Hive SQL性能优化:深度解析MapReduce阶段
192 浏览量
更新于2024-08-30
收藏 381KB PDF 举报
"深入浅出数据仓库中SQL性能优化之Hive篇"
在数据仓库领域,尤其是在使用Hive进行大规模数据分析时,SQL性能优化是至关重要的。Hive查询通常涉及多个MapReduce作业,每个作业内部包含Map、Reduce、Spill、Shuffle和Sort等多个阶段。因此,对Hive查询的优化策略可以分为对MapReduce单个步骤的优化、对整个MapReduce作业的全局优化,以及对整个查询(包括多个MapReduce作业)的优化。
首先,我们来看Map阶段的优化。Map阶段的主要任务是将输入数据切分成小块并处理。Map数的确定直接影响着查询效率。Map数由Mapred.min.split.size和Mapred.max.split.size两个参数决定,前者是数据最小分割单元,后者是最大分割单元。通常,HDFS的block.size是固定的,不被Hive直接识别,因此实际的Map数量主要由min和max参数控制。Hive默认的min是1B,max是256MB。通过调整max的值,可以增减Map的数量,但要注意,过多的Map任务可能导致调度开销增大,而过少的Map任务则可能导致数据处理不均衡。
接下来,我们关注Reduce阶段的优化。Reduce阶段主要负责聚合和排序操作。优化点包括合理设置Reduce任务数量,避免数据倾斜,以及选择合适的排序策略。数据倾斜是指部分Reduce任务处理的数据量远大于其他任务,这可能导致性能瓶颈。可以通过数据预处理、分区策略调整和使用随机分布函数等方式来减轻数据倾斜。
Shuffle和Sort阶段的优化涉及到数据的重新分配和排序。确保数据正确地在Map和Reduce之间传递,以及正确地排序,可以显著提升性能。例如,使用合适的分区列和bucketing可以减少Shuffle阶段的数据交换量,提高效率。
针对整个MapReduce作业的优化,可以考虑合并相邻的MapReduce作业,减少Job的启动和初始化时间。此外,启用Combiner可以减少网络传输的数据量,提高效率。
最后,对于跨多个MapReduce作业的查询优化,可以通过Join策略调整、子查询优化、使用Materialized Views(如果支持)或者使用Tez或Spark等更高效的执行引擎来提升性能。
在实际应用中,还需要结合业务需求和集群资源状况,通过监控和调优工具(如Hive的Explain命令和Hadoop的YARN Resource Manager)来持续监控和优化查询性能。同时,定期更新和升级到最新的Hive和Hadoop版本也是保持高效运行的重要手段。
