强化学习深度解析:MDPs, DP与非模型预测方法
需积分: 10 115 浏览量
更新于2024-07-16
收藏 12.57MB PDF 举报
强化学习(Reinforcement Learning, RL)是机器学习领域的一个重要分支,它借鉴了心理学中的行为主义理论,关注智能体如何通过与环境的交互,根据环境提供的奖励或惩罚信号,学习并优化其行为策略,以最大化长期累积的奖励。David Silver的讲座深入浅出地介绍了强化学习的基本概念和关键原理。
首先,讲座1涵盖了强化学习的简介,包括问题定义、奖励机制、环境的构成以及智能体(agent)的内部结构。在RL中,智能体需要通过策略(Policy)来选择行动,同时利用价值函数(Value function)评估不同状态下采取不同行动的价值。模型(Model)在某些情况下可以帮助预测环境的响应,但并非所有强化学习方法都依赖于模型。
探索与利用(Exploration and Exploitation)是RL中的一个重要平衡,即在寻求新信息(探索)以扩大知识面和利用已知策略获取最大回报(利用)之间做出决策。这两个方面共同驱动了学习和规划的过程。
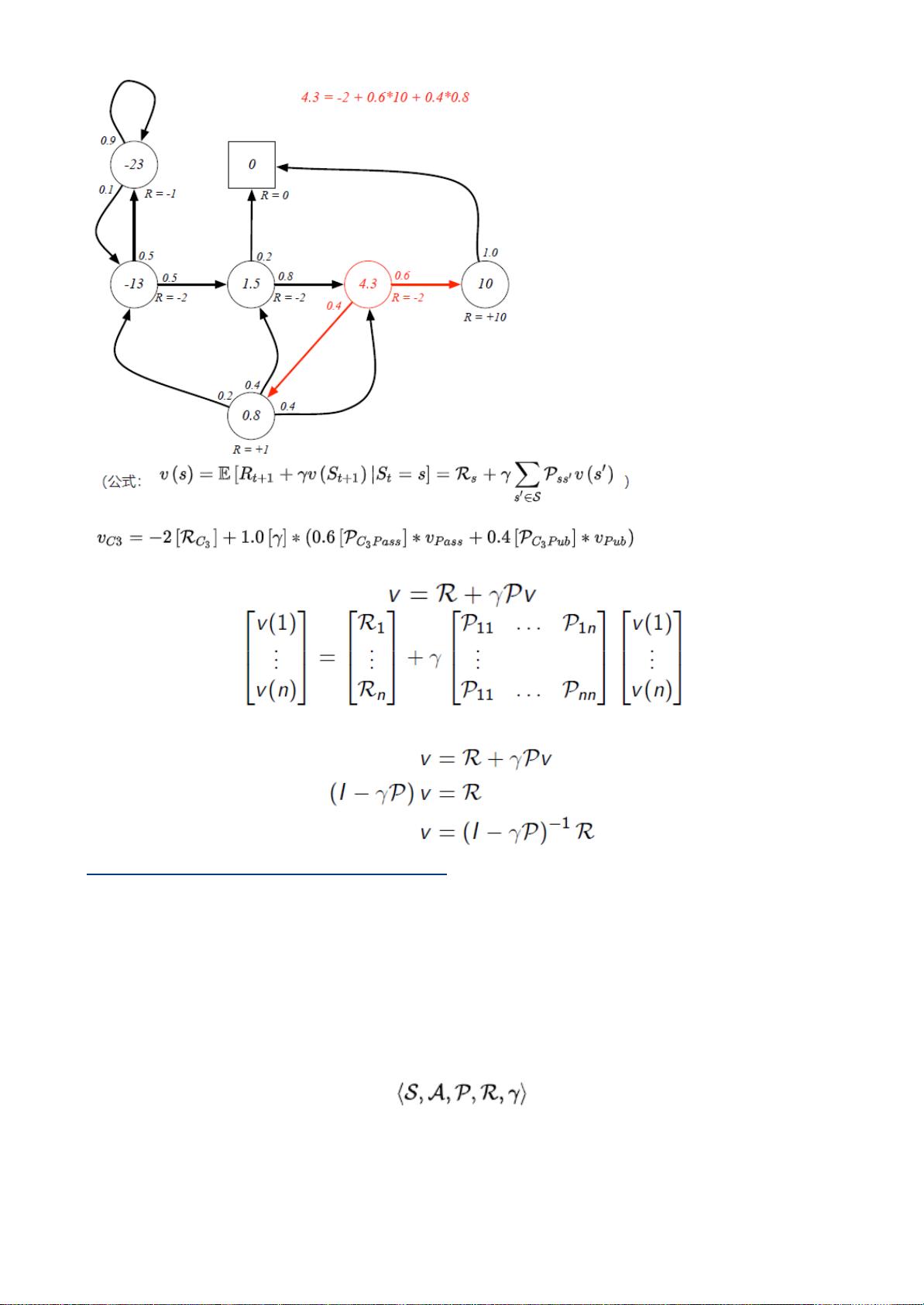
Lecture2深入探讨了马尔可夫决策过程(Markov Decision Processes, MDPs),这是RL的核心概念。马尔可夫性确保了未来状态只依赖于当前状态,而与过去的动作无关。马尔可夫链和马尔可夫奖励过程(Markov Reward Process, MRP)为理解RL问题提供了数学基础。价值函数,如贝尔曼方程(Bellman Equation),用于计算策略的价值,并通过 Bellman期望方程和最优方程来指导决策。
