英语开放事件抽取数据集:挑战与改进
需积分: 0 49 浏览量
更新于2024-08-05
收藏 436KB PDF 举报
本文档介绍了一个名为"2016年开放事件提取数据集1"的专业资源,针对自然语言处理领域,特别是事件抽取任务。事件抽取是无监督学习中的一个重要课题,其目标是从未标记文本中自动学习模板,并识别出同一模板中对应相同角色的实体。以往的研究大多依赖于MUC-4语料库,但该数据集存在一些局限性,如规模较小、代表性不足以及模板中角色相似度较高。
作者指出,MUC-4语料库的限制在于其规模有限,可能无法全面反映现实世界中的事件多样性;此外,它在不同模板中的角色分布可能不够均衡,这可能会影响模型的泛化能力和对复杂事件结构的理解。为了克服这些问题,研究人员提出了一种新的部分标注的英语数据集。
这个新数据集的设计策略是基于Hanoi University of Science and Technology的研究团队,他们从维也纳的越南科学技术大学出发,利用了维基新闻(Wikinews)作为数据来源。选择法律与司法类别,研究人员精心筛选了相关文章,确保数据具有一定的专业性和信息多样性。同时,他们还通过Google搜索引擎收集了关于同一事件的不同文档,进一步增强了数据的异质性。
值得注意的是,尽管维基新闻文档是人工手动标注的,但并非所有内容都进行了详尽的标注,而是部分标记,这意味着它提供了一个介于完全无监督和全标注之间的学习环境,既有利于研究者探索半监督和弱监督的学习方法,又可以评估系统的性能和鲁棒性。
这个2016年开放事件提取数据集1为开发和测试英语事件抽取系统提供了新的挑战和机会,它不仅弥补了现有数据集的不足,而且促进了领域内更深入的理论探讨和技术进步。对于那些关注事件理解和信息抽取的科研人员而言,这个资源无疑是一份宝贵的工具。
A Dataset for Open Event Extraction in English
Kiem-Hieu Nguyen
1,∗
, Xavier Tannier
2
, Olivier Ferret
3
, Romaric Besanc¸on
3
1. Hanoi Univ. of Science and Technology, 1 Dai Co Viet, Hai Ba Trung, Hanoi, Vietnam
2. LIMSI, CNRS, Univ. Paris-Sud, Universit
´
e Paris-Saclay, rue John von Neumann, 91403 Orsay, France
3. CEA, LIST, Vision and Content Engineering Laboratory, F-91191, Gif-sur-Yvette, France
Abstract
This article presents a corpus for development and testing of event schema induction systems in English. Schema induction is the
task of learning templates with no supervision from unlabeled texts, and to group together entities corresponding to the same role in
a template. Most of the previous work on this subject relies on the MUC-4 corpus. We describe the limits of using this corpus (size,
non-representativeness, similarity of roles across templates) and propose a new, partially-annotated corpus in English which remedies
some of these shortcomings. We make use of Wikinews to select the data inside the category Laws & Justice, and query Google search
engine to retrieve different documents on the same events. Only Wikinews documents are manually annotated and can be used for
evaluation, while the others can be used for unsupervised learning. We detail the methodology used for building the corpus and evaluate
some existing systems on this new data.
Keywords: Event extraction, corpus creation, unsupervised methods.
1. Introduction
Information Extraction has been defined by the Message
Understanding Conference (MUC) evaluations (Grishman
and Sundheim, 1996) and its successors, i.e. the Automatic
Content Extraction (ACE) (Doddington et al., 2004) and
Text Analysis Conference (TAC) (Ellis et al., 2014)
evaluations, specifically by the task of template filling. The
objective of this task is to assign event roles to individual
textual mentions. A template defines a specific type
of events (e.g. earthquakes), associated with semantic
roles (or slots) hold by entities (for earthquakes, typically
their location, date, magnitude and the damages they
caused (Jean-Louis et al., 2011)). This kind of structures is
comparable to the schemas of (Schank and Abelson, 1977).
