NoSQL数据库分布式算法详解:一致性、数据放置与对等系统
160 浏览量
更新于2024-08-31
收藏 873KB PDF 举报
"深入解析NoSQL数据库的分布式算法,包括数据一致性、数据放置和对等系统等关键策略。本文旨在帮助读者理解如何在NoSQL环境中平衡一致性和可用性,以及优化数据分布和故障处理机制。"
在NoSQL数据库的分布式算法中,首要关注的是数据一致性,这是确保系统正确运行的基础。在分布式系统中,由于网络延迟或分区可能导致CAP理论的挑战,即无法同时保证一致性、可用性和分区容忍性。为了解决这个问题,NoSQL数据库通常会采用各种复制策略来平衡一致性与可用性。
1. 数据一致性:复制是保持数据一致性的核心方法。它包括主从复制和多活复制等模式,允许数据在多个节点间同步。在面临网络分区时,系统可能选择牺牲部分可用性以保证一致性,例如采用Paxos或Raft等一致性协议。同时,系统需要处理写操作的冲突解决和读操作的版本控制,以确保在不同节点上的数据最终达到一致。
2. 数据放置:为了优化性能和应对故障,NoSQL数据库需要智能地管理数据在集群中的分布。这涉及数据分区(Sharding)、哈希分布和地理位置感知等策略。数据分区使得大规模数据集可以分割成更小、更易管理的部分,每个部分存储在不同的节点上。合理的数据分布能确保查询效率,同时确保在节点故障时能快速恢复服务,保持数据持久化。
3. 对等系统:在对等网络中,没有中心节点,所有节点地位平等,需要通过选举算法确定领导者,如Gossip协议和Leader Election算法,来处理故障检测和状态同步。对等系统的设计目标是使系统能够自我修复,即使有节点失效,也能保持服务的连续性和一致性。
此外,为了提高系统的读写性能和扩展性,NoSQL数据库常常采用读写分离、负载均衡等技术,将读压力分散到多个副本,而写操作集中在主节点上。这样既保证了高可用性,又能在一定程度上降低了延迟。
NoSQL数据库的分布式算法是其在大规模数据处理中保持高效和可靠的关键。通过理解并实施这些策略,开发者可以构建出适应复杂业务场景、具有高扩展性和容错性的数据库系统。
划外的不一致。Cassandra就使用了反熵算法来在各节点之间传递数据库拓扑和其他一些元数据信息。
一致性保证较弱:即使在没有发生故障的情况下,也会出现写冲突与读写不一致。
在网络隔离下的高可用和健壮性。用异步的批处理替代了逐个更新,这使得性能表现优异。
持久性保障较弱因为新的数据最初只有单个副本。
((B)) 对上面模式的一个改进是在任意一个节点收到更新数据请求的同时异步的发送更新给所有可用节点。这也被认为是定向对上面模式的一个改进是在任意一个节点收到更新数据请求的同时异步的发送更新给所有可用节点。这也被认为是定向
的反熵。的反熵。
与纯粹的反熵相比,这种做法只用一点小小的性能牺牲就极大地提高了一致性。然而,正式一致性和持久性
