量子学习代理:机器智能揭示量子系统的精确模型
版权申诉
137 浏览量
更新于2024-07-06
收藏 2.09MB PDF 举报
量子模型学习代理(Quantum Model Learning Agent, QMLA)是一种创新的机器学习方法,它在研究领域内具有重要意义,尤其是在处理实际量子系统的精确模型方面。该方法旨在通过模拟实验来逆向工程地分析和重构目标量子系统的哈密顿ian描述,这是一种基础理论工具,用于解释量子系统的动力学行为。
哈密顿ian是量子力学的核心概念,它描述了一个系统的总能量和其组成粒子之间的相互作用。在物理实验中,精确测量哈密顿ian参数对于理解复杂量子现象如超导、量子计算中的量子比特操控以及量子纠缠等至关重要。然而,由于量子系统的非经典性质和实验测量的局限性,直接从实验数据中准确推断出哈密顿ian是一项极具挑战的任务。
QMLA算法巧妙地运用了机器学习的技术,特别是数据驱动的优化策略,通过迭代过程来构建对目标量子系统的概率模型。它结合了统计学习和模拟退火等技术,通过一系列的假设和实验设计,逐步逼近最符合观测结果的潜在量子系统模型。这一过程包括对量子态的测量、模型的拟合、误差评估以及模型更新,形成一个迭代学习的闭环。
测试结果显示,QMLA在模拟实验中展现出了强大的性能。它能够有效地揭示出不同机制如何设计候选哈密顿ian模型,这有助于研究人员理解和控制量子系统的复杂行为。例如,QMLA能够处理多体相互作用、量子退相干效应以及系统间的耦合等问题,这些都是传统方法可能难以处理的复杂性。
此外,QMLA的应用不仅仅局限于理论研究,它还可以作为实验设计的辅助工具,帮助科学家们制定更有效的实验策略,减少实验次数,提高测量精度。随着量子科技的发展,这种将机器学习与量子物理学相结合的方法有望在未来的研究中发挥关键作用,推动量子信息科学和量子技术的进步。
总结来说,量子模型学习代理作为一种新型的机器学习算法,它的出现极大地增强了我们理解和控制量子系统的能力,特别是在面对实验数据解析难题时。通过将哈密顿ian表征与机器学习方法结合起来,QMLA为探索量子世界的奥秘提供了一种强大的分析工具。随着技术的进一步发展,它有望在未来的量子科学研究中扮演核心角色。
6
0.0
0.5
1.0
F
1
-score
5 10
Bayes factor comparison
950
1000
1050
1100
R
i
(a)
5 10 15
Generation
(b)
10% 25%
Model space
0.0
0.5
1.0
F
1
(c)
10% 25%
{
ˆ
H
i
}
25% 75%
{
ˆ
H
0
}
ˆ
σ
x
i,2
ˆ
σ
y
i,2
ˆ
σ
z
i,2
ˆ
σ
x
i,3
ˆ
σ
y
i,3
ˆ
σ
z
i,3
ˆ
σ
x
i,4
ˆ
σ
y
i,4
ˆ
σ
z
i,4
Coupling qubit/axis
1
2
3
Qubit, i
(d)
∈ T
0
/∈ T
0 /∈ T
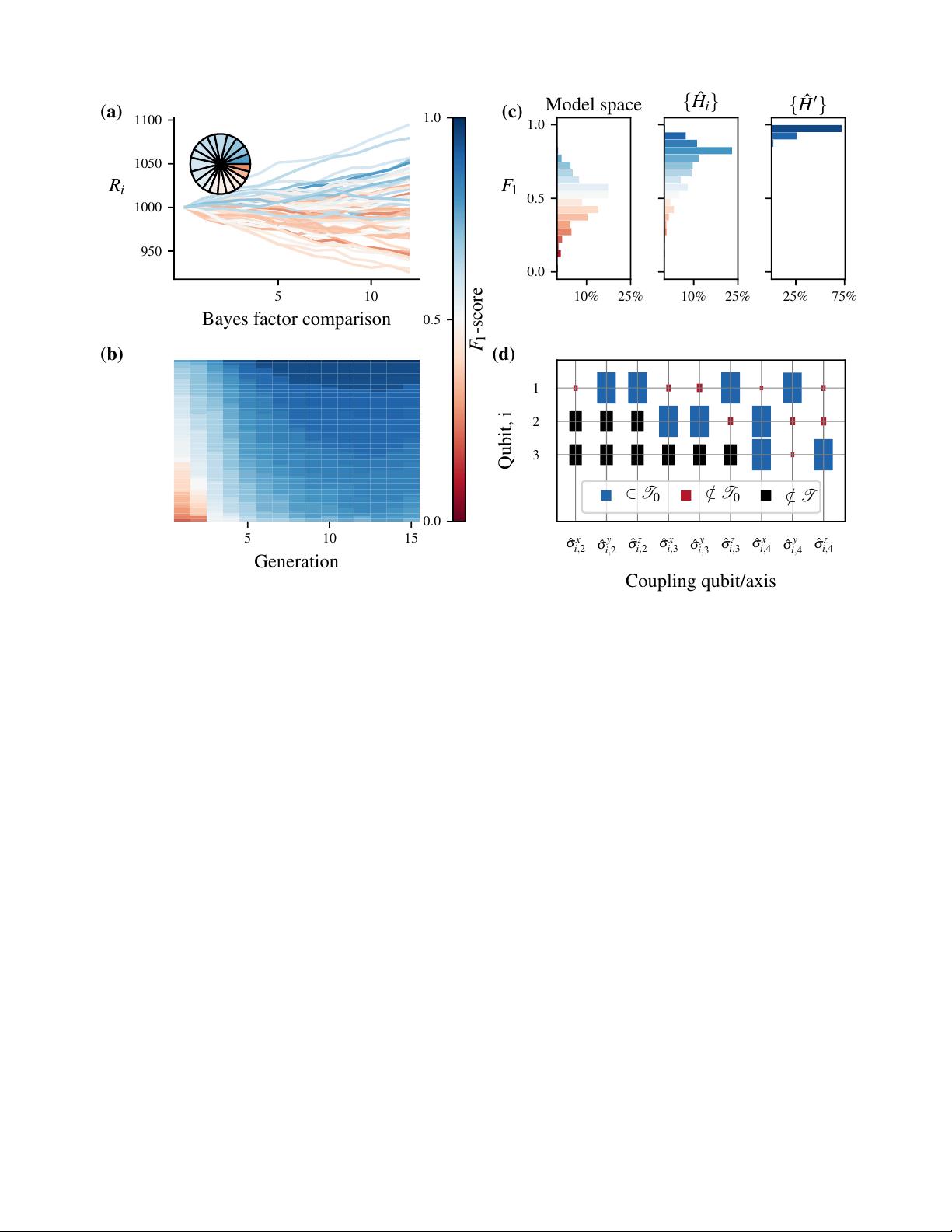
FIG. 4. Genetic algorithm exploration strategy within QMLA. (a-b), Single instance of QMLA. The genetic algorithm
runs for N
g
= 15 generations, where each generation tests N
m
= 60 models. (a), Ratings of all models in a single genetic
algorithm generation. Each line represents a unique model and is coloured by the F
1
-score of that model. Inset, the selection
probabilities resulting from the final ratings of this generation, i.e. the models’ chances of being chosen as a parent to a
new model. Only a fraction of models are assigned selection probability, while the remaining poorer-performing models are
truncated. (b), Gene pool progression for N
m
= 60, N
g
= 15. Each tile at each generation represents a model by its F
1
-score.
(c-d), Results of 100 QMLA instances using the genetic algorithm exploration strategy. (c), The model space in
which QMLA searches. (Left) The total model space contains 2
18
≈ 250, 000 candidate models; normally distributed around
¯
f = 0.5 ± 0.14. (Centre), The models explored during the model search of all instances combined, {
ˆ
H
i
}, show that QMLA
tends towards stronger models overall, with models considered having
¯
f = 0.76 ± 0.15 from ∼ 43, 000 chromosomes across the
