B树、B+树、B*树到R树:数据结构解析
需积分: 14 194 浏览量
更新于2024-07-27
收藏 1.05MB DOCX 举报
"这篇文章除了探讨B树、B+树、B*树外,还涉及了R树,这些都是重要的数据结构,特别是在数据库索引和大规模数据存储中的应用。文章作者包括July、weedge、Frankie,由编程艺术室出品,并在July的统稿修订后完成。"
在计算机科学和数据库领域,数据结构的选择对于优化查找效率至关重要。B树、B+树和B*树是为了解决大规模数据存储和检索中遇到的问题而设计的高效数据结构,特别适用于外部存储器如磁盘的情况。
1. B树(B-tree):
B树是一种自平衡的多路搜索树,其特点是所有叶子节点在同一层,且每个节点可以有多个子节点。B树的平衡特性确保了在插入、删除和查找操作后,树的高度保持相对较小,从而降低了磁盘I/O操作的次数。B树的关键性质是所有键值分布在节点之间,使得一次磁盘操作可以访问多个数据项。
2. B+树(B+tree):
B+树是B树的一种变体,增加了以下特点:所有的键都保存在叶子节点中,非叶子节点只用来索引,不存储数据;叶子节点之间通过指针连接,形成一个有序链表,便于遍历所有元素。B+树的设计使得所有的查找操作都会终止于叶子节点,减少了磁盘I/O操作,同时,所有的数据都在叶子节点,方便批量读取。
3. B*树(B*tree):
B*树是B+树的进一步优化,每个节点有更多的指向子节点的指针,减少了节点分裂的概率,因此在同样的数据量下,B*树的平均高度比B+树更低。此外,B*树的非根和非叶子节点也存储关键字,使得更多的数据可以被缓存在内存中,减少了磁盘访问。
4. R树(R-tree):
R树是一种多维空间的索引结构,适用于处理地理信息系统或数据库中的空间数据。与B树等不同,R树用于存储和检索多维坐标点,可以有效地处理高维数据的范围查询和最近邻搜索。R树通过构建矩形区域来包容数据点,通过合并和分割这些矩形来维持树的平衡。
B树家族和R树都是为了在大型数据集上提供高效的数据检索,特别是当数据存储在低速介质如磁盘时。理解并选择合适的数据结构对于优化数据库性能、提高查询效率至关重要。在实际应用中,根据具体需求和场景,开发者需要权衡各种因素,如查询类型、数据分布和存储设备的特性,来选择最佳的数据结构。
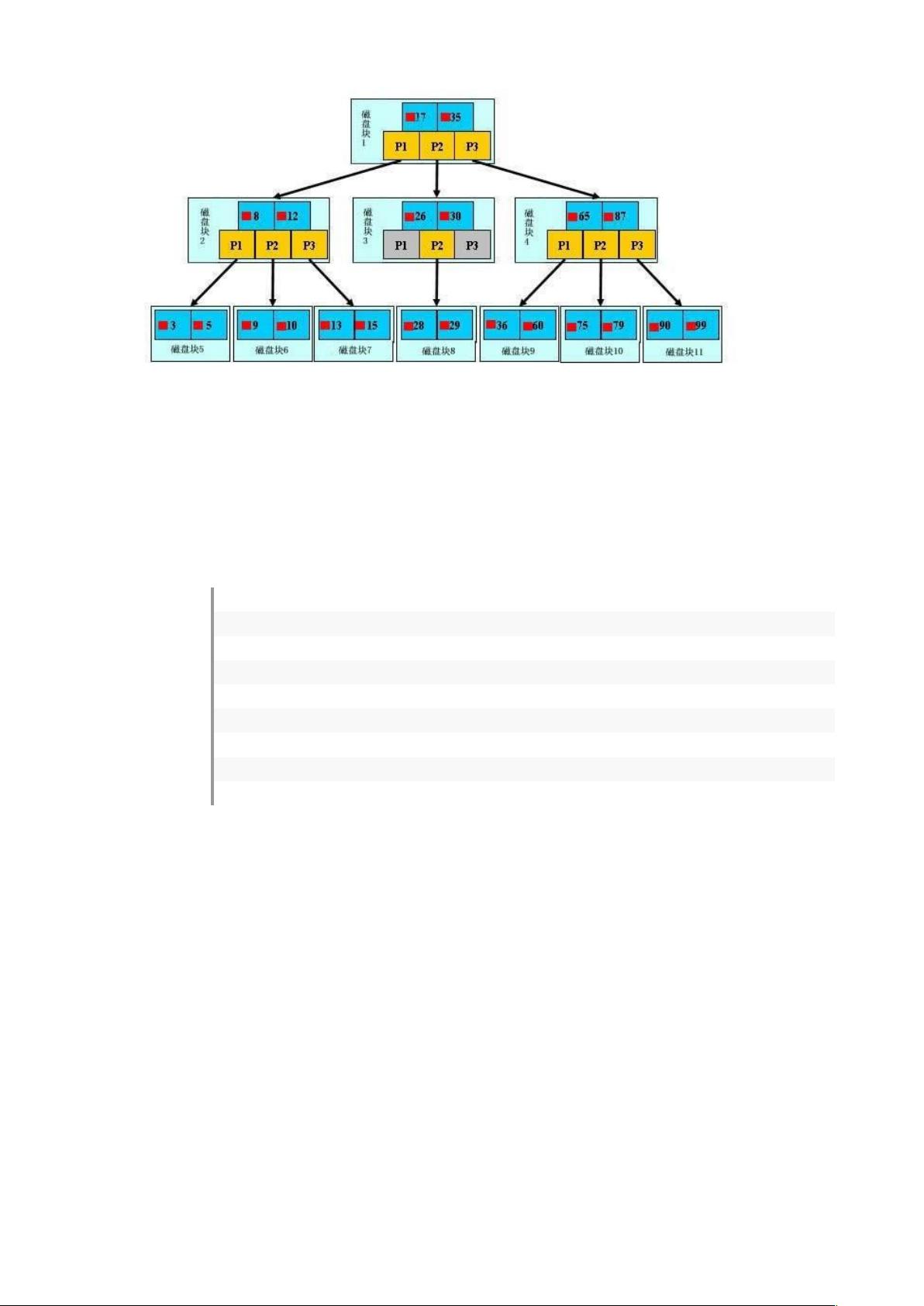
