Hadoop MapReduce:大数据处理的关键框架
需积分: 11 142 浏览量
更新于2024-07-17
收藏 45.41MB DOC 举报
本文档深入探讨了大数据技术中的关键组件Hadoop及其MapReduce模型。首先,MapReduce被定义为一个分布式运算程序的编程框架,专为在Hadoop集群上实现高效、可扩展的大数据分析应用而设计。它简化了开发者的工作,允许他们专注于业务逻辑,而将复杂的分布式计算任务交给框架处理。
1.1 MapReduce的必要性:
- 面对单机处理能力的局限性,大数据量超出了硬件资源的承载,MapReduce提供了解决方案,通过将任务分解到集群节点上并行执行,解决了数据处理的性能瓶颈。
- 分布式运行会带来复杂性和开发难度的提升,MapReduce框架通过抽象出公共功能,如任务切分、启动协调和错误处理,降低了开发者面对这些挑战的负担。
1.2 MapReduce的核心思想:
- MapReduce设计为两个主要阶段:Map阶段和Reduce阶段。Map阶段类似于预处理,将输入数据拆分并转换为更易处理的形式,而Reduce阶段则是对Map阶段的结果进行汇总和聚合。这种设计确保了数据在不同阶段的独立处理,提高了并行处理效率。
1.3 MapReduce进程结构:
- MapReduce程序在运行时包括MrAppMaster(应用程序主进程),负责全局调度和状态管理。
- MapTask负责每个数据块的映射操作,它们独立执行且相互间没有依赖。
- ReduceTask则在所有MapTask完成之后启动,接收并处理来自所有Map阶段的结果,完成最终的汇总。
1.4 MapReduce编程规范:
