逻辑回归详解:分类算法与sklearn应用实例
需积分: 0 46 浏览量
更新于2024-08-04
收藏 219KB DOCX 举报
逻辑回归1:一种强大的分类算法详解
逻辑回归,作为机器学习中的一种基础算法,主要用于解决二分类问题,如预测患者是否会患上某种疾病或某个事件发生的可能性。其核心在于利用sigmoid函数将线性回归的输出映射到[0,1]的区间内,使得结果更符合概率解释,从而提供一个概率性分类。
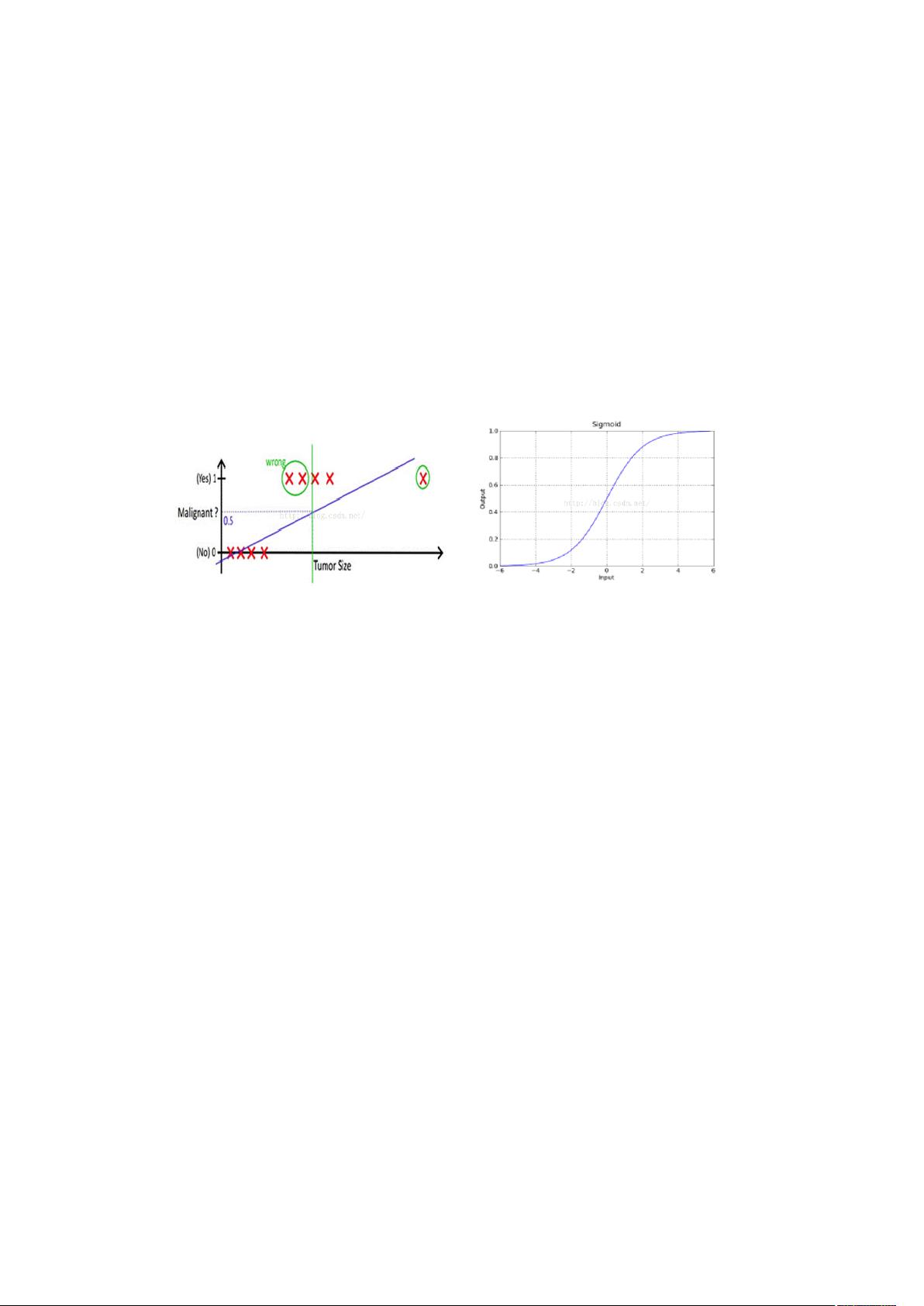
相较于线性回归,逻辑回归在处理非线性可分数据时更具优势。线性回归通过设置阈值进行分类可能会导致决策边界不够灵活,无法适应所有数据点。而sigmoid函数的单调上升特性以及输出的概率形式,使其在处理这类问题上表现出色,能够提供更鲁棒的分类性能。
sigmoid函数的数学表达式为f(x) = 1 / (1 + e^(-x)),输入范围是负无穷到正无穷,输出范围则限定在0到1之间,符合概率分布的要求。其连续性的特点使得模型能够平滑地调整预测,避免了可能出现的突然转折。
逻辑回归的求解过程通常涉及以下步骤:
1. **构造预测函数**:首先,我们需要构建一个线性模型,比如y = wx + b,其中w是权重向量,b是偏置项。
2. **定义代价函数**:常用的代价函数是交叉熵损失函数,衡量实际标签与预测概率之间的差异。
3. **优化算法**:使用梯度下降或其他优化方法来最小化代价函数,更新权重和偏置,直到找到最优解。
4. **参数估计**:通过迭代优化,得到回归参数w和b的最佳组合,使得模型的预测尽可能接近真实类别。
在Python的scikit-learn库中,逻辑回归的实现非常简便。例如,我们可以使用`sklearn.linear_model.LogisticRegression`类进行模型训练。经典的实战例子是使用鸢尾花数据集(Iris dataset),这是模式识别领域的一个经典数据集,包含3个类别(IrisSetosa、IrisVersicolour、IrisVirginica)的花朵特征数据。数据集下载地址为<http://archive.ics.uci.edu/ml/datasets/Iris>。
数据集包含150个样本,每个样本有4个连续变量(花萼长度、宽度和花瓣长度、宽度)和1个类别标签。在实验中,我们可以导入必要的库,加载数据,然后创建一个逻辑回归模型,并使用鸢尾花数据对其进行训练和预测。
实验过程包括以下步骤:
