GPU并行计算:Fermi架构与CUDA编程
需积分: 9 191 浏览量
更新于2024-07-29
收藏 2.86MB PDF 举报
"GPU应用技术,讲解了GPU在并行计算中的重要性,以及CUDA编程模型和GPU硬件架构,特别是新一代Fermi GPU的特点。内容包括GPU存储结构、CUDA编程基础和优化,对比了GPU与CPU在计算能力和存储带宽上的差异。"
本文将深入探讨GPU(图形处理器)在现代计算领域中的应用技术和其背后的原理,特别是在并行计算方面的重要角色。随着摩尔定律的局限性逐渐显现,传统的微处理器提升性能的方式受到限制,而GPU由于其独特的并行计算能力,仍有巨大的发展潜力。
并行计算的发展是由于对更高计算性能的需求驱动的。随着计算机科学的进步,我们正逐步迈向ExaScale级别的系统,需要处理百万级甚至更多并发线程。在这种背景下,GPU成为了并行计算的关键推动者。以AMD的Llano、Intel的Many Integrated Cores和NVIDIA的Fermi为代表的处理器,展示了并行处理单元数量的显著增长。
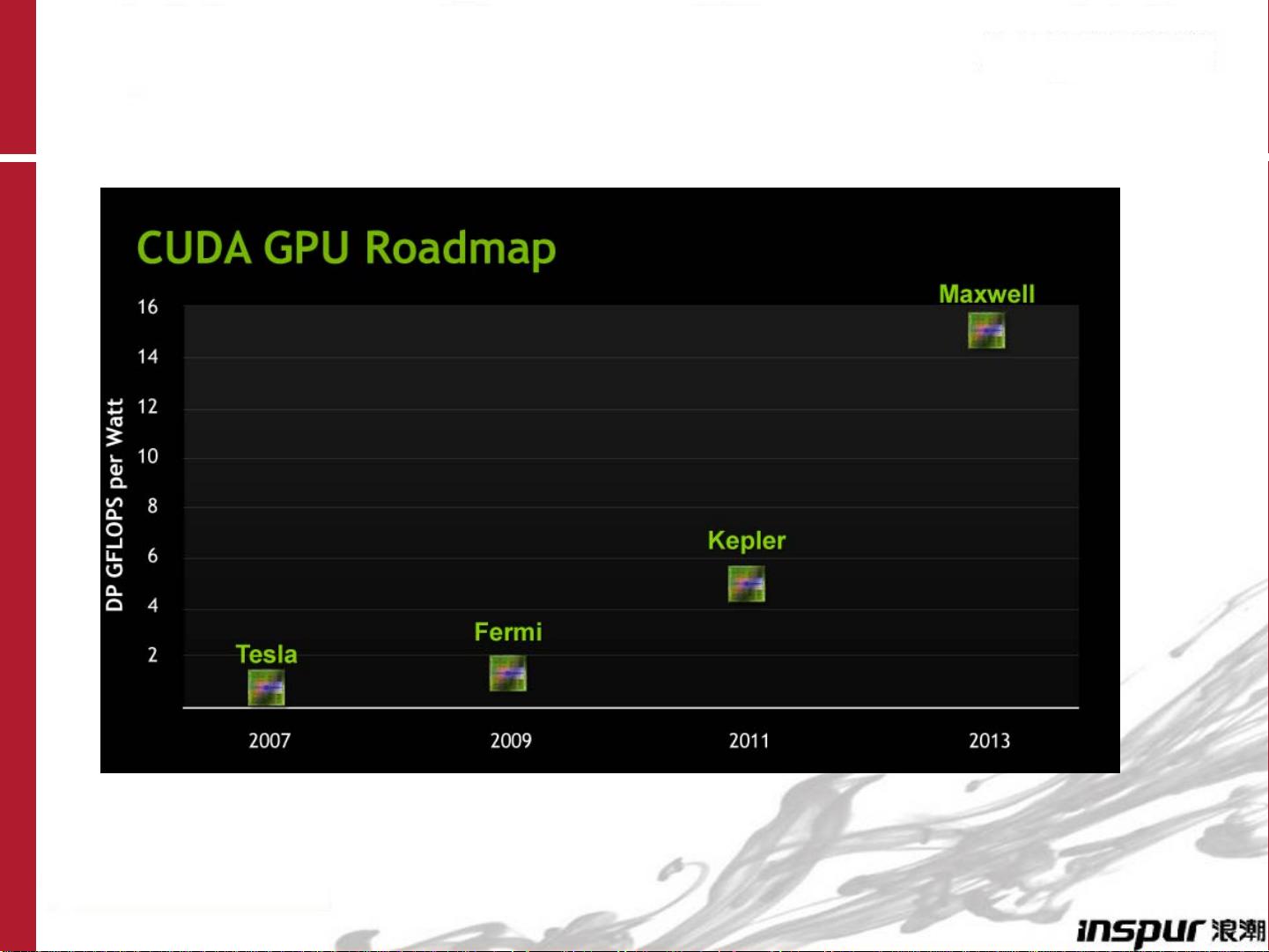
GPU硬件架构,尤其是新一代的Fermi GPU,设计了大量核心来执行并行任务。Fermi架构拥有512个核心,为高性能计算提供了强大的计算能力,接近1Tflops/s的浮点运算速度,以及140GB/s的高带宽内存,这些都是CPU难以匹敌的。GPU的成本效益和能效比也远超CPU,使得GPU在科学计算、深度学习、图像处理等领域广泛应用。
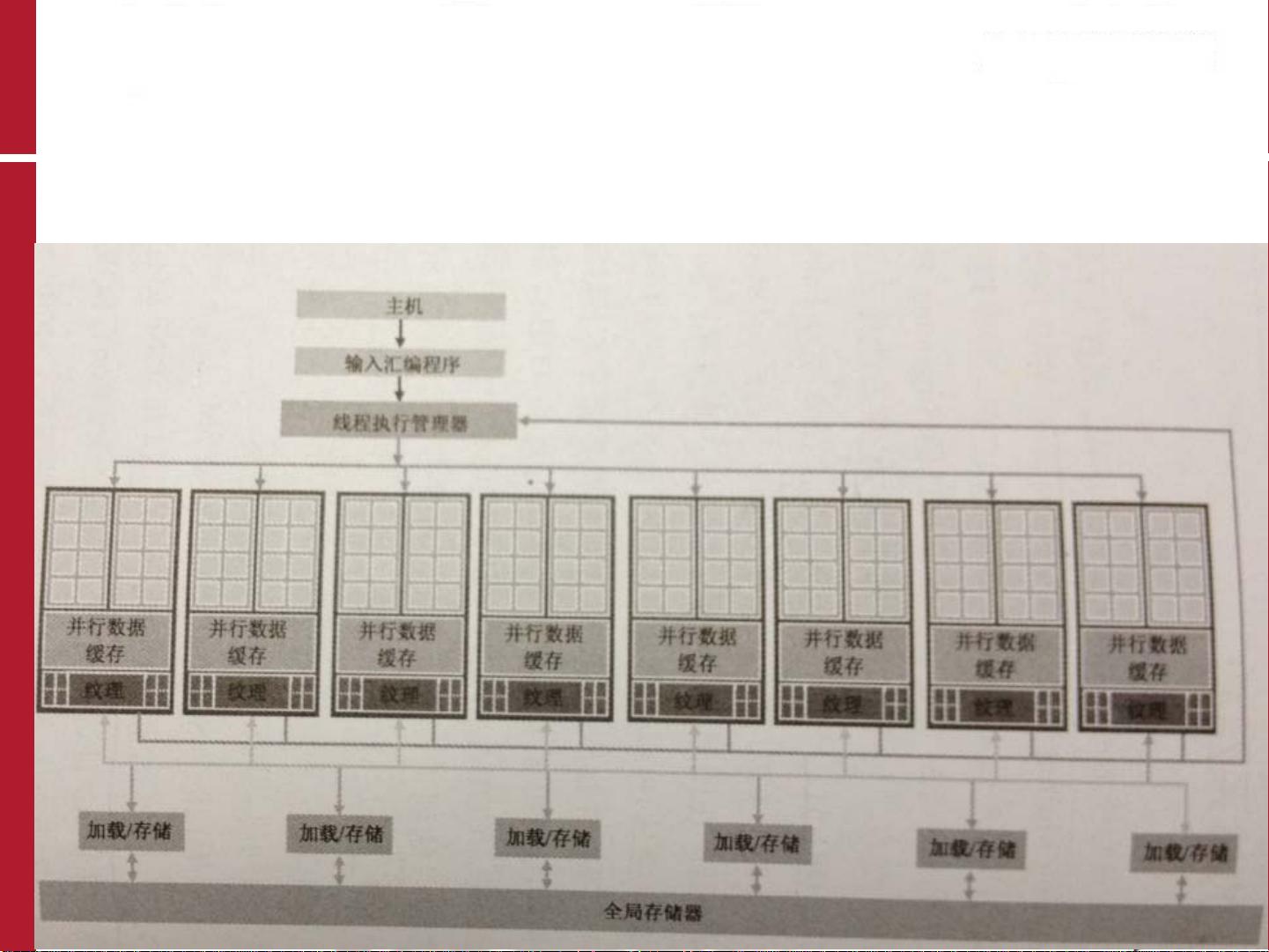
CUDA(Compute Unified Device Architecture)是NVIDIA开发的一种并行计算平台和编程模型,它允许程序员利用GPU的强大计算能力。CUDA的基础包括编程模型,如线程块和网格,以及如何编写CUDA程序,涉及CUDA内核函数和设备内存管理。CUDA编程也涉及到优化,例如理解内存层次结构以减少访问延迟,以及有效利用流式多处理器(SMs)以提高吞吐量。