- 编程时,开发者必须遵循一定的规则,如每个程序仅包含一个Map阶段和一个Reduce阶段,除非业务逻辑非常复杂,否则需使用多个MapReduce程序串联执行。
Hadoop MapReduce是一种强大的工具,它通过明确的任务划分、并行执行以及自动化的错误处理机制,极大地推动了大数据处理的效率和可扩展性。理解并掌握MapReduce原理对于大数据工程师来说至关重要,它不仅限于Hadoop平台,也适用于其他分布式计算环境中的复杂数据处理场景。

尚硅谷大数据技术之 Hadoop(MapReduce)
—————————————————————————————
()改写 ,实现一次读取一个完整文件封装为
()在输出时使用 4Q(8)BK8 输出合并文件
)案例实操
详见 % 小文件处理(自定义 7(8)。
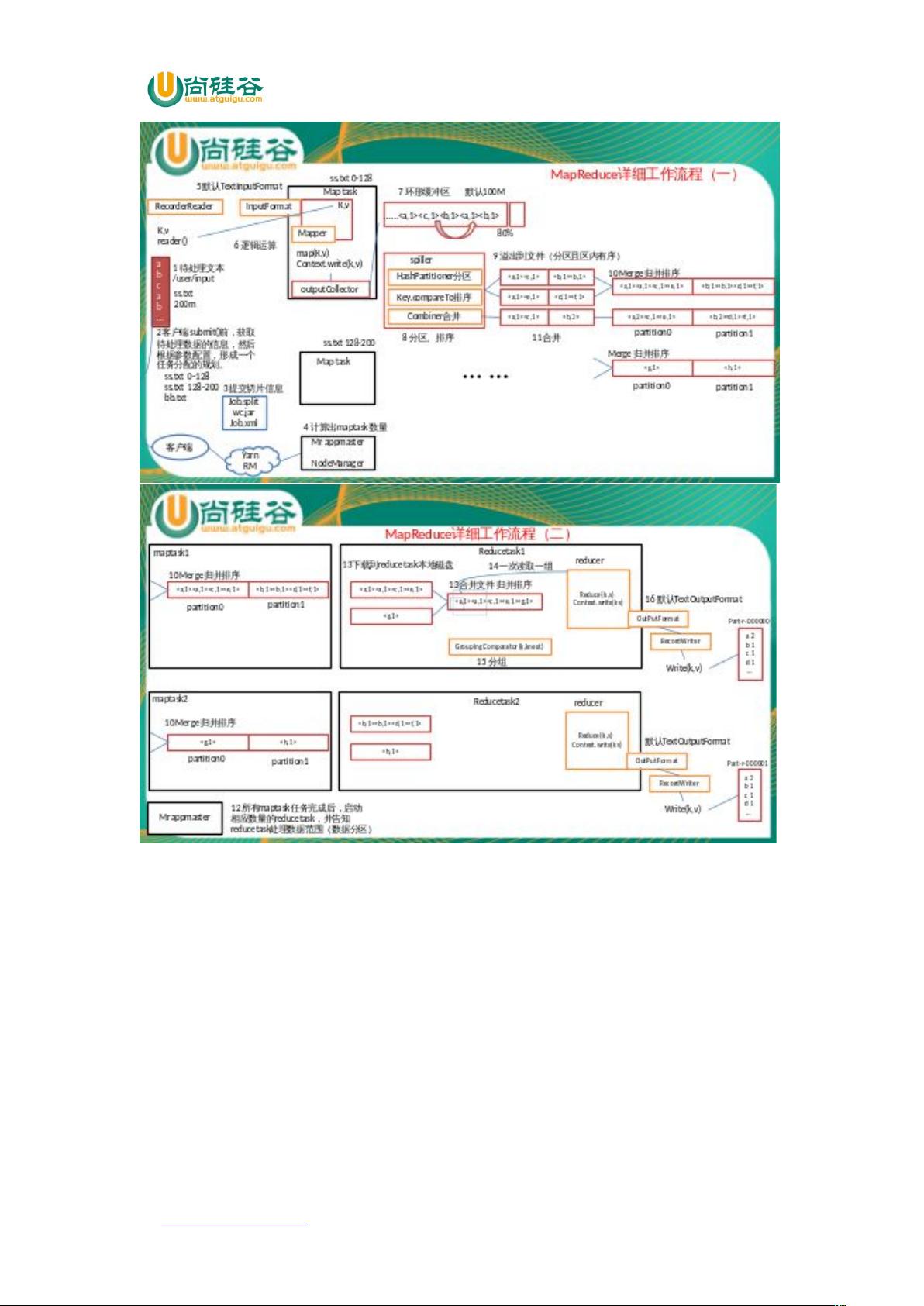
2.3 MapTask 工作机制
)问题引出
的并行度决定 阶段的任务处理并发度,进而影响到整个 #$ 的处理速度。
那么, 并行任务是否越多越好呢?
) 并行度决定机制
一个 #$ 的 阶段 并行度(个数),由客户端提交 #$ 时的切片个数决定。
) 工作机制
() 阶段: 通过用户编写的 ,从输入 7(4) 中解析出
一个个 +<)。
() 阶段:该节点主要是将解析出的 +<) 交给用户编写 函数处理,并
产生一系列新的 +<)。
()')) 阶段 :在 用户 编写 函数中,当 数据处理完成后,一 般 会调用
B'))%))输出结果。在该函数内部,它会 将生成的 +<) 分区(调用
K(),并写入一个环形内存缓冲区中。