保持不变。
假如某些节点因为网络故障或是节点失效在当时是不可用的,更新最终也会通过反熵传播过程来传递到该节
点。
((C)) 在前一个模式中,使用提示移交技术可以更好地处理某个节点的操作失败。在前一个模式中,使用提示移交技术可以更好地处理某个节点的操作失败。对于失效节点的预期更新被记录在额外的代
理节点上,并且标明一旦特点节点可用就要将更新传递给该节点。这样做提高了一致性,降低了复制收敛时间。
((D, 一次性读写)因为提示移交的责任节点也有可能在将更新传递出去之前就已经失效,在这种情况下就有必要通过所谓的一次性读写)因为提示移交的责任节点也有可能在将更新传递出去之前就已经失效,在这种情况下就有必要通过所谓的
读修复来保证一致性。读修复来保证一致性。每个读操作都会启动一个异步过程,向存储这条数据的所有节点请求一份数据摘要(像签名或者
hash),如果发现各节点返回的摘要不一致则统一各节点上的数据版本。我们用一次性读写来命名组合了A、B、C、D的技
术- 他们都没有提供严格的一致性保证,但是作为一个自备的方法已经可以用于实践了。
((E, 读若干写若干)读若干写若干) 上面的策略是降低了复制收敛时间的启发式增强。上面的策略是降低了复制收敛时间的启发式增强。为了保证更强的一致性,必须牺牲可用性来保证一定
的读写重叠。 通常的做法是同时写入W个副本而不是一个,读的时候也要读R个副本。
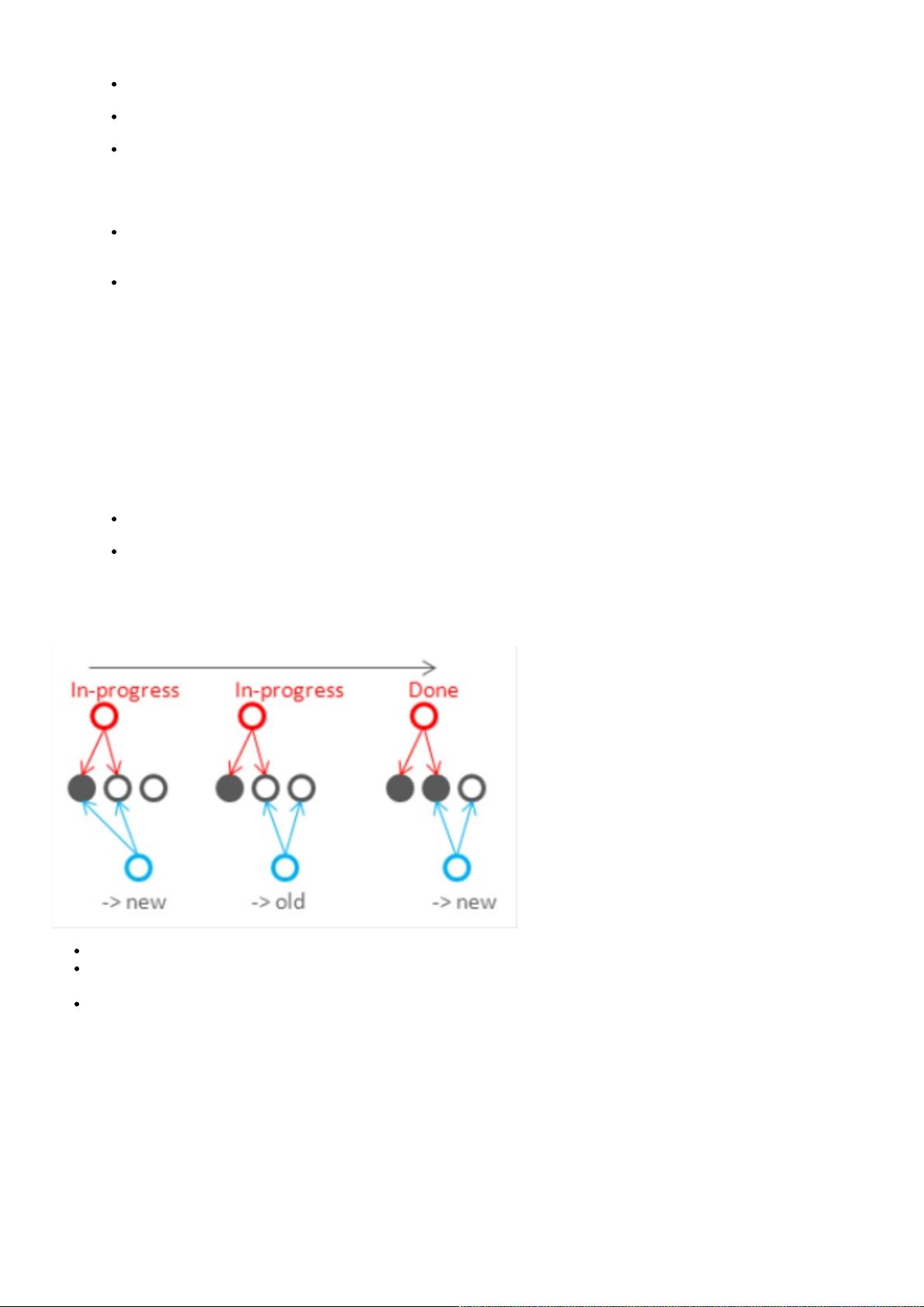
首先,可以配置写副本数W>1。
其次,因为R+W>N,写入的节点和读取的节点之间必然会有重叠,所以读取的多个数据副本里至少会有一
个是比较新的数据(上面的图中 W=2, R=3, N=4 )。这样在读写请求依序进行的时候(写执行完再读)能够
保证一致性(对于单个用户的读写一致性),但是不能保障全局的读一致性。用下面图示里的例子来
看,R=2,W=2,N=3,因为写操作对于两个副本的更新是非事务的,在更新没有完成的时候读就可能读到
两个都是旧值或者一新一旧:
对于某种读延迟的要求,设置R和W的不同值可以调整写延迟与持久性,反之亦然。
如果W<=N/2,并发的多个写入会写到不同的若干节点(如,写操作A写前N/2个,B写后N/2个)。 设置 W>N/2 可以保
证在符合回滚模型的原子读改写时及时检测到冲突。
严格来讲,这种模式虽然可以容忍个别节点的失效, 但是对于网络隔离的容错性并不好。在实践中,常使用”近似数量
通过“这样的方法,通过牺牲一致性来提高某些情景下的可用性。
((F, 读全部写若干)读一致性问题可以通过在读数据的时候访问所有副本(读数据或者检查摘要)来减轻。读全部写若干)读一致性问题可以通过在读数据的时候访问所有副本(读数据或者检查摘要)来减轻。这确保了只要有
