多机环境下Hadoop集群安装配置指南
需积分: 17 177 浏览量
更新于2024-07-21
收藏 3.24MB DOCX 举报
"Windows+Linux环境下Hadoop的安装配置教程"
在大数据处理领域,Apache Hadoop是一个广泛使用的开源框架,它允许分布式存储和处理大量数据。本教程将详细介绍如何在Windows和Linux双系统中安装并配置Hadoop,以及如何在多机环境中搭建Hadoop集群。
首先,我们需要准备的软件包括Ubuntu 14.04桌面版、Hadoop 2.7.0和适用于Linux的JDK 1.7.0。所有这些都可以从官方网站或可靠的下载源获取。特别注意,这里选择的JDK版本是针对64位系统的。
一、引言
在多机环境下构建Hadoop集群,意味着要在每台机器上安装相同的环境,并通过网络连接形成一个协作的计算网络。本教程假设你已经在每台机器上安装了双系统(Windows和Linux),或者仅安装了Linux系统。
二、部署过程说明
1. **单机部署阶段**
- **安装Ubuntu**: 安装Ubuntu 14.04.2 Desktop版,这将为Hadoop提供运行环境。
- **安装JDK**: 在`/usr`目录下创建名为`Java`的文件夹,然后将下载的JDK安装包复制到这个文件夹中。完成安装后,记得配置环境变量,使得系统可以找到JDK。
- **安装Hadoop**: 解压Hadoop 2.7.0压缩包,并按照官方文档的指示配置相关路径和环境变量。
2. **配置JAVA环境变量**
配置`JAVA_HOME`环境变量,将其指向JDK的安装路径,确保Hadoop能识别和使用Java运行时。
3. **创建SSH密钥**
在每台机器上生成SSH密钥对,这将用于节点之间的无密码登录,简化集群管理。
2. **多机环境下的配置阶段**
- **/etc/hosts文件的配置**:更新每台机器的`/etc/hosts`文件,添加所有参与集群的机器的主机名和IP映射,以便于节点间通信。