动态规划(Dynamic Programming, DP)在Lecture3中被详细讨论,它是解决MDPs的有效方法。包括策略评价、迭代策略改进(如Policy Iteration和Value Iteration)在内的方法,通过递归地更新值函数,逐步逼近最优解。扩展到动态规划的方法,如异步动态规划、近似动态规划以及压缩映射定理,展示了理论的灵活性和适应性。
接下来的讲座转向不基于模型的学习,如Monte-Carlo Reinforcement Learning(Mnih等人的Deep Q-Networks, DQN),它采用模拟和随机采样来估计值函数。Temporal-Difference Learning(TD Learning)则强调了从即时反馈中学习的重要性,通过分步和λ返回来改进学习效率。这一部分还讨论了TD学习的不同形式,如TD(λ)、n步TD和其前瞻性与回顾性的视角。
David Silver的强化学习讲座内容丰富,从基础概念到核心算法,再到高级策略,为理解这个复杂且强大的机器学习方法提供了全面的框架。学习者可以从中掌握强化学习的关键原理和实践技巧,从而在实际应用中实现智能体的自主学习和决策优化。
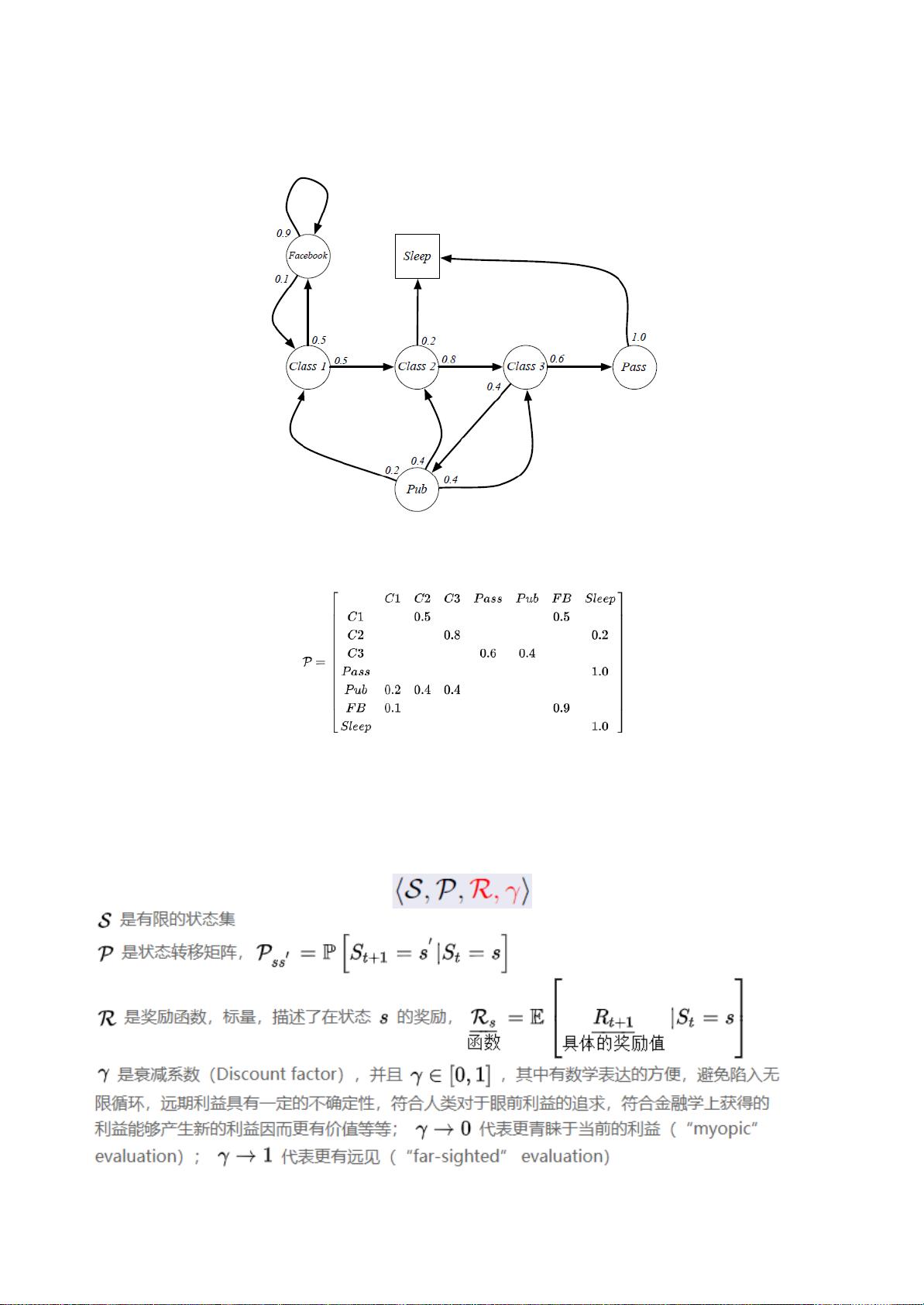
如果一个任务会没有终止状态,会被无限执行下去,这被称为连续性任务(continuing
task)。
例:
圆圈表示学生所处的状态,方格Sleep是一个终止状态,或者可以描述成自循环的状态,也就是Sleep状态的下一个状态