至少一个节点上的数据更新新的数据就能被读取者看到。但是在网络隔离的情况下这种保证就不能起到作用了。
((G, 主从)主从) 这种技术常被用来提供原子写或者这种技术常被用来提供原子写或者 冲突检测持久级别的读改写。为了实现冲突预防级别,必须要用一种集中管理冲突检测持久级别的读改写。为了实现冲突预防级别,必须要用一种集中管理
方式或者是锁。方式或者是锁。最简单的策略是用主从异步复制。对于特定数据项的写操作全部被路由到一个中心节点,并在上面顺序执行。
这种情况下主节点会成为瓶颈,所以必须要将数据划分成一个个独立的片区(不同片有不同的master),这样才能提供扩展
性。
((H, Transactional Read Quorum Write Quorum and Read One Write All)) 更新多个副本的方法可以通过使用事务控制更新多个副本的方法可以通过使用事务控制
技术来避免写冲突。技术来避免写冲突。 众所周知的方法是使用两阶段提交协议。但两阶段提交并不是完全可靠的,因为协调者失效可能会造成
资源阻塞。 PAXOS提交协议是更可靠的选择,但会损失一点性能。 在这个基础上再向前一小步就是读一个副本写所有副本,
这种方法把所有副本的更新放在一个事务中,它提供了强容错一致性但会损失掉一些性能和可用性。
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-03-02 上传
2021-01-30 上传
2013-06-01 上传
点击了解资源详情
2024-08-28 上传
点击了解资源详情

weixin_38528680
- 粉丝: 8
- 资源: 875
 我的内容管理
展开
我的内容管理
展开







最新资源
- 西门子PLC工程实例源码第645期:连接S7-300到S7-200通过PROFIBUS程序.rar
- 数独递归:实现了递归回溯数独求解算法
- disaster-response
- psi3862015:PSI3862015专题制作
- 没得比 实时推送-crx插件
- MMM-MP3Player:一个MagicMirror模块,用于在插入USB随身碟后立即播放音乐
- carGamePerceptron:涉及JavaScript游戏的神经网络实验
- 时尚城购物比价助手-crx插件
- simple-resto-app
- Paw-JSONSchemaFakerDynamicValue:在Paw中为JSON模式生成伪造的值
- 西门子PLC工程实例源码第644期:连接S7-200(主站)到多个S7-200(从站)通过GSM MODEM程序.rar
- FFMPEG_RTMP协议_收流_推流
- onejava01:第一次提交到远程仓库
- osadmin开源管理后台 v2.1.0
- MyEasy86-crx插件
- 课程-cristianmoreno
