单节点Hadoop伪分布式配置与环境变量设置
需积分: 22 21 浏览量
更新于2024-08-31
收藏 376KB PDF 举报
本篇文档主要介绍了如何在单节点上进行Hadoop的伪分布式安装和配置过程。Hadoop伪分布式模式允许用户在一台机器上模拟Hadoop集群的功能,便于本地开发和测试,而无需搭建完整的分布式环境。
首先,设置Hadoop环境变量是伪分布式配置的基础。用户需在Linux的.bashrc文件中添加必要的环境变量,如HADOOP_HOME、HADOOP_MAPRED_HOME、HADOOP_COMMON_HOME、HADOOP_HDFS_HOME等,以及HADOOP_HOME下的sbin和bin路径,确保系统可以识别和找到Hadoop的相关可执行文件。设置完成后,通过source ~/.bashrc命令使更改生效,并通过echo命令检查环境变量是否已正确设置。
接下来,配置的核心是修改核心配置文件core-site.xml和HDFS配置文件hdfs-site.xml,这两个文件位于Hadoop安装目录的/etc/hadoop/下。core-site.xml负责配置Hadoop通用属性,如临时文件路径(hadoop.tmp.dir),这里将它设置为一个本地文件系统路径,如file:///root/soft/hadoop。
在core-site.xml中,使用XML结构添加配置项,例如:
```xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///root/soft/hadoop</value>
<!-- 可能还包括其他配置项 -->
</property>
</configuration>
```
同样,hdfs-site.xml文件中可能涉及HDFS的特定配置,如名称节点(NameNode)和数据节点(DataNode)的地址、副本策略等。在单节点伪分布式环境中,这些配置可能会有所不同,因为NameNode和DataNode都运行在同一台机器上。
在完成配置后,用户需要验证配置文件是否正确,可以通过启动Hadoop服务(如start-dfs.sh或start-yarn.sh)并检查日志来确认。如果一切顺利,Hadoop将在本地以伪分布式方式运行,允许用户在本地开发和测试MapReduce和HDFS应用。
总结来说,本文档详细指导了Hadoop伪分布式环境的安装步骤,包括设置环境变量、配置核心和HDFS配置文件,以及检查配置效果。这对于理解和实践Hadoop的本地开发环境极其重要。
