PySpark快速入门:数据科学与实践
需积分: 10 112 浏览量
更新于2024-07-17
收藏 1003KB PDF 举报
"PySpark简介:数据科学入门"
PySpark是Apache Spark的一个Python接口,它允许开发人员使用Python语法来操作Spark数据结构。这个资源主要面向已经熟悉Python和如Pandas等库的数据科学家,旨在介绍如何开始使用PySpark进行大规模的数据探索、构建机器学习管道以及创建数据平台的ETL(提取、转换、加载)流程。通过学习PySpark,你可以将你的分析和管道扩展到更大型的数据集。
本教程中,作者使用Databricks作为Spark运行环境,Kaggle上的NHL(北美冰球联盟)比赛数据集作为分析数据源。首先,它会演示如何在PySpark中读写数据到DataFrame,这是Spark的核心数据结构。DataFrame类似于Pandas DataFrame,但具有分布式计算的能力,能处理大量数据。
接下来,教程会介绍如何对DataFrame进行转换和聚合操作,这是数据分析中的基础步骤。这些操作包括但不限于选择列、过滤行、分组聚合等。同时,还会展示如何可视化结果,这对于理解数据和发现模式至关重要。
此外,文章还将涉及线性回归的实现,这是一种广泛用于预测分析的统计方法。作者会展示如何在PySpark中执行线性回归,并结合Pandas用户定义函数(UDF)来实现Python代码与PySpark的混合使用。这种方法可以让你利用Pandas的便利性,同时保持Spark的可扩展性。
为了简化教学,本教程主要关注批处理处理,而不会深入到流处理或实时分析的复杂性。流处理在处理持续流入的数据时非常有用,但在初学者教程中可能过于复杂。
这篇“PySpark简介”是一个很好的起点,对于希望将Python技能扩展到大数据分析领域的数据科学家来说,提供了宝贵的指导。通过这个教程,读者不仅可以了解PySpark的基本用法,还能学会如何利用PySpark解决实际问题。
dataframe, you can apply transformations, perform analysis and
modeling, create visualizations, and persist the results. In Python,
you can load files directly from the local file system using Pandas:
import pandas as pd
pd.read_csv("dataset.csv")
In PySpark, loading a CSV file is a little more complicated. In a
distributed environment, there is no local storage and therefore a
distributed file system such as HDFS, Databricks file store (DBFS), or
S3 needs to be used to specify the path of the file.