- **多机的SSH-key配置**:在master节点生成的SSH公钥复制到所有slave节点的相应位置,实现无密码登录。
- **JAVA_HOME环境变量配置**:确保所有机器上的`JAVA_HOME`环境变量配置一致,指向同一JDK版本。
- **master和slaves文件的配置**:在master节点的Hadoop配置目录中,编辑`masters`文件列出master节点,`slaves`文件列出所有slave节点。
- **配置core-site、mapred-site和hdfs-site文件**:根据集群需求,修改这些配置文件以指定HDFS和MapReduce的相关参数。
3. **启动运行阶段**
- **格式化Namenode**:首次启动Hadoop集群前,必须对Namenode进行格式化,这会初始化HDFS的数据存储。
- **启动Hadoop**:按照Hadoop的启动顺序,依次启动DataNode、NameNode、ResourceManager和NodeManager等服务,确保集群正常运行。
三、参考资源
在完成以上步骤后,你将拥有一个运行中的Hadoop多机集群。后续可以通过监控和调整配置来优化性能。为了更好地理解和操作Hadoop集群,建议查阅更多相关资料,包括官方文档和社区论坛,以便解决可能出现的问题和学习更高级的使用技巧。
搭建Hadoop集群需要耐心和细致,遵循正确的步骤,并不断学习和实践。一旦成功,你将拥有一个强大的分布式计算平台,能够处理大规模的数据处理任务。
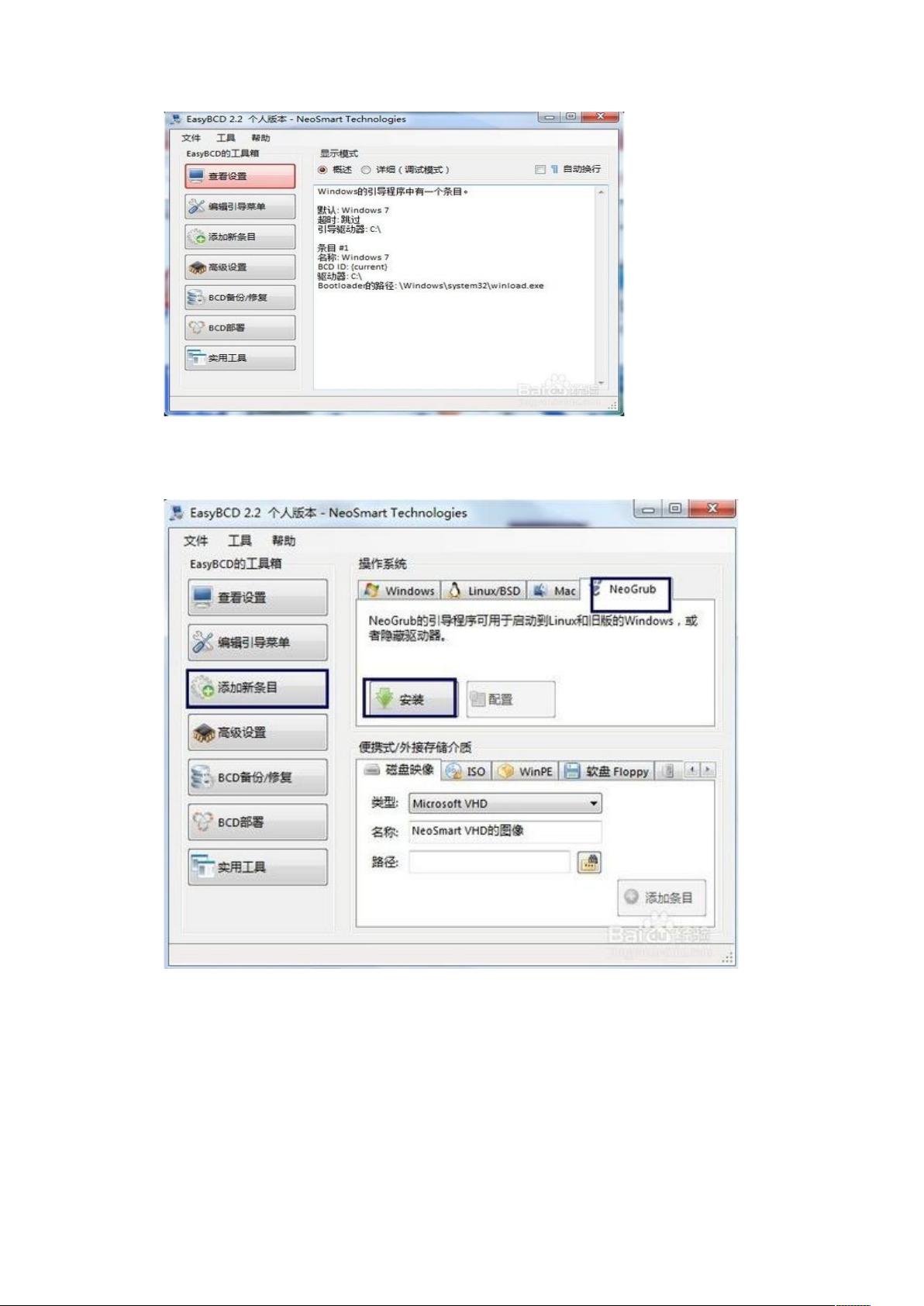
2.1.1.2.8 选择“添加新条目”,然后选择“NeoGrub”,点击“安装”
2.1.1.2.9 点击右边的配置
剩余28页未读,继续阅读
2023-03-27 上传
2023-02-25 上传
2023-06-06 上传
2024-10-09 上传
2023-05-20 上传
2024-10-11 上传

珠穆拉玛峰
- 粉丝: 176
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
