Spark实战:从核心到SQL、Streaming的深度探索
"Spark in Action 是一份专注于Spark学习和实战的资源,涵盖了SparkCore、SparkSQL、SparkStreaming等核心模块,旨在分享Spark的使用心得和项目经验。文档深入介绍了Spark平台的发展历程,从其在伯克利大学的研究背景到成为Apache顶级项目的过程,强调了Spark在数据科学领域的学术渊源和技术创新。"
Spark是一种分布式计算框架,以其高效、易用和多模态处理能力而闻名。在SparkCore中,SparkContext是启动Spark应用的关键,它是连接Spark集群和用户代码的桥梁,负责资源调度和任务管理。RDD(Resilient Distributed Datasets)是Spark的基本数据抽象,它代表了一组不可变、分区的记录集合,具有容错性,可以在集群中并行处理。
Spark的combineByKey操作用于对键值对数据集进行聚合,它可以自定义组合规则,允许用户聚合分区内和跨区的数据。结合这个操作,可以实现诸如求和、平均值等统计计算。在介绍中提到的PageRank算法是网络分析中的一个重要应用,Spark可以通过RDD的转换和行动操作高效地实现PageRank的迭代计算。
SparkSQL扩展了Spark的功能,引入DataFrame,它提供了一种结构化的数据处理方式,支持SQL查询和DataFrame API。DataFrame可以与多种数据源交互,包括HDFS、Cassandra、HBase等,这些数据源在SparkSQL中被统称为DataSources。ExternalDataSources允许Spark访问外部存储系统中的数据,增强了Spark的灵活性和可扩展性。此外,SparkSQL的性能调优和Catalyst优化器也是关键话题,Catalyst是一个基于规则的查询优化框架,能显著提升查询性能。
SparkStreaming是Spark处理实时数据流的模块,它将数据流分解成微小的批处理作业,利用SparkCore的并行处理能力实现低延迟的流处理。Spark的运维部分则关注如何部署和管理Spark集群,确保系统的稳定运行。
Spark in Action提供了全面的Spark学习路径,从基础概念到高级特性,再到实战经验,对于希望深入理解和应用Spark的开发者来说是一份宝贵的资料。通过这份资源,读者不仅可以掌握Spark的核心技术,还能了解到如何在实际项目中有效地使用Spark解决大数据问题。