Hive SQL性能优化是一个涉及多个层面的复杂过程,需要综合考虑数据分布、任务划分、执行引擎和系统配置等多个因素。通过对每个阶段的深入理解和针对性优化,可以显著提升大数据查询的效率,满足数据仓库在实时分析和决策支持中的高要求。
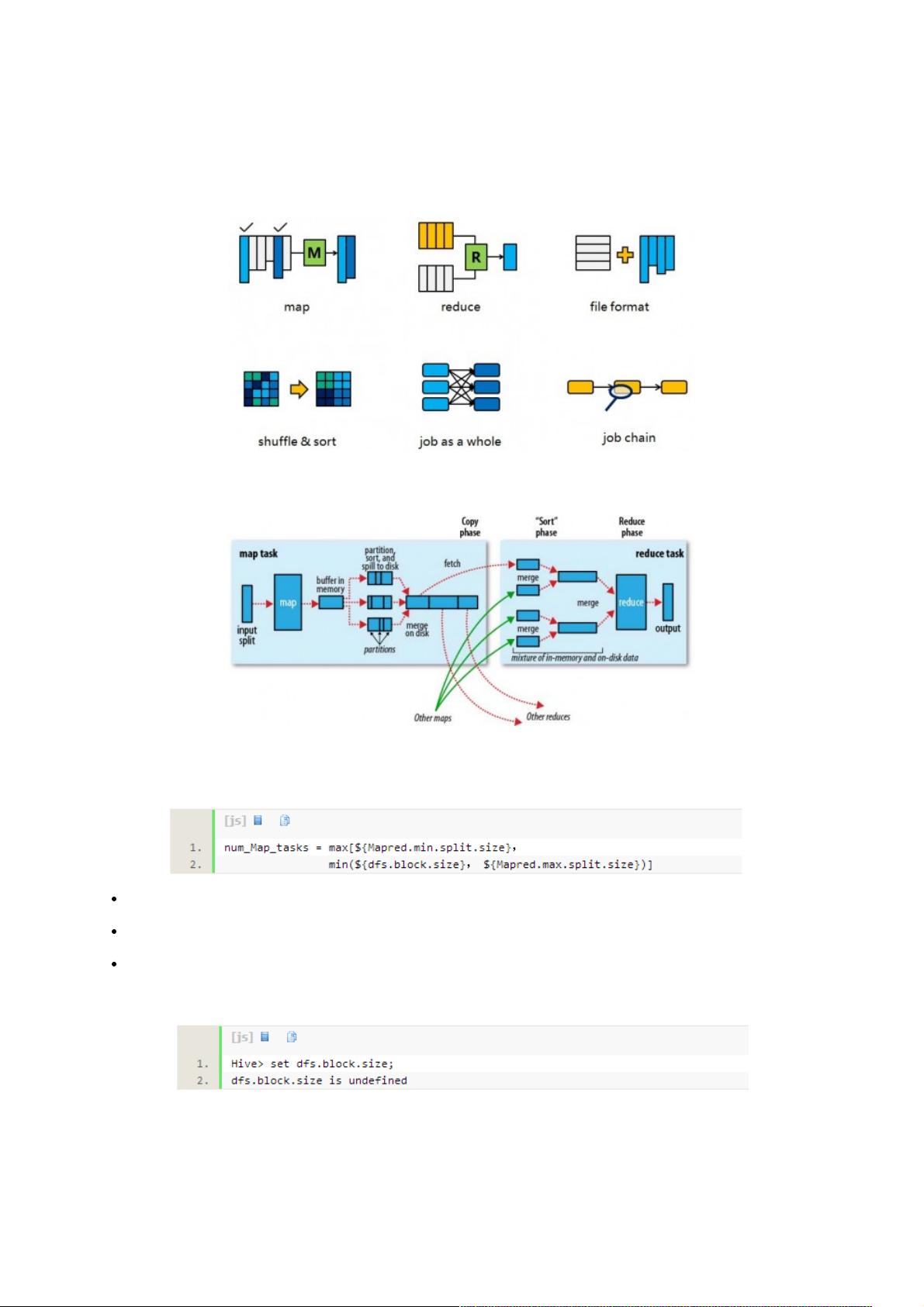
深入浅出数据仓库中深入浅出数据仓库中SQL性能优化之性能优化之Hive篇篇
Hive查询生成多个map reduce job,一个map reduce job又有map,reduce,spill,shuffle,sort等多个阶段,所以针对hive查
询的优化可以大致分为针对MR中单个步骤的优化,针对MR全局的优化以及针对整个查询的优化。
一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,Reduce,Spill,Shuffle,Sort等多个阶段,所以
针对Hive查询的优化可以大致分为针对MR中单个步骤的优化(其中又会有细分),针对MR全局的优化,和针对整个查询
(多MR Job)的优化,下文会分别阐述。
在开始之前,先把MR的流程图帖出来(摘自Hadoop权威指南),方便后面对照。另外要说明的是,这个优化只是针对Hive
0.9版本,而不是后来Hortonwork发起Stinger项目之后的版本。相对应的Hadoop版本是1.x而非2.x。
Map阶段的优化(Map phase)
Map阶段的优化,主要是确定合适的Map数。那么首先要了解Map数的计算公式:
Mapred.min.split.size指的是数据的最小分割单元大小。
Mapred.max.split.size指的是数据的最大分割单元大小。
dfs.block.size指的是HDFS设置的数据块大小。
一般来说dfs.block.size这个值是一个已经指定好的值,而且这个参数Hive是识别不到的:
所以实际上只有Mapred.min.split.size和Mapred.max.split.size这两个参数(本节内容后面就以min和max指代这两个参数)来
决定Map数量。在Hive中min的默认值是1B,max的默认值是256MB:
下载后可阅读完整内容,剩余8页未读,立即下载
2019-04-28 上传
2018-05-31 上传
2022-03-24 上传
2019-11-09 上传
2015-03-06 上传
2021-10-14 上传
2018-02-27 上传
2014-10-14 上传
2018-08-20 上传

weixin_38670700
- 粉丝: 1
- 资源: 917
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