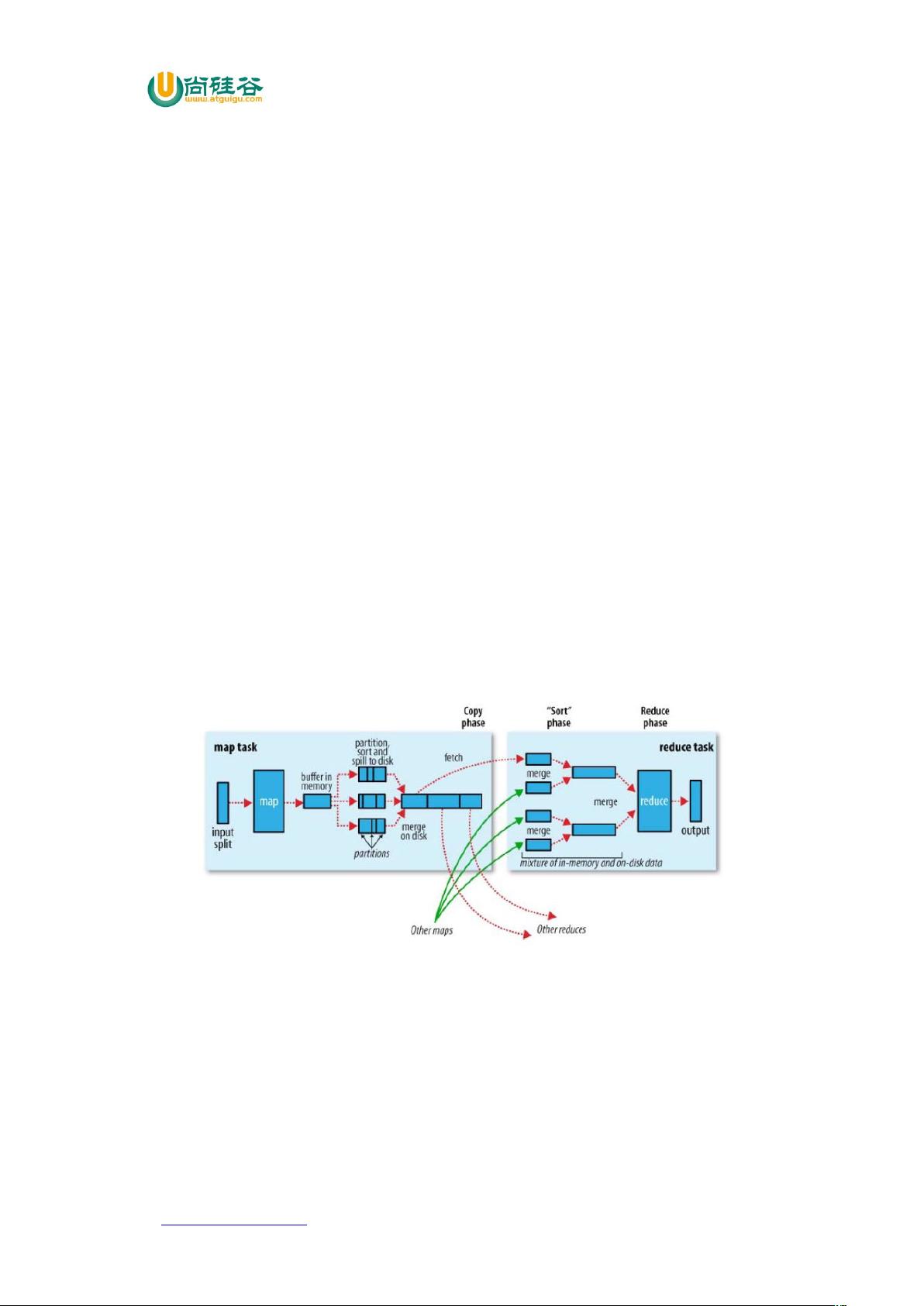
()4)) 阶段:即“溢写”,当环形缓冲区满后, 会将数据写到本地磁盘上,
生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地
排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
步骤 :利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编
号 ( 进行排序,然后按照 + 进行排序。这样,经过排序后,数据以分区为单位聚
集在一起,且同一分区内所有数据按照 + 有序。
步骤 :按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时
文件 <))L%(L 表示当前溢写次数)中。如果用户设置了 '$(,则写入文件
之前,对每个分区中的数据进行一次聚集操作。
步骤 :将分区数据的元信息写到内存索引数据结构 4)) 中,其中每个分区的
【更多 Java、HTML5、Android、python、大数据 资料下载,可访问尚硅谷(中国)官
网 www.atguigu.com 下载区】
剩余63页未读,继续阅读
2021-08-11 上传
2022-11-24 上传
2022-10-31 上传
2020-09-15 上传
2019-05-19 上传
2021-08-11 上传

生命如歌啊
- 粉丝: 2
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
