在华为鲲鹏服务器上的OpenMP MPI SIMD矩阵LU分解实验报告
需积分: 0 63 浏览量
更新于2024-01-08
收藏 7.72MB DOCX 举报
在本次《高性能计算》实验报告中,我们在华为鲲鹏服务器上进行了OpenMP MPI SIMD矩阵LU分解的课程设计实验。矩阵的LU分解是用于求解线性方程组的方法,通过一系列初等行变换将系数矩阵A分解为单位下三角阵L和上三角阵U的乘积,然后通过回代的方式求解线性方程组。本实验旨在通过并行计算的方式提高LU分解的计算效率,以应对大规模数据计算的需求。
我们选用了华为鲲鹏920处理器的Taishan 200服务器进行实验,该服务器具有高性能计算、大容量存储和出色的处理能力,适用于互联网、分布式存储、云计算、大数据等领域。我们在该硬件平台上进行了OpenMP MPI SIMD矩阵LU分解的性能测试和评估。
在实验过程中,我们首先实现了基于OpenMP的并行计算,利用其线程级并行特性对矩阵LU分解进行加速。同时,我们还使用MPI(Message Passing Interface)实现节点间的通信和数据传输,以实现分布式并行计算。在实现并行计算的基础上,我们进一步利用SIMD(Single Instruction, Multiple Data)指令集对计算过程进行优化,以充分发挥硬件的计算能力。
通过在鲲鹏服务器上进行并行计算的实验,我们观察到在处理大规模矩阵LU分解时,采用并行计算可以显著提高计算效率和加速求解过程。并行计算能够将计算任务分配给多个处理单元同时进行处理,充分利用了硬件资源,从而实现了更快速的计算速度和更高的计算吞吐量。
我们在实验中还对不同规模的矩阵进行了性能测试和评估,观察到随着矩阵规模的增大,采用并行计算的加速比也随之增加。这说明在处理大规模数据计算时,采用并行计算能够更好地发挥硬件平台的计算能力,为解决实际复杂问题提供了可行的解决方案。通过本次实验,我们深刻认识到了并行计算在高性能计算领域的重要性和应用前景。
综上所述,通过在华为鲲鹏服务器上进行OpenMP MPI SIMD矩阵LU分解的课程设计实验,我们深入理解了并行计算在高性能计算中的应用,以及其在处理大规模数据计算时的重要作用。并行计算能够提高计算效率、加速求解过程,为解决实际复杂问题提供了有力支持。我们对并行计算技术的应用前景充满信心,相信其将在未来的高性能计算领域发挥越来越重要的作用。
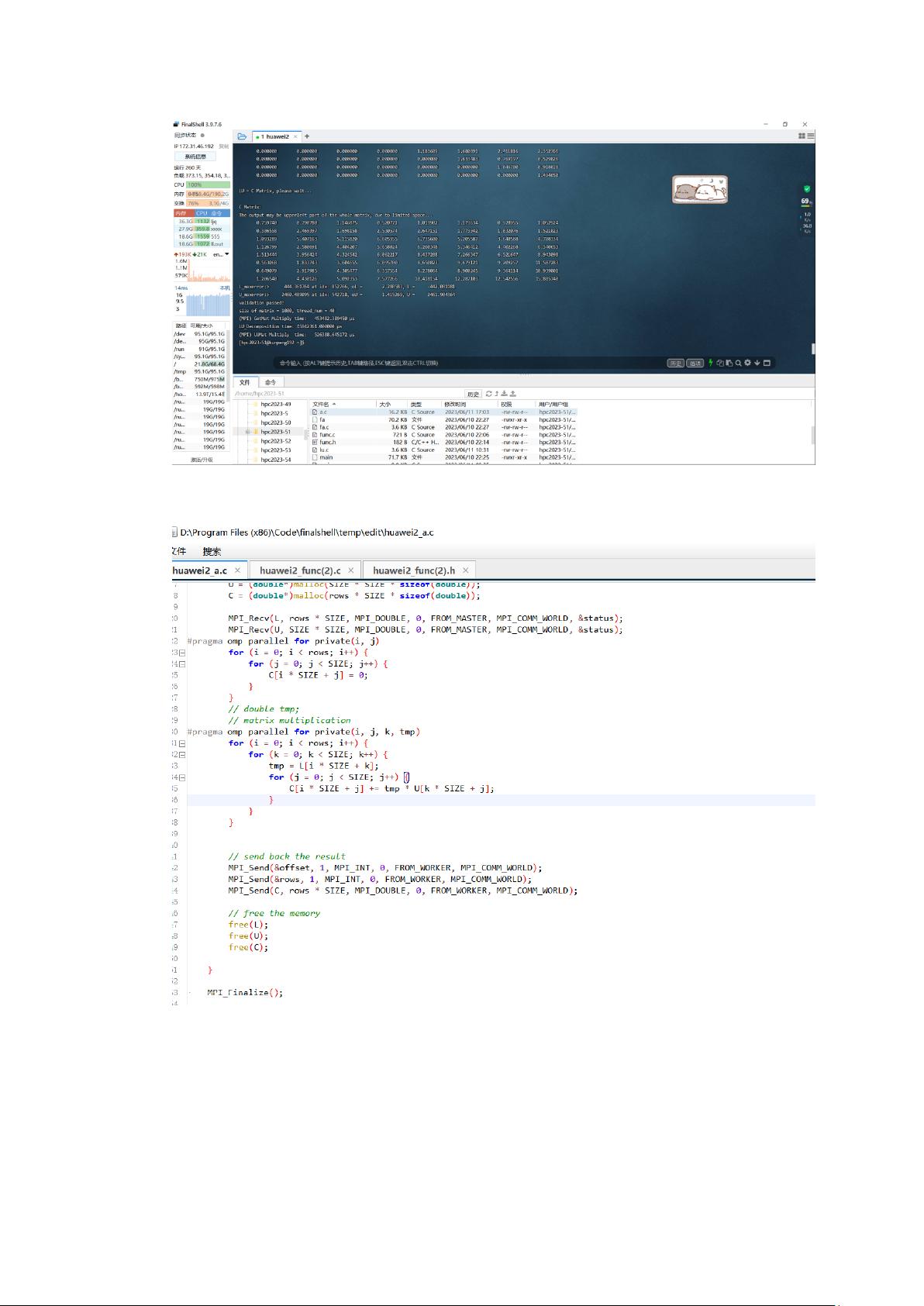
上图即为 FinalShell 使用效果图,可以清楚地查看服务器的状态,使用也比较方便
点击上图下方的一些文件,打开的内置的文档编辑器极大地方便了学生在 linux 环境下
的编程与调试
剩余22页未读,继续阅读
2023-06-08 上传
2024-05-28 上传
2023-11-07 上传
2023-09-25 上传
2021-09-12 上传
2023-05-05 上传

spicysama
- 粉丝: 3
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
