TensorFlow架构解析:前端与后端交互机制
75 浏览量
更新于2024-08-27
收藏 219KB PDF 举报
"TensorFlow的架构设计分为前端和后端两部分,前端负责编程模型和计算图构造,而后端则负责运行时环境和计算图执行。前端作为Client,通过Session管理生命周期并与后端的运行时环境交互。后端系统执行计算图的剪枝、设备分配和子图计算等操作。Swig在前端多语言环境与后端C/C++之间起到桥梁作用,自动生成Python和C++的适配器文件。在Session创建时,Python前端通过Swig调用C++后端的函数实现,动态链接库加载并执行计算图。"
在深入理解TensorFlow的架构与设计时,首先需要了解其核心概念——计算图。计算图是一种数据流图,其中每个节点代表一个操作(op),边表示数据流。前端系统提供了编程模型,使得开发者能够用Python等支持的语言定义计算图。在这个过程中,开发者可以创建变量、常量、运算符等,并将它们组织成逻辑上的计算单元。
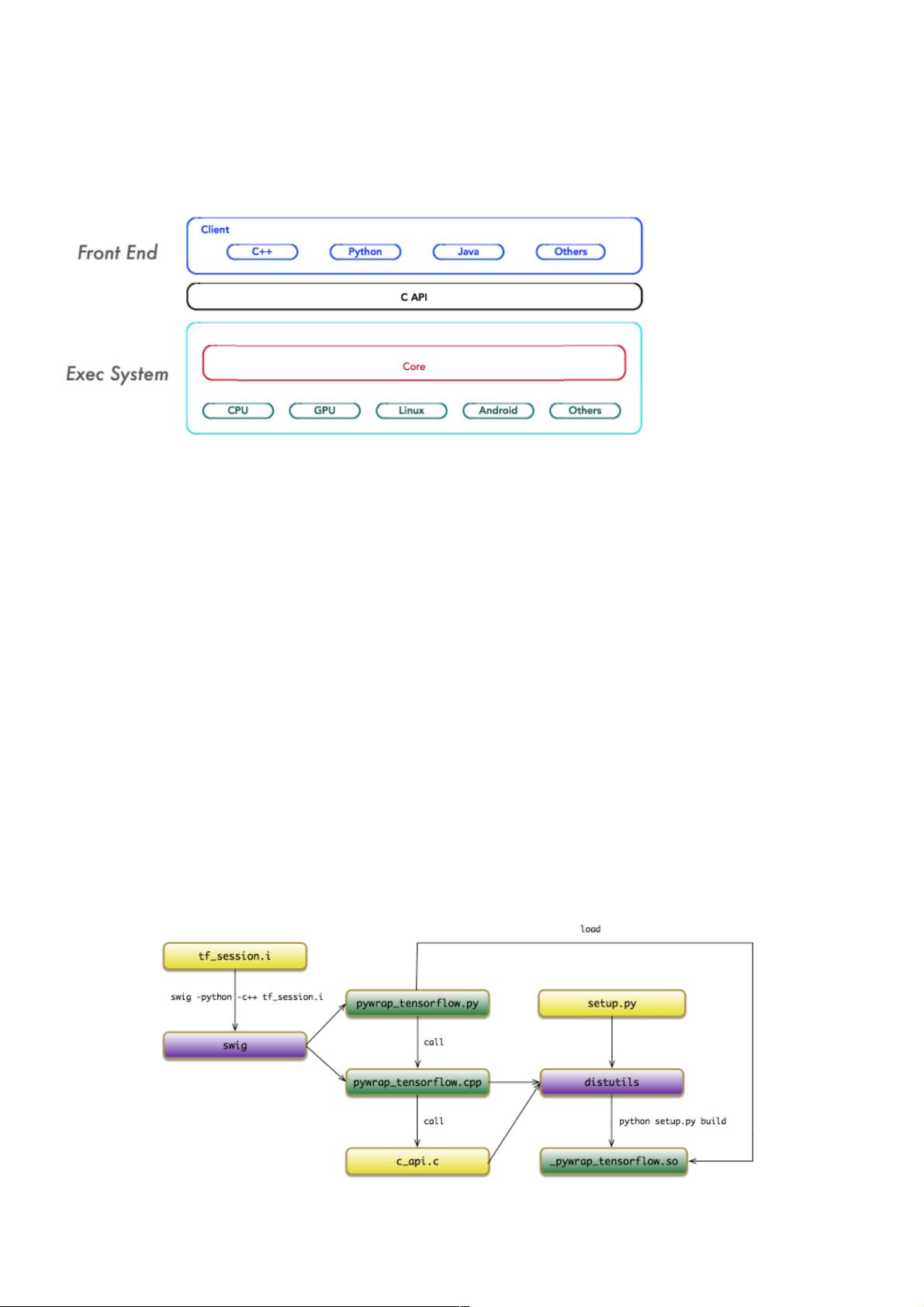
Session是TensorFlow中的关键组件,它管理计算图的生命周期。在创建Session时,前端Python代码调用基类BaseSession的构造函数,这实际是通过Swig生成的Python接口pywrap_tensorflow.py与底层C++实现pywrap_tensorflow.cpp进行通信。C++部分包含了对C API的调用,这些API最终指向了c_api.c中的具体实现。
Swig是一个接口生成工具,它能自动将C/C++库转换为多种高级语言的绑定。在TensorFlow中,Swig生成的pywrap_tensorflow.py文件提供了Python调用C++的接口,而pywrap_tensorflow.cpp则实现了C++与C API的对接。当Python程序加载pywrap_tensorflow.py模块时,会自动加载动态链接库,完成Python到C++的函数调用映射。
在Session的生命周期中,创建Session通常伴随着目标(target)的指定,这可以是本地的CPU或GPU,或者是远程的分布式服务器。Session的初始化阶段包括了计算图的构建和优化,如计算图的剪枝,这有助于减少不必要的计算和内存消耗。设备分配则是指确定哪些运算将在哪个设备上执行,这可能涉及到CPU、GPU甚至TPU等不同硬件资源。
在Session运行期间,通过调用`run()`方法,用户可以执行计算图中的特定部分或者整个图。这个过程包括了计算图的执行计划的生成,子图的计算,以及数据在设备间的传输。执行完成后,Session可以被关闭,释放相关的资源。