instances, i.e. each instance trains ∼ 430 distinct models. (Right), Champion models from each instance, showing QMLA finds
strong models in general, and in particular finds the true model
ˆ
H
0
(with f = 1) in 72% of cases, and f ≥ 0.88 in all instances.
(d), Hinton diagram showing the rate at which each term is found within the winning model,
ˆ
H
0
. The size of the blocks show
the frequency with which they are found, while the colour indicates whether that term was in the true model (blue) or not
(red). Terms represent the coupling between two qubits, e.g ˆσ
x
(1,3)
couples the first and third qubits along the x-axis. We test
four qubits with full connectivity, resulting in 18 unique terms (terms with black rectangles are not considered by the GA).
• pairs of models connected by an edge, (
ˆ
H
i
,
ˆ
H
j
), are
compared through BF, giving B
ij
;
• the model indicated as inferior by B
ij
transfers
some of its rating to the superior model: the quan-
tity transferred, ∆R
ij
, reflects
– the statistical evidence given by B
ij
;
– the initial ratings of both models, {R
i
, R
j
}.
The ratings of models on µ therefore increase or de-
crease depending on their relative performance, shown
for an exemplary generation in Fig. 4a.
We use a roulette selection for the design of new candi-
date models: two models are selected from µ to become
parents and spawn offspring. The selection probability
for each model
ˆ
H
i
∈ µ is proportional to R
i
after all
comparisons on µ; the strongest
N
m
/3 models on µ are
available for selection as parents while evidently weaker
models are discarded, see Fig. 4(a - inset). This proce-
dure is repeated until N
m
models are proposed; these do
not have to be new – QMLA may have considered any
given model previously – but all models within a gen-
eration should be distinct. We show the progression of
剩余29页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-30 上传
2022-07-14 上传
2021-05-22 上传
2022-07-14 上传
2022-07-14 上传


易小侠
- 粉丝: 6626
- 资源: 9万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- ARSW-FINAL-EXAM2
- Tarea_Sistemas_distribuidos
- 北方交通大学硕士研究生入学考试试题结构力学2006.rar
- hunter
- CortexAnalysis:基于皮质分析的诊断
- UrsineEngine:跨平台游戏引擎,用C ++编写并可通过Python编写脚本
- Zebra_Accordion:jQuery的小手风琴插件-开源
- CipherApp:基本密码应用程序
- test_glassdoor
- abetsunggo.me
- 考试 冬小麦不同水分条件下的产量试验进行了不同水分处
- blobgen:JS库,用于将随机化的剪切路径应用于HTML元素,创建有趣的非矩形形状
- ASAM_OpenDRIVE_BS_V1-6-0_cn.7z
- MyApplication.zip
- 少儿编程Scratch与数学深度融合课程(全套视频资料).rar
- VC++自绘制作weather天气预报界面