- 导入所需的库:`numpy`、`sklearn.linear_model.LogisticRegression`和`matplotlib.pyplot`。
- 定义类别映射函数,将类别标签转化为数值。
- 加载数据,将数据集划分为特征和目标变量。
- 初始化逻辑回归模型。
- 使用数据训练模型。
- 可视化预测结果或者评估模型性能。
逻辑回归是一种实用且直观的分类算法,尤其适用于二分类问题。通过理解sigmoid函数的作用、代价函数的选择和优化方法,我们可以有效地应用逻辑回归来解决实际问题,并通过实例演示来深入学习和实践。
逻辑回归
1. 简介
逻辑回归是一种常见的分类算法,最常见的应用场景就是预测和判别,例如癌症的预测、
某人患某种疾病的概率等等,这些都是一种两分类问题,即输出的结果只有两种,分别
代表两个类别。
2. 逻辑回归与线性回归
在上述的两分类问题中,线性回归通过设定阈值的方式很难完成一个鲁棒性很好的分类
器,对于这种不按套路出牌的数据点,线性回归实在是无能为力,而逻辑回归所用到的
sigmoid 函数就可以很好的解决这一问题。
Sigmod 函数的输入范围是,而输出结果在 0 到 1 之间,这恰好满足了概率的分布要求,
而且这是一个单调上升的函数,具有良好的连续性。
3. 逻辑回归的求解过程
(1) 寻找预测函数
(2) 构造代价函数
(3) 通过特定算法使代价函数最小并求得回归参数
4. sklearn 中的代码示例
由于 sklearn 中我们所需函数都已经被定义好了,所以我们直接使用就可以,这大大简
化了我们的工作量
4.1 实验数据:
鸢尾花数据集或许是最有名的模式识别测试数据。早在 1936 年,模式识别的先驱
Fisher
就在论文"The use of multiple measurements in taxonomic problems"中使用了它(直
至今日该论文仍然被频繁引用)。该数据集包括 3 个鸢尾花类别,每个类别有 50
个样本。
其中一个类别是与另外两类线性可分的,而另外两类不能线性可分。
下载后可阅读完整内容,剩余3页未读,立即下载
2021-05-12 上传
2022-08-08 上传
2021-05-12 上传
2021-05-12 上传
2021-05-12 上传
2021-05-12 上传
2021-05-12 上传
2021-05-12 上传
2021-05-12 上传

余青葭
- 粉丝: 44
- 资源: 303
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
