朴素贝叶斯分类方法详解:从理论到Python实践
需积分: 15 144 浏览量
更新于2024-08-05
收藏 968KB PDF 举报
"《机器学习实战》第四章深入探讨了基于概率论的分类方法,特别是朴素贝叶斯算法。这份学习笔记涵盖了从贝叶斯决策理论基础到实际应用的完整过程,包括条件概率、贝叶斯准则以及如何利用这些概念进行分类。资源还提供了Python实现文本分类的示例,帮助理解朴素贝叶斯在文档分类中的应用。"
在机器学习领域,朴素贝叶斯是一种基于概率论的分类算法,尤其适用于处理大量文本数据。本章首先介绍了基于贝叶斯决策理论的分类方法,通过计算数据点属于不同类别的概率来决定新样本的归属。决策理论的基本思想是选择具有最高后验概率的类别。
条件概率是贝叶斯分类中的核心概念,它表示在已知某一事件发生的情况下,另一事件发生的概率。朴素贝叶斯算法利用贝叶斯定理来交换条件和结果,从而计算给定特征条件下类别的概率。在实际应用中,朴素贝叶斯的"朴素"假设是指各个特征之间相互独立,这简化了计算但可能在某些复杂场景下导致性能下降。
在文档分类问题中,朴素贝叶斯被广泛采用。每个文档被视为一个实例,其特征由文档中出现的单词组成。朴素贝叶斯分类器假设每个单词的出现是独立的,这意味着一个单词的存在不会影响其他单词的出现概率。这种假设使得计算每个文档属于特定类别的概率变得简单。
在Python中实现朴素贝叶斯文本分类时,首先要对文本进行预处理,包括拆分单词、创建词汇表并构建词项向量。每个文档会被表示为一个向量,其中向量的每个元素对应词汇表中的一个单词,值为1表示该单词在文档中出现,0则表示未出现。通过这种方式,可以将非结构化的文本数据转化为可供机器学习算法处理的数值形式。
总结来说,本章内容详细介绍了朴素贝叶斯分类器的工作原理,从理论到实践,涵盖了从贝叶斯决策理论到Python代码实现的全过程,是学习和理解朴素贝叶斯分类算法的理想资料。这份资源不仅适合初学者,也对有经验的数据科学家有价值,因为它提供了一个清晰的框架来理解和应用朴素贝叶斯分类。
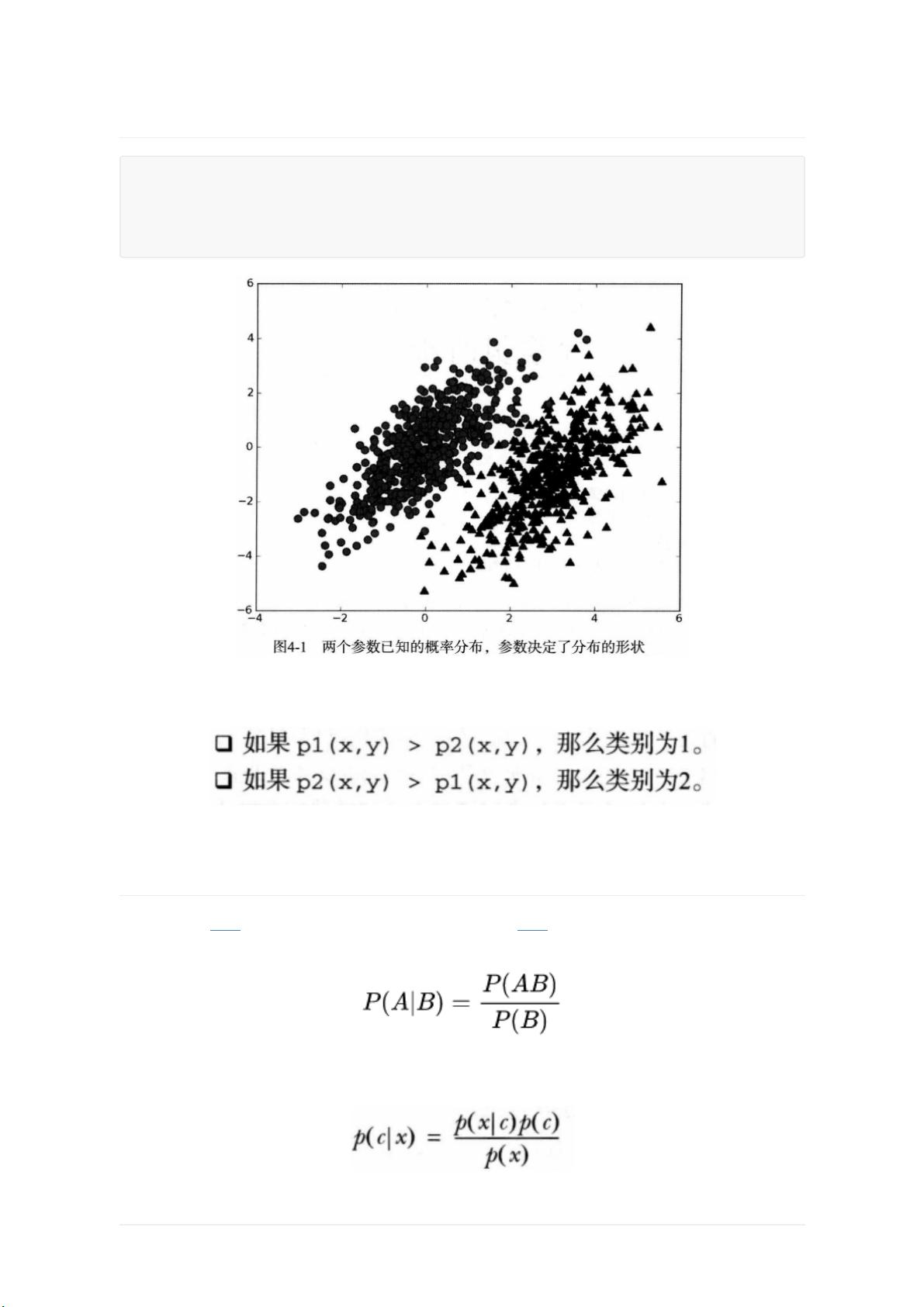
4.1基于贝叶斯决策理论的分类方法
用p1(x,y)表示数据点(x,y)属于类别1(圆点)的概率,用p2(x,y)表示数据点(x,y)属于类别2(三角形)的概率。
对于一个新数据点(x,y),通过下面的规则判断它的类别:
决策理论的核心思想是选择具有最高概率的决策。
4.2条件概率
条件概率是指事件A在事件B发生的条件下发生的概率。条件概率表示为:P(A|B),读作“A在B发生
的条件下发生的概率”。若只有两个事件A,B,那么
贝叶斯准则可有效计算条件概率,通过该准则可知如何交换条件概率中的条件与结果,即如果已知
P(x|c),要求P(c|x),那么可以使用下面的计算方法:
4.3使用条件概率来分类
朴素贝叶斯
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
下载后可阅读完整内容,剩余8页未读,立即下载
2020-08-09 上传
2020-09-21 上传
2023-03-01 上传
点击了解资源详情
2021-02-16 上传
2021-05-03 上传
2022-05-18 上传
2021-05-19 上传

Mr.狐友
- 粉丝: 586
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