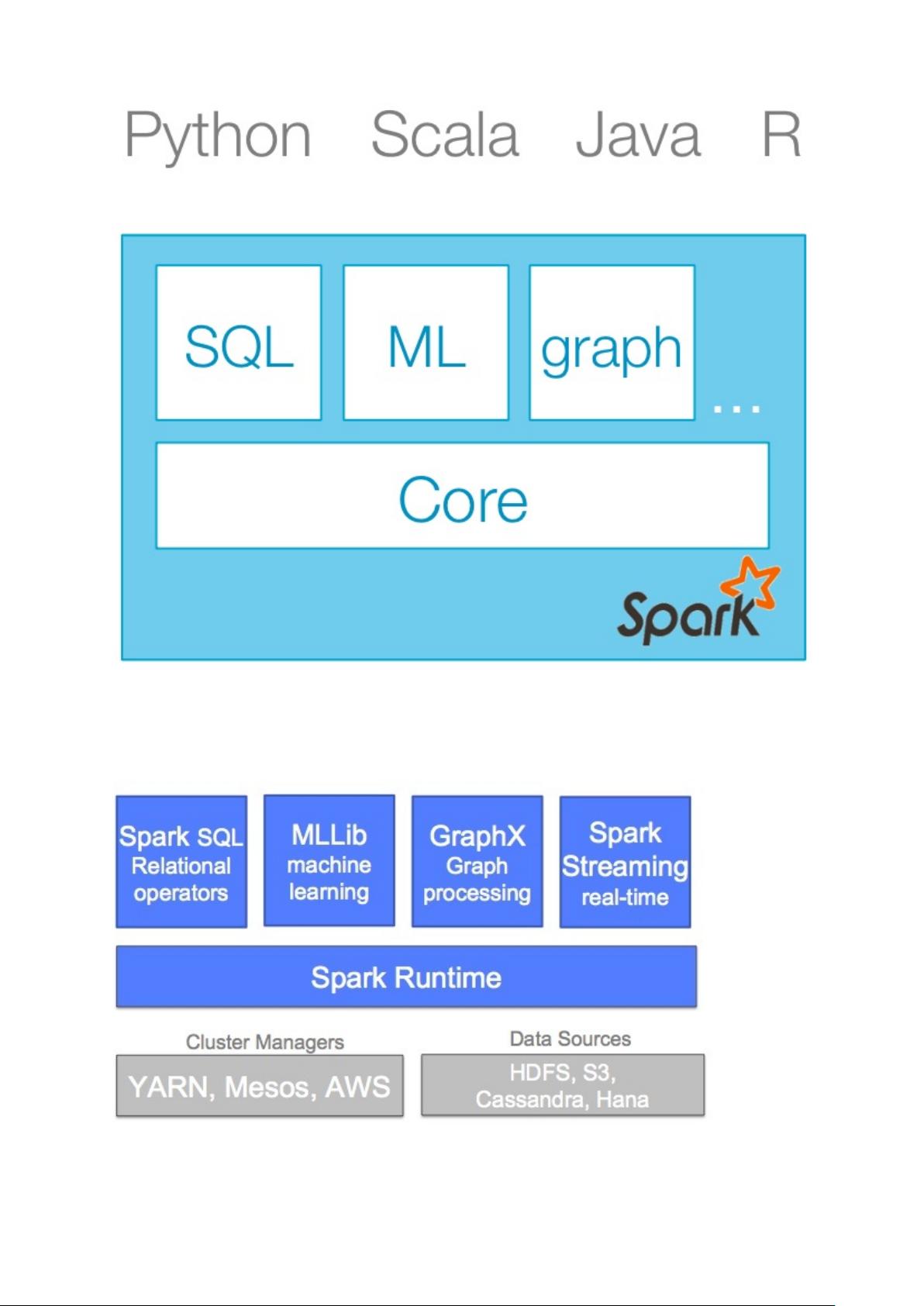
这样的一种统一平台带来的优势非常明显。对于开发者而言,只需要学习一个平台,降低了学习曲线。对于用户而言,可以
很方便地将Spark应用运行在Hadoop、Mesos等平台上面,满足了良好的可迁移性。统一的数据处理方式,也可以简化开发
模型,降低平台的维护难度。
Spark为大数据提供了通用算法的标准库,这些算法包括MapReduce、SQL、Streaming、MachineLearning与Graph
Processing。同时,它还提供了对Scala、Python、Java(支持Java8)和R语言的支持:
SparkinAction
7概览
剩余37页未读,继续阅读
2018-05-29 上传
2018-04-21 上传
2018-06-20 上传
2022-03-19 上传
2021-03-16 上传
2018-04-27 上传
2017-11-27 上传
2021-02-17 上传

追梦1206
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- PureMVC AS3在Flash中的实践与演示:HelloFlash案例分析
- 掌握Makefile多目标编译与清理操作
- STM32-407芯片定时器控制与系统时钟管理
- 用Appwrite和React开发待办事项应用教程
- 利用深度强化学习开发股票交易代理策略
- 7小时快速入门HTML/CSS及JavaScript基础教程
- CentOS 7上通过Yum安装Percona Server 8.0.21教程
- C语言编程:锻炼计划设计与实现
- Python框架基准线创建与性能测试工具
- 6小时掌握JavaScript基础:深入解析与实例教程
- 专业技能工厂,培养数据科学家的摇篮
- 如何使用pg-dump创建PostgreSQL数据库备份
- 基于信任的移动人群感知招聘机制研究
- 掌握Hadoop:Linux下分布式数据平台的应用教程
- Vue购物中心开发与部署全流程指南
- 在Ubuntu环境下使用NDK-14编译libpng-1.6.40-android静态及动态库
