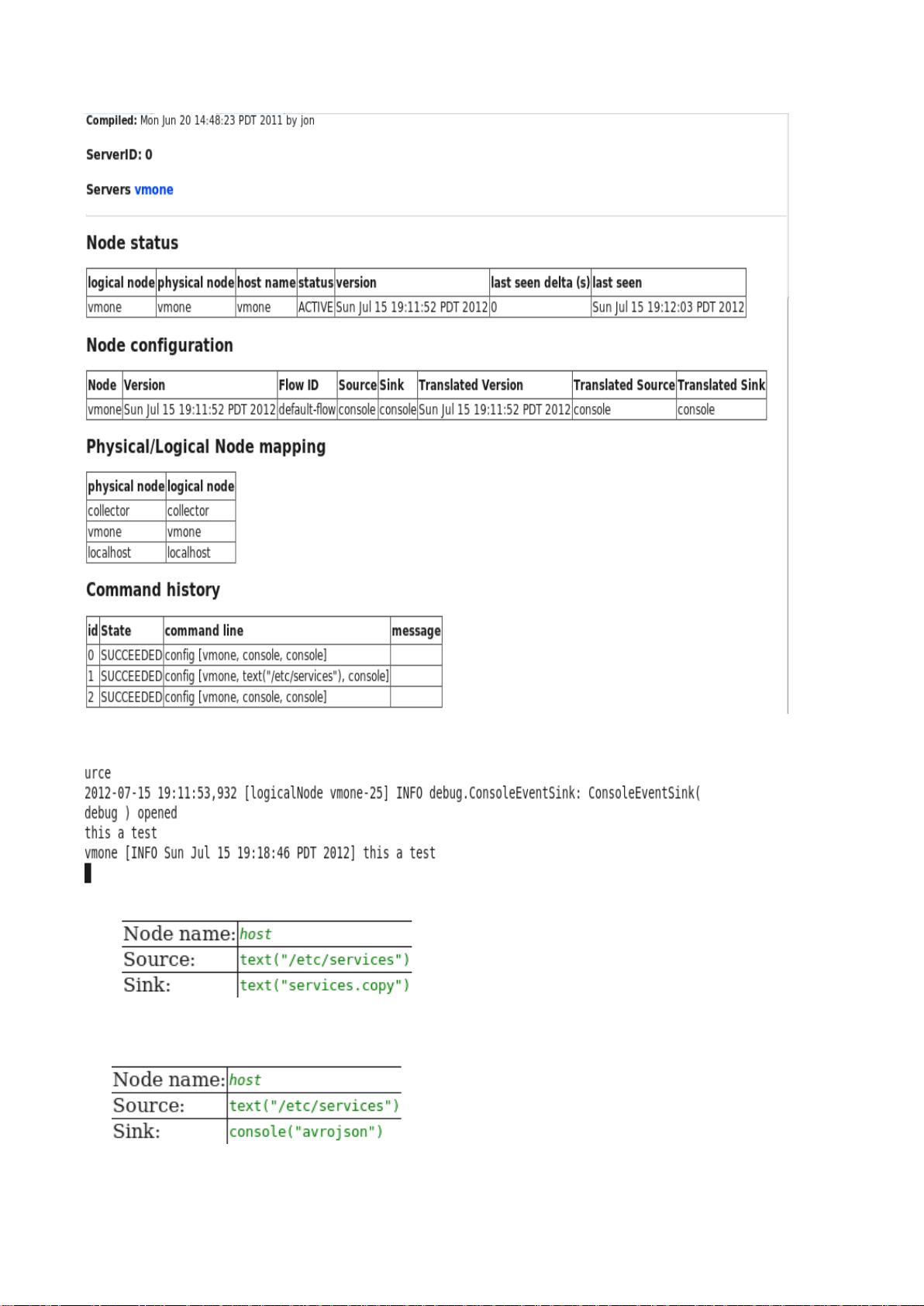
从上面的信息中可以看出 node 的状态信息,配置信息,命令历史。
然后我们在 node 的终端中输入 this is a test 将会输出如下信息。
下面是一些 sink 的配置和说明
sink 是文件
console sink 增加了参数,表示控制台以 json 格式输出数据
剩余15页未读,继续阅读
340 浏览量
586 浏览量
757 浏览量
170 浏览量
150 浏览量
388 浏览量

yanghuashuiyue
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- VS2010环境Qt链接MySQL数据库测试程序
- daycula-vim主题:黑暗风格的Vim色彩方案
- HTTPComponents最新版本发布,客户端与核心组件升级
- Android WebView与JS互调的实践示例
- 教务管理系统功能全面,操作简便,适用于winxp及以上版本
- 使用堆栈实现四则运算的编程实践
- 开源Lisp实现的联合生成算法及多面体计算
- 细胞图像处理与模式识别检测技术
- 深入解析psimedia:音频视频RTP抽象库
- 传名广告联盟商业正式版 v5.3 功能全面升级
- JSON序列化与反序列化实例教程
- 手机美食餐饮微官网HTML源码开源项目
- 基于联合相关变换的图像识别程序与土豆形貌图片库
- C#毕业设计:超市进销存管理系统实现
- 高效下载地址转换器:迅雷与快车互转
- 探索inoutPrimaryrepo项目:JavaScript的核心应用