实验二:Hadoop 的伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,
节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
1. 在设置 Hadoop 伪分布式配置前,我们还需要设置 HADOOP 环境变量,执行如下命令
在 ~/.bashrc 中设置:
vim ~/.bashrc
进入
~/.bashrc
文件中,在文件最后加入
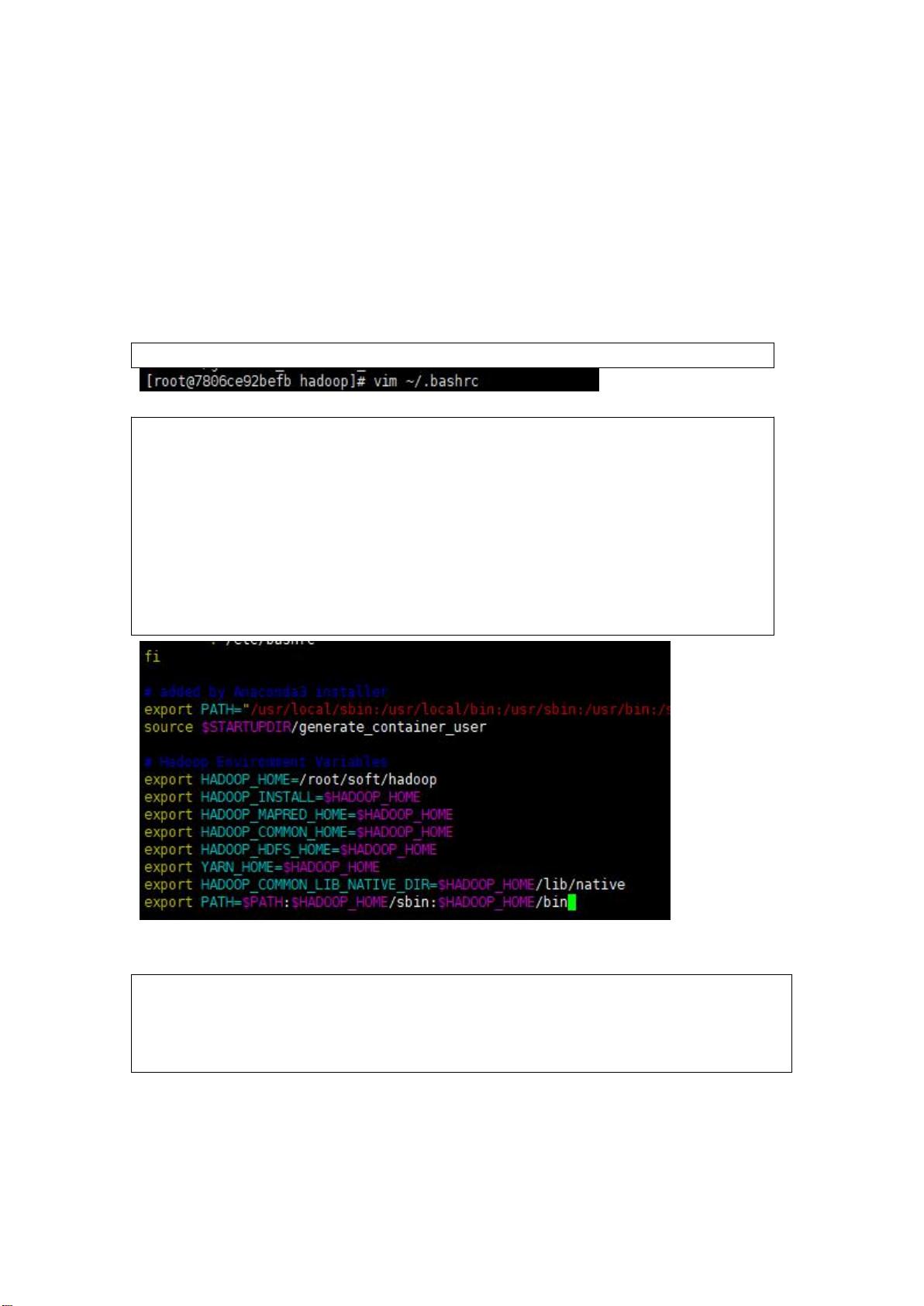
# Hadoop Environment Variables
export HADOOP_HOME=/root/soft/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
2. 查看配置后的效果
source ~/.bashrc
echo $HADOOP_HOME
echo $HADOOP_INSTALL
echo $YARN_HOME
下载后可阅读完整内容,剩余5页未读,立即下载
241 浏览量
198 浏览量
152 浏览量
449 浏览量
2022-07-04 上传

圆内~搁浅
- 粉丝: 34
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- ActionScript 3.0 Cookbook 中文版.pdf
- iBATIS in Action
- crc_explain 关于crc校验说明
- 软硬件开发人员的简历的模板
- 全国计算机等级考试网络三级详细资源
- S3C2410A_manual_r10.pdf
- 计算机操作系统(汤子瀛)习题答案
- 《实战C#.NET编程-Spring.NET & NHibernate从入门到精通》pdf部分
- GCC 入门剖析以及嵌入式汇编
- PMP项目管理师英文选择题试题一
- .NET中对文件的操作
- 使用pager-taglib实现分页显示的详细步骤
- CSAI信息系统项目管理师考试辅导模拟试题二(有答案)
- Apchche+php+Mysql+jsp+tomcat.WEB环境设置指南
- jmail 4.3使用方法PDF文档
- GDB Quick Reference Card
