深入理解Hadoop:分布式大数据处理系统
版权申诉
"该资源是关于云计算与大数据技术的PPT,主要讲解了Hadoop分布式大数据系统,包括Hadoop的概述、HDFS(Hadoop分布式文件系统)的详细内容、MapReduce编程框架及其C语言实现,以及如何建立Hadoop开发环境的步骤。"
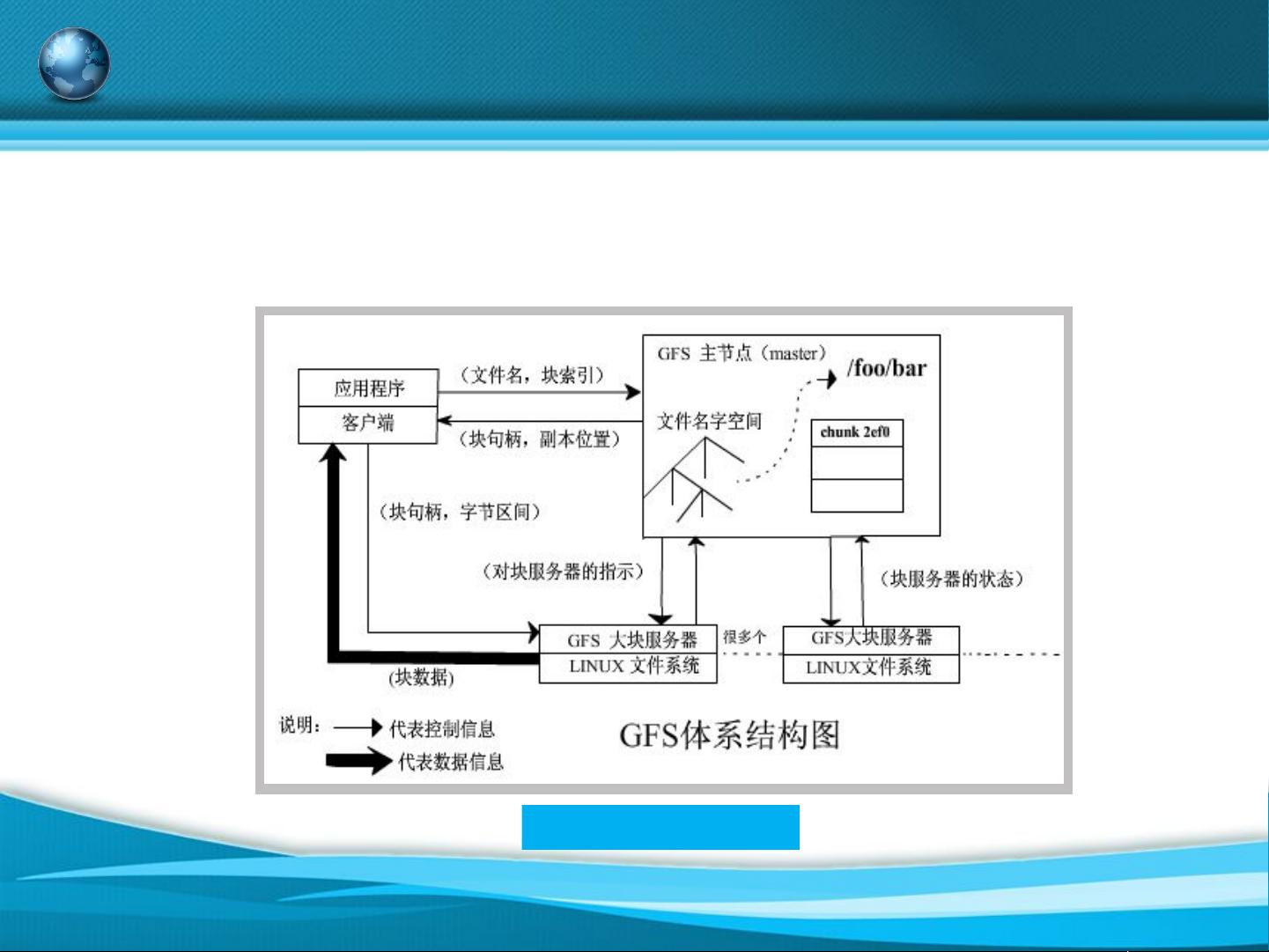
在Hadoop分布式大数据系统中,Hadoop是一个由Apache软件基金会开发的开源框架,设计目标是处理和存储大规模数据。Hadoop的核心组件主要包括两个:HDFS(Hadoop Distributed File System)和MapReduce。HDFS是分布式文件系统,它借鉴了Google的GFS(Google File System)原型,能够高效地存储海量数据,支持数据的高可用性和容错性。HDFS文件的基本结构包括名称节点(NameNode)和数据节点(DataNode),通过主从架构管理数据的存储和访问。
HDFS的存储过程涉及数据的切片、副本分配和数据恢复。文件被分割成多个块,每个块都会在集群的不同节点上保存多个副本,确保即使有节点故障,数据仍然可访问。MapReduce则是一种编程模型,用于大规模数据集的并行计算。它的历史可以追溯到Lisp中的函数式编程概念,通过“映射”(Map)和“化简”(Reduce)两个主要阶段来处理数据。
MapReduce的基本工作过程包括:首先,数据被分发到各个节点执行Map任务;然后,中间结果进行Shuffle和Sort;最后,Reduce任务在各个节点上执行,汇总全局结果。MapReduce的特点包括容错性、可扩展性和易于编程,适合批处理大量静态数据。
为了在本地环境中实现MapReduce和Hadoop,开发者需要进行一系列的准备工作,包括安装配置JDK,下载、解压Hadoop并设置环境变量,修改Hadoop的配置文件,如core-site.xml、hdfs-site.xml等,以便集群间的通信和数据存储。完成这些配置后,将配置好的Hadoop文件复制到其他节点,并启动Hadoop服务。通过运行经典的WordCount程序,可以验证Hadoop环境是否正确配置和运行。
这个PPT涵盖了Hadoop的基础知识,对于想要学习和掌握大数据处理技术的人来说,是一份非常实用的学习资料。


628 浏览量
399 浏览量
125 浏览量
149 浏览量
2635 浏览量
194 浏览量
138 浏览量
123 浏览量
2022-11-21 上传

安全方案
- 粉丝: 2794
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言实现LED灯控制的源码教程及使用说明
- zxingdemo实现高效条形码扫描技术解析
- Android项目实践:RecyclerView与Grid View的高效布局
- .NET分层架构的优势与实战应用
- Unity中实现百度人脸识别登录教程
- 解决ListView和ViewPager及TabHost的触摸冲突
- 轻松实现ASP购物车功能的源码及数据库下载
- 电脑刷新慢的快速解决方法
- Condor Framework: 构建高性能Node.js GRPC服务的Alpha框架
- 社交媒体图像中的抗议与暴力检测模型实现
- Android Support Library v4 安装与配置教程
- Android中文API合集——中文翻译组出品
- 暗组计算机远程管理软件V1.0 - 远程控制与管理工具
- NVIDIA GPU深度学习环境搭建全攻略
- 丰富的人物行走动画素材库
- 高效汉字拼音转换工具TinyPinYin_v2.0.3发布