对比GPU与CPU,虽然CPU具有大缓存来保证线程访问的低延迟,但GPU在并行处理的吞吐量上具有显著优势。CPU通常更适合于低延迟、高响应性的任务,而GPU则在大数据集的并行处理中表现出色,如大规模矩阵运算和物理模拟。
GPU应用技术不仅揭示了GPU在并行计算中的优势,还提供了CUDA编程的基础知识,这对于理解和利用GPU计算潜力至关重要。随着技术的不断发展,GPU将继续在高性能计算和数据密集型应用中扮演重要角色。


254 浏览量
120 浏览量
点击了解资源详情
2021-03-01 上传
370 浏览量
101 浏览量
2022-08-03 上传
2021-09-25 上传

espn1989
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Struts入门教程:从配置到实战
- Linux操作系统常用命令详解
- Struts入门:构建helloapp应用详解
- JavaMail API入门教程:发送与接收邮件
- Boson NetSim教程:静态路由与缺省路由配置实战
- BosonNetSim教程:Cisco设备模拟与实验环境搭建
- MATLAB图像处理命令概览:从applylut到bweuler
- O'Reilly《C#编程(第2版)》:入门与.NET框架详解
- Delphi单元测试工具DUnit详解与配置
- 创建JSP彩色验证码图像的方法
- WinSock网络编程:TCP/IP接口与应用
- 清华大学出版社《JAVA语言入门》
- C++/C编程最佳实践指南
- Div+CSS布局全攻略:从入门到高级实战
- Java Socket编程基础教程
- 面向对象设计模式:复用与灵活性的关键