总而言之,TensorFlow的架构设计巧妙地结合了前端的易用性和后端的高性能,通过Swig实现多语言接口,确保了跨平台和跨语言的兼容性。Session作为前端与后端交互的核心,管理着计算图的构建、优化和执行,是理解TensorFlow工作原理的关键。
TensorFlow架构与设计:会话生命周期架构与设计:会话生命周期
TensorFlow的系统结构以C API为界,将整个系统分为「前端」和「后端」两个子系统:
前端系统:提供编程模型,负责构造计算图;
后端系统:提供运行时环境,负责执行计算图。
系统架构
前端系统主要扮演Client的角色,主要负责计算图的构造,并管理Session生命周期过程。
前端系统是一个支持多语言的编程环境,并提供统一的编程模型支撑用户构造计算图。Client通过Session,连接TensorFlow
后端的「运行时」,启动计算图的执行过程。
后端系统是TensorFlow的运行时系统,主要负责计算图的执行过程,包括计算图的剪枝,设备分配,子图计算等过程。
本文首先以Session创建为例,揭示前端Python与后端C/C++系统实现的通道,阐述TensorFlow多语言编程的奥秘。随后,以
Python前端,C API桥梁,C++后端为生命线,阐述Session的生命周期过程。
Swig: 幕后英雄
前端多语言编程环境与后端C/C++实现系统的通道归功于Swig的包装器。TensorFlow使用Bazel的构建工具,在编译之前启动
Swig的代码生成过程,通过tf_session.i自动生成了两个适配(Wrapper)文件:
pywrap_tensorflow.py: 负责对接上层Python调用;
pywrap_tensorflow.cpp: 负责对接下层C实现。
此外,pywrap_tensorflow.py模块首次被加载时,自动地加载_pywrap_tensorflow.so的动态链接库。从而实现了
pywrap_tensorflow.py到pywrap_tensorflow.cpp的函数调用关系。
在pywrap_tensorflow.cpp的实现中,静态注册了一个函数符号表。在运行时,按照Python的函数名称,匹配找到对应的C函
数实现,最终转调到c_api.c的具体实现。
Swig代码生成器
编程接口:Python
下载后可阅读完整内容,剩余5页未读,立即下载
2021-10-18 上传
2019-10-15 上传
点击了解资源详情
点击了解资源详情
2021-02-15 上传
2017-07-27 上传
2021-03-24 上传
点击了解资源详情
点击了解资源详情

weixin_38570278
- 粉丝: 4
- 资源: 978
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