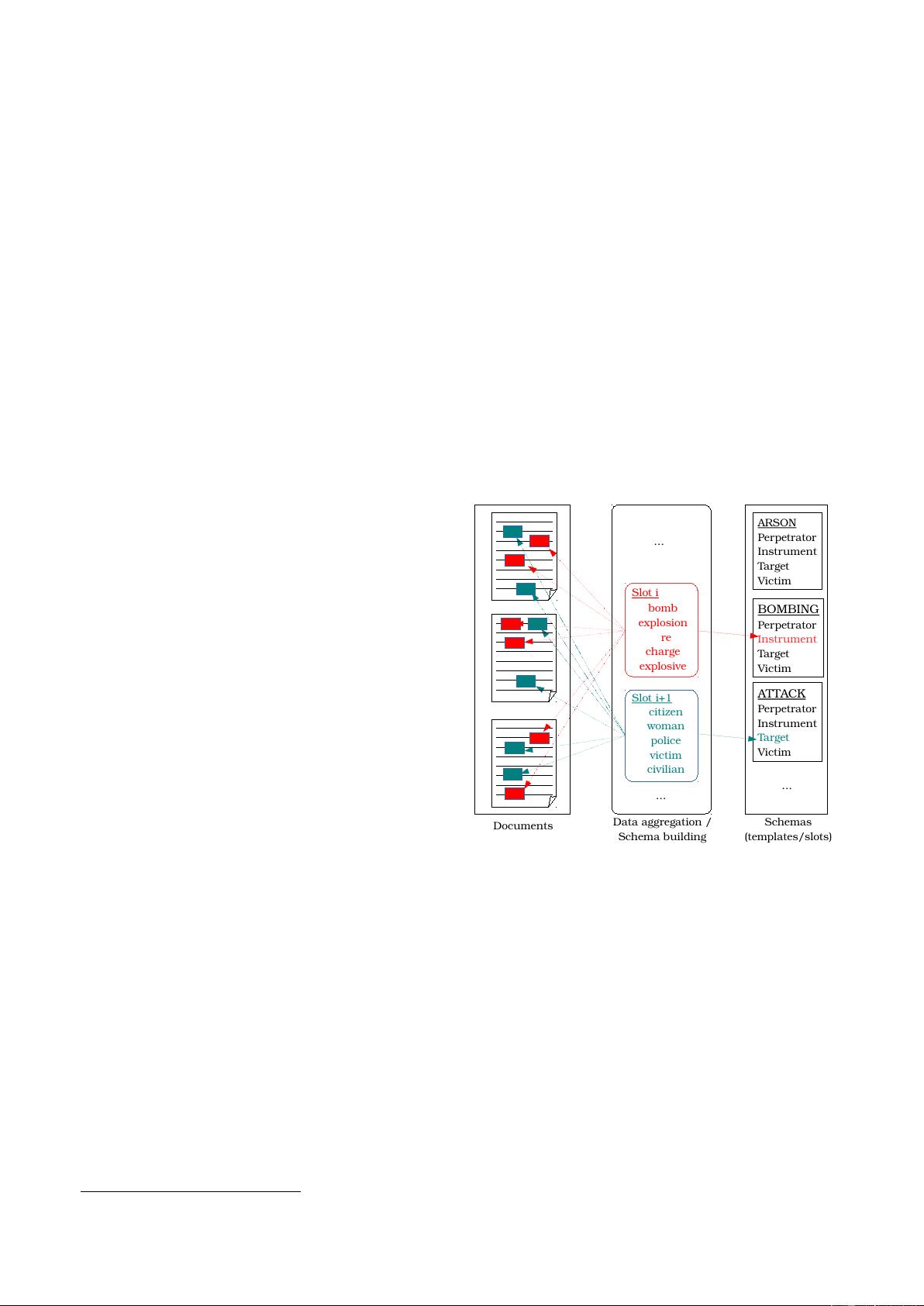
Schema induction is the task of learning these structures
with no supervision from unlabeled texts. We focus here
more specifically on event schema induction (Chambers
and Jurafsky, 2011; Chambers, 2013; Cheung et al., 2013;
Nguyen et al., 2015). The idea is to group entities
corresponding to the same role into an event template.
Figure 1 illustrates this process.
Previous work on event schema induction was evaluated
on the MUC-4 corpus (Grishman and Sundheim, 1996).
However, this corpus raises two main issues:
• It was annotated with templates describing all events
with the same set of slots.
• It doesn’t contain redundancy.
The first issue is clearly a limitation due to the fact that
all the considered types of events in the MUC-4 corpus
are close to each other while the second issue is more a
difficulty for applying current machine learning methods.
In this paper, we propose the ASTRE corpus in order to
tackle these two issues. We report experimental results on
∗ This author was affiliated at LIMSI-CNRS when working
on this project.
Slot i
Slot i+1
ATTACK
Perpetrator
Instrument
Target
Victim
BOMBING
Perpetrator
Instrument
Target
Victim
citizen
woman
police
victim
civilian
Documents
Schemas
(templates/slots)
bomb
explosion
re
charge
explosive
Data aggregation /
Schema building
ARSON
Perpetrator
Instrument
Target
Victim
...
...
...
Figure 1: Event induction process (MUC schema example).
this corpus using state-of-the-art event schema induction
methods. The rest of the paper is organized as follows.
Section 2 presents the MUC-4 corpus and its limitations
for evaluating schema induction. It also discusses its
successors, i.e. the ACE and TAC corpora. Section 3
describes the creation of the ASTRE corpus while Section 4
shows the evaluation results of two state-of-the-art systems
for open event extraction task on it. Finally, Section 5
concludes the paper.
2. MUC-4 Corpus
A significant part of the work in the field of event schema
induction from texts such as (Chambers and Jurafsky, 2011;
Chambers, 2013; Cheung et al., 2013; Nguyen et al.,
2015) relies on the MUC-4 corpus for its evaluation. This
corpus contains 1,700 news articles about terrorist incidents
happening in Latin America. The corpus is divided into
1939
下载后可阅读完整内容,剩余4页未读,立即下载
768 浏览量
730 浏览量
2024-04-14 上传
点击了解资源详情
116 浏览量
2925 浏览量
171 浏览量
2358 浏览量
218 浏览量

十二.12
- 粉丝: 41
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入解析JavaWeb中Servlet、Jsp与JDBC技术
- 粒子滤波在视频目标跟踪中的应用与MATLAB实现
- ISTQB ISEB基础级认证考试BH0-010题库解析
- 深入探讨HTML技术在hundeakademie中的应用
- Delphi实现EXE/DLL文件PE头修改技术
- 光线追踪:探索反射与折射模型的奥秘
- 构建http接口以返回json格式,使用SpringMVC+MyBatis+Oracle
- 文件驱动程序示例:实现缓存区读写操作
- JavaScript顶盒技术开发与应用
- 掌握PLSQL: 从语法到数据库对象的全面解析
- MP4v2在iOS平台上的应用与编译指南
- 探索Chrome与Google Cardboard的WebGL基础VR实验
- Windows平台下的IOMeter性能测试工具使用指南
- 激光切割板材表面质量研究综述
- 西门子200编程电缆PPI驱动程序下载及使用指南
- Pablo的编程笔记与机器学习项目探索
