Python爬虫实践:正则表达式与许可证抓取
149 浏览量
更新于2024-08-28
收藏 509KB PDF 举报
"这篇教程主要讨论了Python爬虫中如何运用正则表达式以及如何爬取开源许可证的信息。正则表达式是实现模糊匹配的重要工具,它可以包含普通字符和特殊字符来定义匹配规则。在Python中,我们通常使用re模块来处理正则表达式,比如通过`re.compile()`函数将字符串编译成正则表达式对象,以便在后续的匹配操作中使用。此外,`re.compile()`函数的`flags`参数可以设置匹配选项,如忽略大小写、多行模式等。对于匹配操作,`re.match()`函数用于检查字符串开头是否符合正则表达式,但不会检查字符串的其他部分。"
正则表达式是Python爬虫中不可或缺的部分,它允许我们从网页内容中提取所需的数据。在Python中,正则表达式是通过内置的`re`模块来使用的。正则表达式可以包含普通字符,如字母、数字,以及特殊字符,如`\d`(匹配数字)、`\s`(匹配空白字符)等,这些特殊字符提供了灵活的匹配模式,以实现模糊匹配。例如,`\b`用来匹配单词边界,使得我们能准确地匹配单词而不是单词的一部分。
`re.compile()`函数是正则表达式的核心,它接收一个字符串作为参数,该字符串定义了正则表达式模式。通过这个函数,我们可以创建一个正则表达式对象,这个对象可以在后续的匹配操作中复用,提高了效率。例如,`re.compile(r'\bfoo\b')`会创建一个匹配单词"foo"的正则表达式对象,而不考虑大小写。`flags`参数可以设置为不同的标志,如`re.IGNORECASE`(或`re.I`)用于不区分大小写匹配,`re.VERBOSE`(或`re.X`)用于编写更易读的正则表达式,忽略空格和注释,以及`re.MULTILINE`(或`re.M`)用于多行匹配,使`^`和`$`可以匹配每一行的开头和结尾。
在实际的爬虫项目中,`re.match()`函数通常用于检查字符串是否以特定的模式开始。例如,如果我们想在一段文本中查找以"Python"开头的行,即使忽略大小写,可以这样写:
```python
import re
text = '''我喜欢学习Python
Python是一门流行的编程语言'''
pattern = re.compile(r'^Python', re.IGNORECASE | re.MULTILINE)
match_result = re.match(pattern, text)
if match_result:
print('找到了匹配的开头')
else:
print('没有找到匹配的开头')
```
在这个例子中,由于`re.match()`只检查字符串的开头,所以尽管文本中包含了"Python",但因为不是在第一行的开头,所以匹配失败。
除此之外,`re.search()`函数是另一个常用的函数,它会在整个字符串中寻找第一个匹配项,而不仅仅是字符串的开头。如果需要查找字符串中的所有匹配项,可以使用`re.findall()`或`re.finditer()`。
