现代列式数据库系统设计与实现综述
需积分: 10 154 浏览量
更新于2024-07-17
收藏 1.81MB PDF 举报
本文是一篇深入探讨现代列式数据库系统设计与实现的研究综述,主要关注于近年来随着大数据分析查询兴起而复兴的列存储技术。列存(column-oriented)数据库系统,如MonetDB [46]、VectorWise [18] 和 C-Store [88],其核心思想是将表中的每个属性独立存储在存储的不同文件或区域,以优化对特定列的扫描和聚合操作。这种设计的优势在于能够直接访问查询所需的列,减少I/O开销。
文章首先回顾了列存储的历史和趋势,指出这类数据库系统在应对大数据分析场景时展现出的优势。作者提到,尽管传统的关系型数据库(RDBMS)在灵活性和事务处理上占据优势,但列存储通过压缩、延迟加载等技术,在处理大规模数据集上的查询性能上具有显著提升。
接下来,文章详细介绍了三个关键研究原型的设计特点:
1. **C-Store**:它可能是最早的商业化列存储系统之一,强调了高效的数据组织和查询优化,以及可能采用的适应性索引(database cracking),即根据查询模式动态调整数据布局。
2. **MonetDB** 和 **VectorWise**:这两者都是基于列式存储的代表,但有各自的技术特色。MonetDB以元组和列并行处理闻名,而VectorWise则专注于向量化处理,通过并行计算加速查询执行。
3. **其他实现**:除了上述提到的系统,还有其他商业和开源列存储产品,它们可能在特定领域如分区策略、分布式处理等方面有所创新。
在内部技术和高级技术部分,文章深入解析了列存储的各个方面:
- **矢量化处理**(Vectorized Processing):通过一次性处理大量数据,减少了中间步骤,提高了查询效率。
- **压缩**:为了节省存储空间和提高I/O效率,列存储系统通常会使用压缩算法来减小数据的物理大小。
- **直接操作压缩数据**:设计允许系统在无需先解压缩数据的情况下进行计算,进一步提升性能。
- **延迟加载(Late Materialization)**:将数据的计算推迟到实际需要时,可以减少预读取的数据量,适用于只读或低频率更新的场景。
- **JOIN处理**:在列存储中,JOIN操作可能会涉及跨列数据的交互,如何高效地进行这些操作是设计的关键。
- **分组、聚合和算术运算**:列存储优化了这些针对单个列的操作,提供了快速的统计和计算能力。
- **插入/更新/删除(Inserts/Updates/Deletes, IUD)**:处理这些操作时,列存储需要维护数据的一致性和完整性,同时保持查询性能。
- **索引**:适应性索引策略允许系统根据查询模式自动创建或优化索引,提高查询响应速度。
本文提供了一个全面的视角,展示了列存储数据库系统在架构、内部机制以及应对特定查询需求时所采用的关键技术,为理解和比较不同的列式数据库系统提供了深入的洞见。
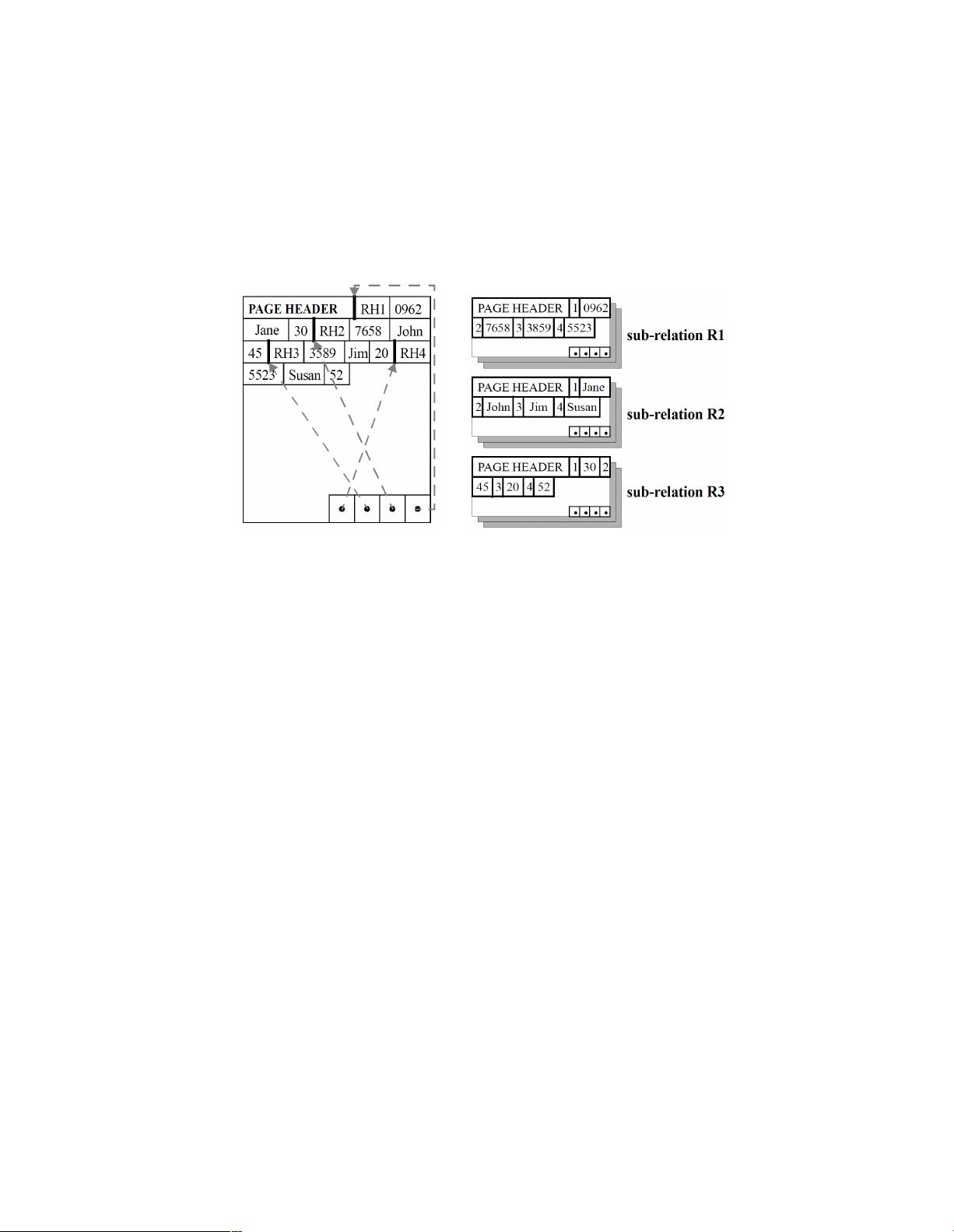
208 History, trends, and performance tradeoffs
NSM Page DSM Pages
Figure 2.1: Storage models for storing database records inside disk pages: NSM
(row-store) and DSM (a predecessor to column-stores). Figure taken from [5].
used to choose compression methods and related parameters.
Research on transposed files was followed by investigations of ver-
tical partitioning as a technique for table attribute clustering. At the
time, row-stores were the standard architecture for relational database
systems. A typical implementation for storing records inside a page
was a slotted-page approach, as shown on the left part of Figure 2.1.
This storage model is known as the N-ary Storage Model or NSM.
In 1985, Copeland and Khoshafian proposed an alternative to NSM,
the Decompos ition Storage Model or DSM–a predecessor to column-
stores [22] (see left part of Figure 2.1). For many, that work marked
the first comprehensive comparison of row- and column-stores. For the
next 20 years, the terms DSM and NSM were more commonly used
instead of row- or column-oriented storage. In the DSM, each column
of a table is stored separately and for each attribute value within a
column it stores a copy of the corresponding surrogate key (which is
similar to a record id or RID), as in Figure 1.1(b). Since surrogate
keys are copied in each column, DSM requires more storage space than
NSM for base data. In addition to storing each column in the same
order as the original table (with a clustered index on surrogate keys),



剩余86页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2010-04-15 上传
2017-11-25 上传
2021-03-19 上传
2019-09-07 上传
2019-08-20 上传
2020-03-21 上传

tianjy1990
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