Generally, when using PySpark I work with data in S3. Many
databases provide an unload to S3 function, and it’s also possible to
use the AWS console to move files from your local machine to S3. For
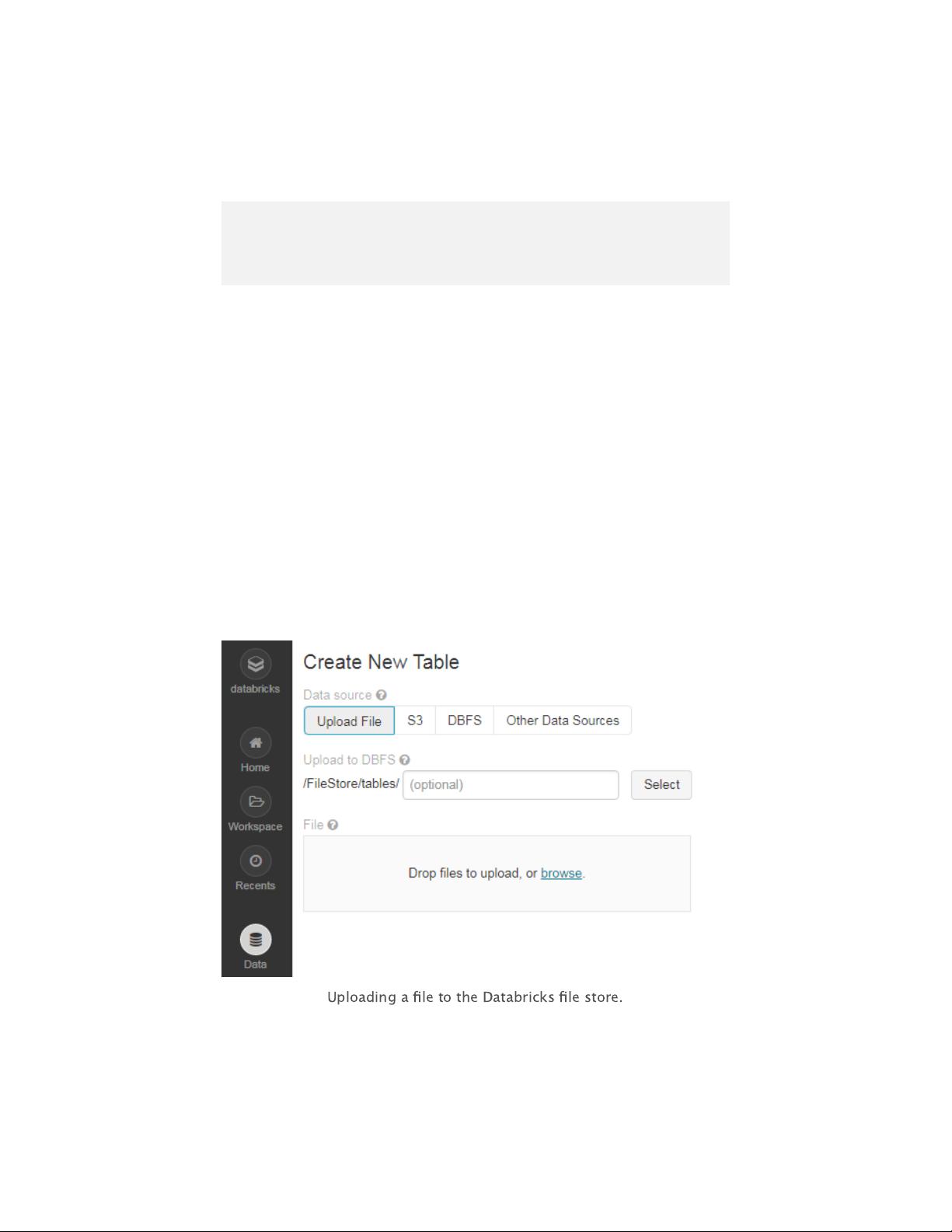
this post, I’ll use the Databricks file system (DBFS), which provides
paths in the form of /FileStore. The first step is to upload the CSV file
you’d like to process.
The next step is to read the CSV file into a Spark dataframe as shown
below. This code snippet specifies the path of the CSV file, and passes
a number of arguments to the read function to process the file. The
Uploading a
fi
le to the Databricks
fi
lestore.
剩余18页未读,继续阅读
2019-11-15 上传
2008-10-19 上传
2013-01-15 上传
2018-08-03 上传
2010-05-03 上传
2012-11-11 上传

潘小榭
- 粉丝: 13
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- RB101_109_Small_Probs:小问题,RB101_109
- 20210310A股市场规则研究系列开篇:开弓之箭,IPO制度变迁与展望.rar
- gardener.ren:园丁人
- Gulp-Assembly
- python 游戏源码植物大战僵尸
- AnandProducts.github.io
- Quantopian:为在 Quantopian.com 回测器中运行而构建的各种策略
- devjob:网站Site DevJob
- 2020年人工智能的认知神经基础白皮书.pdf.rar
- Travis Scott Wallpaper HD Custom New Tab-crx插件
- ember-cli-fontello:在 Ember 应用程序中使用 fontello 图标的 ember-cli 插件
- Mission_to_Mars
- getmysql2clickhouse
- 一组ADO类-版本2.20
- rust_cli:用于创建命令行应用程序的 mixin - 为 https 使用的参数规范和处理提供了一个简单的接口
- Redis windows版本的redis安装包和可视化工具客户端、redis存取数据的项目demo