至于开源许可证的爬取,这通常涉及到从项目的README文件、LICENSE文件或者项目的网页中提取许可信息。使用正则表达式,我们可以匹配常见的许可证名称,如"LGPL"、"MIT"、"Apache-2.0"等,或者匹配包含许可证文本的模式。一旦找到匹配的模式,就可以进一步处理这些信息,比如将其存储到数据库或进行分类分析。
Python爬虫中的正则表达式是数据提取的关键工具,它可以帮助我们从海量的网页数据中精准地抓取目标信息。通过熟练掌握正则表达式和`re`模块,我们可以构建更高效、更灵活的爬虫解决方案,无论是处理简单的文本匹配还是复杂的结构化数据提取。
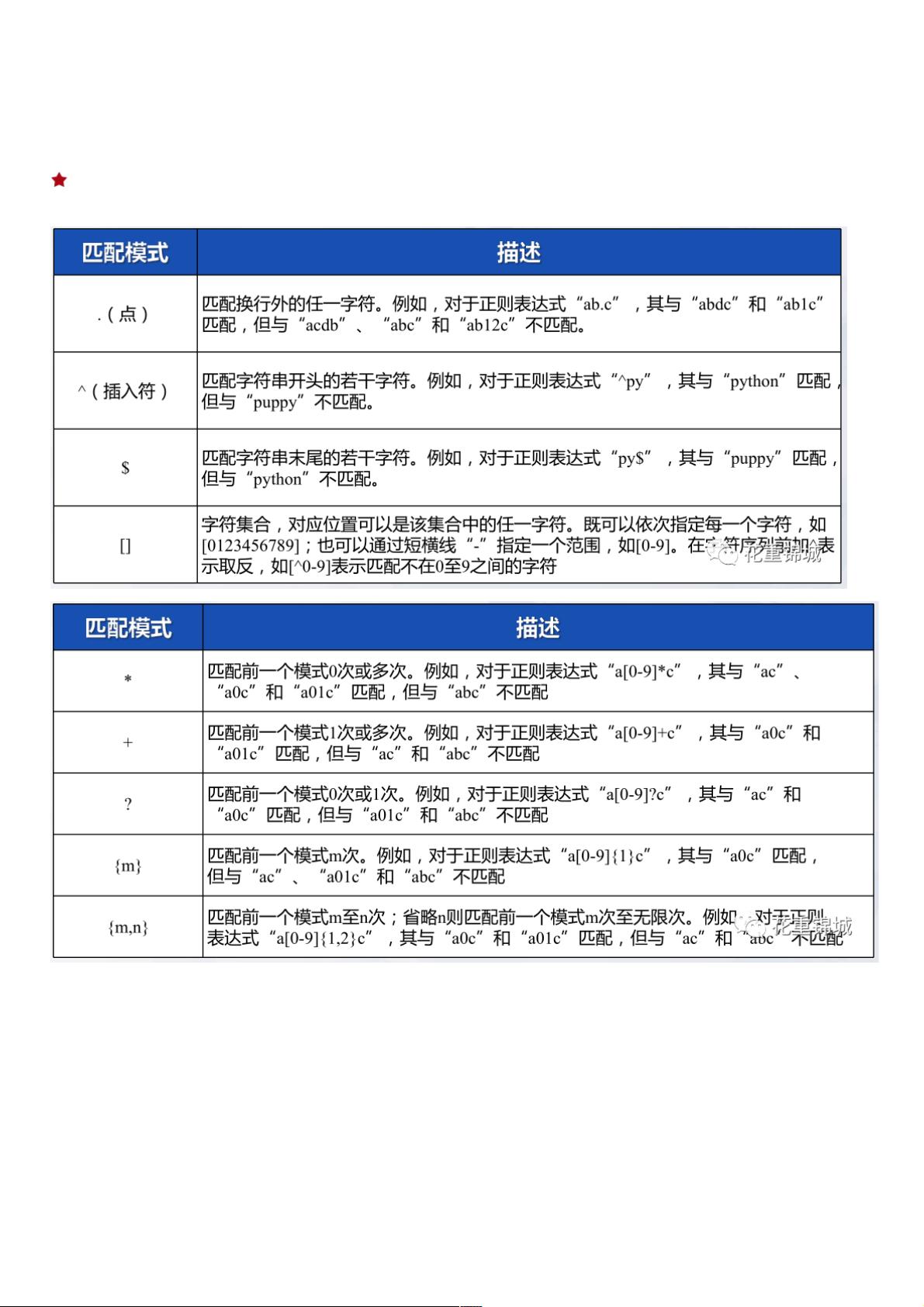
python爬虫之正则表达式及开源许可证的爬取爬虫之正则表达式及开源许可证的爬取
– 通过正则表达式可以定义一些匹配规则,只要满足匹配规则即认为匹配成功,从而实现通过正则表达式可以定义一些匹配规则,只要满足匹配规则即认为匹配成功,从而实现模模糊匹配糊匹配。。
– 正则表达式中既可以包含普通字符,也可以包含由特殊字符指定的匹配模式。正则表达式中既可以包含普通字符,也可以包含由特殊字符指定的匹配模式。
– 在实际应用正则表达式进行匹配时,正则表达式中的在实际应用正则表达式进行匹配时,正则表达式中的普通字符需要做精确匹配,而普通字符需要做精确匹配,而特殊字符特殊字符指定的匹配模式则对应了用于指定的匹配模式则对应了用于模糊匹配的规则。模糊匹配的规则。
常用的匹配模式常用的匹配模式
下载后可阅读完整内容,剩余4页未读,立即下载
183 浏览量
101 浏览量
269 浏览量
342 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
112 浏览量
点击了解资源详情

weixin_38679277
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 经典J2ME坦克对战游戏:回顾与介绍
- ZAProxy自动化工具集合:提升Web安全测试效率
- 破解Steel Belted Radius 5.3安全验证工具
- Python实现的德文惠斯特游戏—开源项目
- 聚客下载系统:体验极速下载的革命
- 重力与滑动弹球封装的Swift动画库实现
- C语言控制P0口LED点亮状态教程及源码
- VB6中使用SQLite实现列表查询的示例教程
- CMSearch:在CraftMania服务器上快速搜索玩家的Web应用
- 在VB.net中实现Code128条形码绘制教程
- Java SE Swing入门实例分析
- Java编程语言设计课程:自动机的构建与最小化算法实现
- SI9000阻抗计算软件:硬件工程师的高频信号分析利器
- 三大框架整合教程:S2SH初学者快速入门
- PHP后台管理自动化生成工具的使用与资源分享
- C#开发的多线程控制台贪吃蛇游戏源码解析
