JMeter工具使用教程:环境搭建与脚本录制
需积分: 10 160 浏览量
更新于2024-07-21
收藏 3.26MB DOCX 举报
"这篇内容主要介绍了如何搭建和使用JMtere工具,包括JMeter环境搭建、脚本录制、数据库连接、检查点设置以及参数化等关键步骤。"
在IT行业中,性能测试是确保软件系统在高负载下稳定运行的重要环节,而JMtere(Apache JMeter)是一款广泛使用的开源性能测试工具,适用于Web应用、FTP服务器、数据库和其他类型的服务器。以下是关于JMtere工具的详细说明:
1. **JMeter环境搭建**:
- 首先,需要获取JMeter的安装包,可以从官方源或指定共享文件夹中下载。
- 接着,确保系统已经安装了兼容的JDK,例如JDK 1.6.0_10。安装时可以自定义路径,例如D:\ProgramFiles\Java。
- 配置JDK环境变量,新建CLASSPATH和JAVA_HOME,指定JDK的lib目录和bin目录。
- 安装JMeter,将压缩包解压到指定位置,如C:\jakarta-jmeter-2.3.4,并创建系统变量JMETER_HOME指向JMeter的根目录。
- 最后,更新系统环境变量中的CLASSPATH,加入JMeter相关的jar文件,同时确保PATH包含%JAVA_HOME%\bin和%JMETER_HOME%\bin。
2. **脚本录制**:
- JMeter提供两种脚本录制方式:直接通过JMeter和使用第三方工具BadBoy。