3.3 文件查找的具体过程(涉及磁盘 IO 操作)
为了简单,这里用少量数据构造一棵 ; 叉树的形式,实际应用中的 树结点中关键字很多的。上面的
图中比如根结点,其中 02 表示一个磁盘文件的文件名;小红方块表示这个 02 文件内容在硬盘中的存
储位置;0 表示指向 02 左子树的指针。
其结构可以简单定义为:
0 typedefstructO
* 文件数
; intP7Q
? 文件名&(
> charP7D78P7EQ
< 指向子节点的指针
2 %H%D78P70EQ
@ 文件在硬盘中的存储位置
1 6!-L:9:99RD78P7EQ
假如每个盘块可以正好存放一个 树的结点(正好存放 * 个文件名)。那么一个 %H49- 结点就代表
一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件 *1 的过程:
0 根据根结点指针找到文件目录的根磁盘块 0,将其中的信息导入内存。【磁盘 64 操作ñ0
次】ññññ
* 此时内存中有两个文件名 02、;> 和三个存储其他磁盘页面地址的数据。根据算法我们发现:
02K*1K;>,因此我们找到指针 *。
; 根据 * 指针,我们定位到磁盘块 ;,并将其中的信息导入内存。【磁盘 64 操作ñ* 次】ññññ
? 此时内存中有两个文件名 *<,;3 和三个存储其他磁盘页面地址的数据。根据算法我们发现:
*<K*1K;3,因此我们找到指针 *。
> 根据 * 指针,我们定位到磁盘块 @,并将其中的信息导入内存。【磁盘 64 操作ñ; 次】ññññ
< 此时内存中有两个文件名 *@,*1。根据算法我们查找到文件名 *1,并定位了该文件内存的磁
盘地址。
剩余29页未读,继续阅读
258 浏览量
264 浏览量
2261 浏览量
289 浏览量
MOV+AX,BX+MOV+AX,0304+MOV+AX,[0304]+MOV+AX,[BX]+MOV+AX,[BX+0001]+MOV+AX,[BX+SI]+MOV+AX,[BX+SI+0001],
170 浏览量
253 浏览量
2023-06-02 上传
2023-06-02 上传
2023-06-02 上传
143 浏览量

efeics
- 粉丝: 37
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