100%的几率还是自己。箭头表示状态之间的转移,箭头上的数字表示当前转移的概率。
马尔科夫过程的状态转移矩阵:
MarkovRewardProcess
马尔科夫奖励过程(MarkovRewardProcess,MRP)
MRP是带有values的MarkovChain
返回(Return)

剩余73页未读,继续阅读
220 浏览量
181 浏览量
253 浏览量
238 浏览量
253 浏览量
199 浏览量

小王曾是少年
- 粉丝: 1w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- HTC G22刷机教程:掌握底包刷入及第三方ROM安装
- JAVA天天动听1.4版:证书加持的移动音乐播放器
- 掌握Swift开发:实现Keynote魔术移动动画效果
- VB+ACCESS音像管理系统源代码及系统操作教程
- Android Nanodegree项目6:Sunshine-Wear应用开发
- Gson解析json与网络图片加载实践教程
- 虚拟机清理神器vmclean软件:解决安装失败难题
- React打造MyHome-Web:公寓管理Web应用
- LVD 2006/95/EC指令及其应用指南解析
- PHP+MYSQL技术构建的完整门户网站源码
- 轻松编程:12864液晶取模工具使用指南
- 南邮离散数学实验源码分享与学习心得
- qq空间触屏版网站模板:跨平台技术项目源码大全
- Twitter-Contest-Bot:自动化参加推文竞赛的Java机器人
- 快速上手SpringBoot后端开发环境搭建指南
- C#项目中生成Font Awesome Unicode的代码仓库