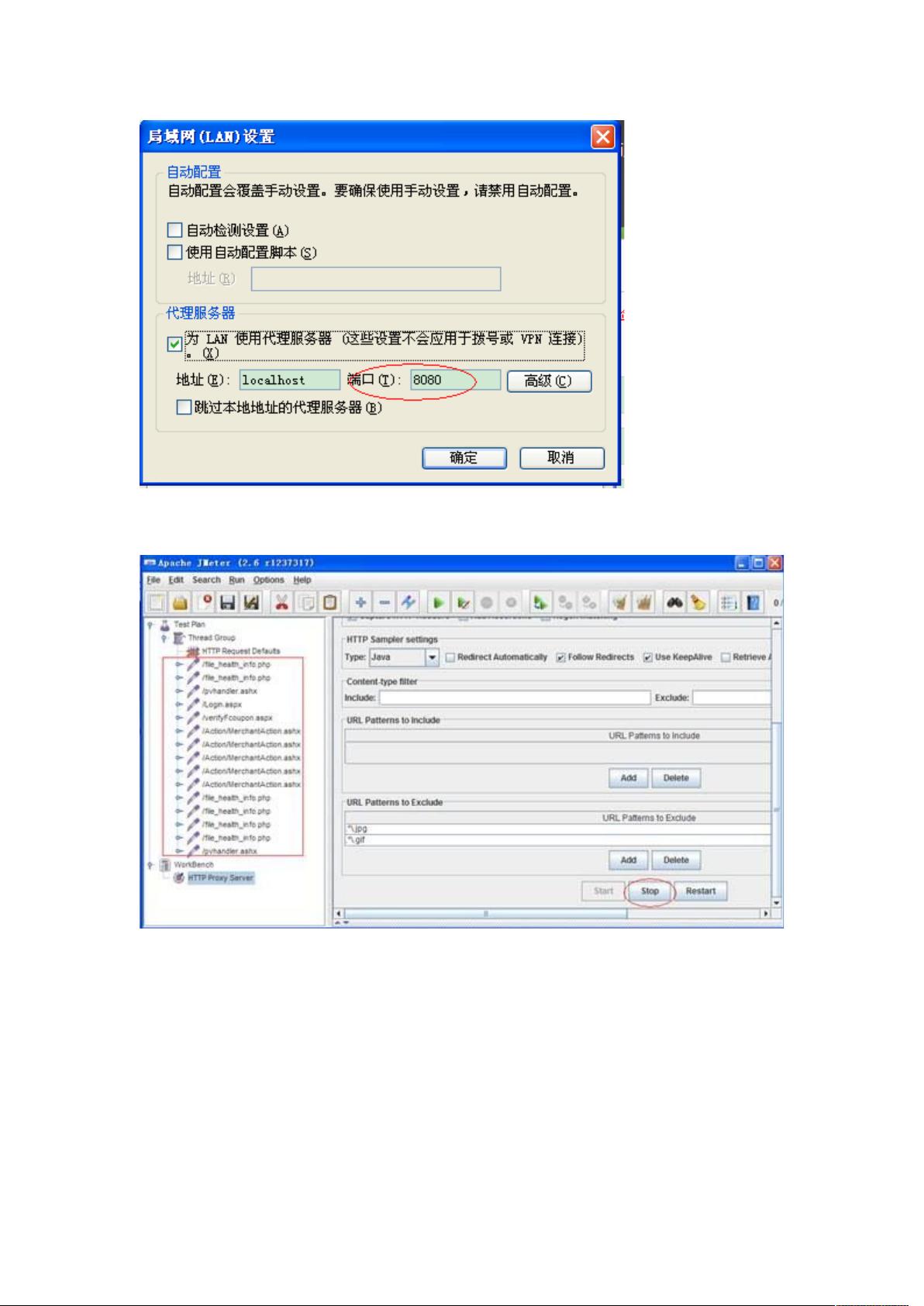
- 使用JMeter录制,需要配置代理服务器,通过JMeter的HTTP(S) Test Script Recorder组件监听网络请求。首先,设置浏览器的代理为JMeter的代理端口,然后执行需要录制的操作。完成后,停止录制,JMeter会生成对应的HTTP请求脚本。
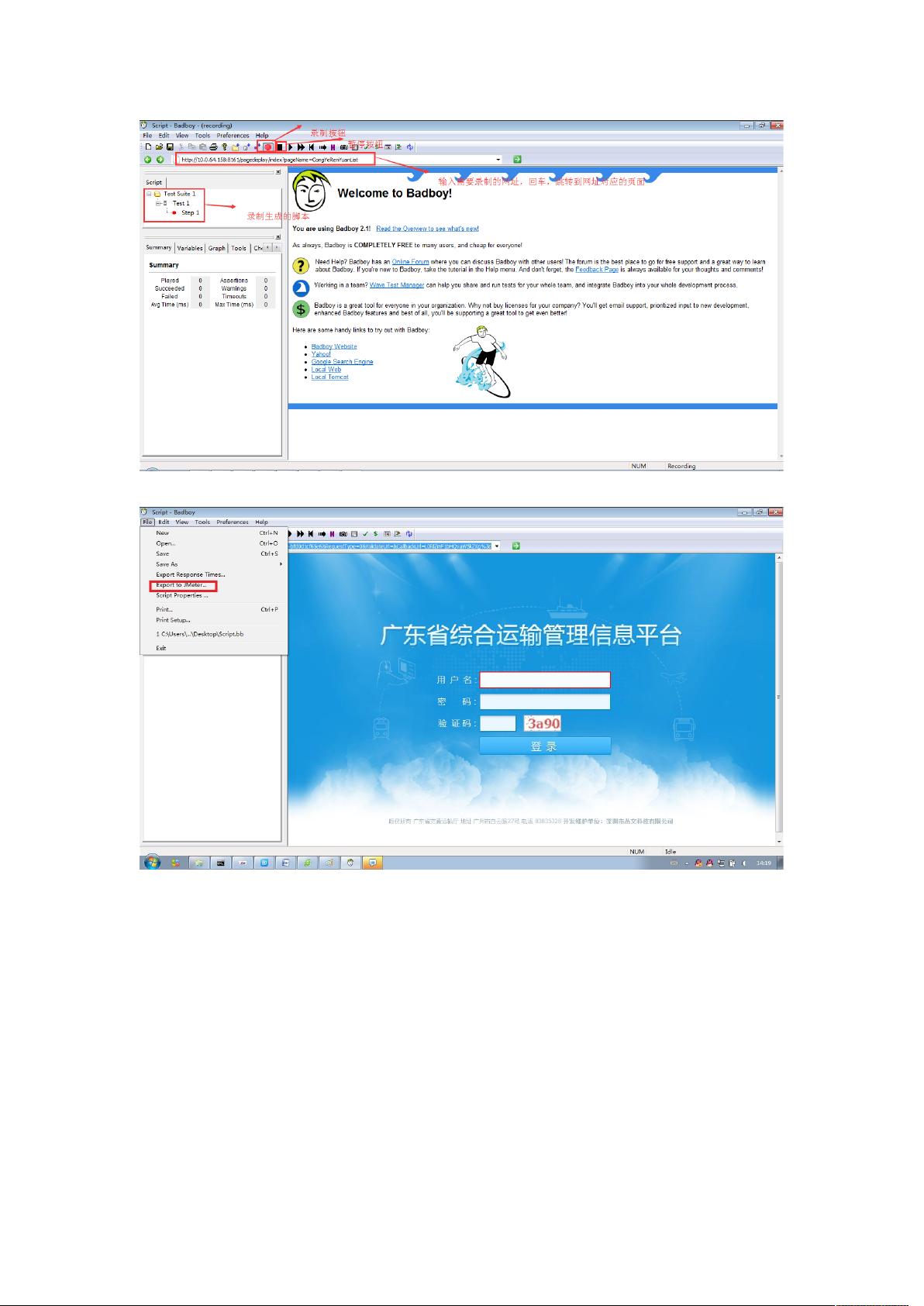
- BadBoy工具录制更为直观,它能直接记录用户在浏览器中的操作,然后导出为JMeter脚本。
3. **数据库连接**:
- 在JMeter中,可以使用JDBC Connection Configuration元件建立与数据库的连接,输入数据库驱动类名、URL、用户名和密码等信息。
- 之后,可以通过JDBC Request元件发送SQL查询或更新命令,对数据库进行操作并验证结果。
4. **检查点设置**:
- 检查点用于验证测试过程中的预期结果,例如,响应数据是否符合预期、页面加载时间是否在可接受范围内等。
- 在JMeter中,可以使用Response Assertion来设置检查点,根据响应数据的文本、正则表达式或其他标准进行匹配验证。
5. **参数化**:
- 参数化是性能测试中的重要概念,它允许用变量替换静态值,模拟不同用户的行为。
- JMeter提供CSV Data Set Config元件来读取CSV文件中的数据,将每行数据作为参数传递给测试计划,实现数据驱动测试。
了解和掌握这些基本操作后,可以进一步探索JMeter的高级特性,如分布式测试、聚合报告分析、断言设置、模块控制器、逻辑控制器等,以满足更复杂的性能测试需求。JMeter的灵活性和强大功能使其成为测试人员的得力工具,能够有效地评估系统在压力条件下的性能和稳定性。
剩余36页未读,继续阅读
2023-08-23 上传
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传

jiangcna
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 2009年java最新面试题
- Graphical Models, Exponential Families, and Variational Inference
- 计算机外文 计算机专业
- C# 如何判断一个Byte数组中是否存在某些连续的数据).txt
- unix常用命令有助于日常工作的小贴士
- C# 的类型转换.doc
- 华为笔试面试指南有兴趣的可以好好看
- service 天气预报
- 城市生活垃圾逆向物流网络优化设计
- C#编码规范,共享参考
- Ext 的中文手册PDF
- A Multiresolution Image Segmentation Technique Based on Pyramidal Segmentation and Fuzzy Clustering
- 图书管理系统SQL数据库
- C#完全手册.pdf
- 工作流原理及实例说明
- java从基础到应用编程经验
