HBase on Persistent Memory:提升性能与可用性的关键
需积分: 5 76 浏览量
更新于2024-08-03
收藏 1.05MB PDF 举报
在2018年的HBaseConAsia会议上,于8月17日在北京Gehua新世纪酒店举办的活动探讨了如何将HBase技术与持久内存设备(Persistent Memory)相结合。这次研讨会由Anoop Sam John和Ramkrishna SVasudevan主持,主要关注了HBase现有的模型、性能优化以及在新型硬件支持下的改进。
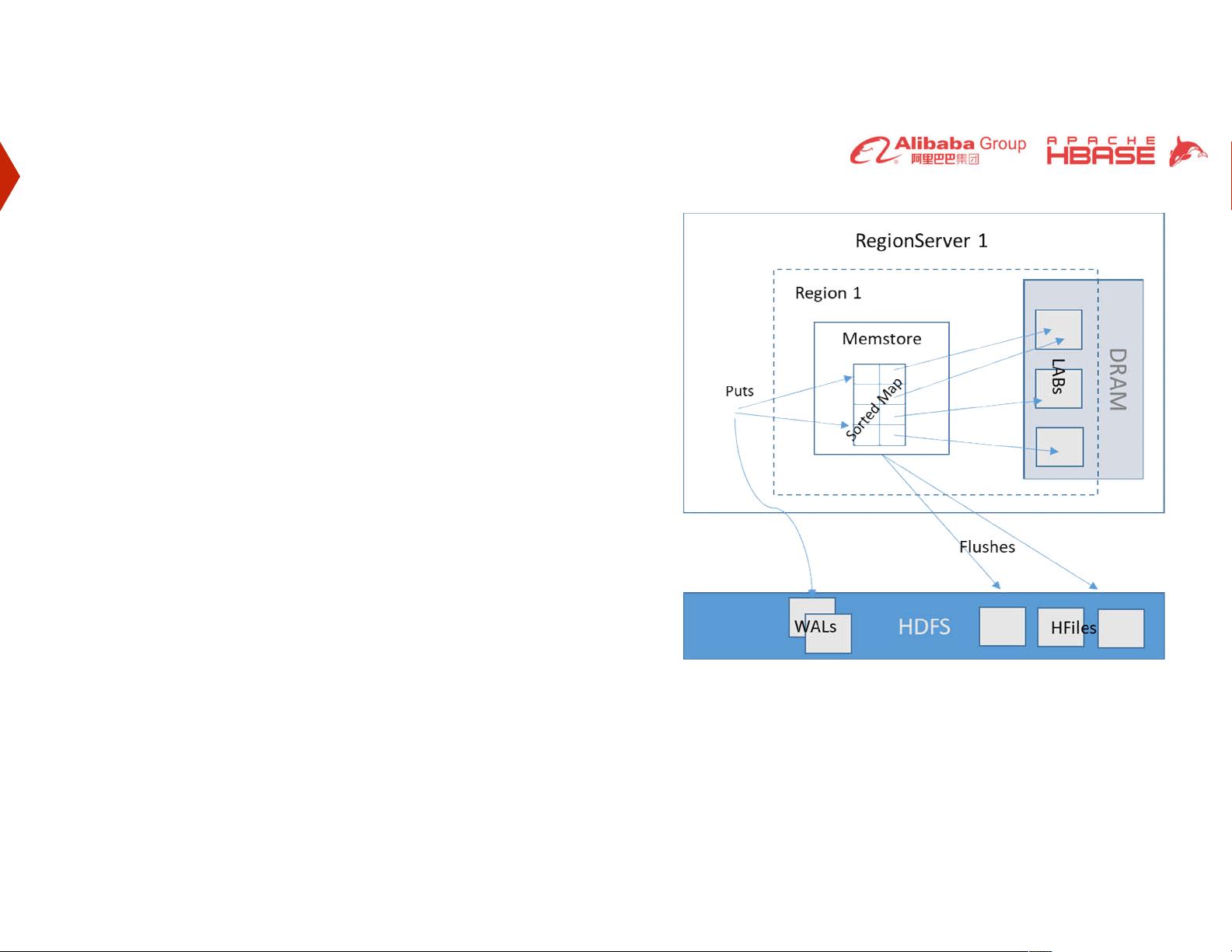
首先,HBase当前的架构模型基于存储数据在内存中的机制。它使用Sorted Map来组织数据,并利用Local Allocation Buffers (LABs) 存储在DRAM中的每个单元格的数据,其中默认的LAB大小为2MB。这种设计允许HBase快速访问数据,但同时也涉及到写入Write Ahead Log (WAL) 的过程,以确保数据持久化。然而,当内存达到预设阈值(默认为128MB)时,数据会强制写入HDFS,这可能导致额外的延迟,特别是在服务器故障恢复期间。
为了应对这种情况,HBase依赖于WAL记录数据以便在服务器崩溃后进行恢复。但是,这个过程可能造成数据不可用,直到WAL完全重放完毕,对于大型集群来说,这可能导致长时间的Mean Time To Recover (MTTR),有时甚至需要几分钟,这对阿里巴巴等用户(如在HBaseConAsia上反馈的)来说是一个挑战。
为了提高可用性,HBase考虑引入Region Replica策略。通过在其他副本服务器(RS)上设置只读副本区域,这些区域引用相同的HFiles在HDFS中,同时内存存储的数据也可以复制。此外,HBase还探索了使用WAL的读取复制路径,以减少对主节点的依赖,从而缩短恢复时间并提高系统的整体性能。
会议中讨论的主题涉及到了HBase在持久内存技术的支持下,如何通过优化数据布局、提高I/O效率以及减少数据一致性问题来提升其在高并发和大规模数据环境下的表现。参与者和听众期待着这些改进能够解决目前HBase在处理大量数据和性能方面面临的挑战,特别是在处理大型集群场景时的延迟和恢复时间问题。随着硬件技术的发展,HBase有望在未来的版本中更好地利用持久内存的优势,从而进一步提升整个云计算基础设施的效能。
hosted by
Apache HBase Present Model
Accumulate data in Memory
o Sorted Map
o Cell data bytes in Local Allocation Buffers (LABs) in DRAM
o LABs with size 2 MB in RAM.
Also write to Write Ahead Log (WAL)
o Cell data in Volatile RAM.
o To recover from server crash
o HDFS interaction adding more latency
hsync vs hflush - HBASE-19024
Flushes as files to HDFS on reaching memstores size
o 128 MB default flush size
Replay WAL on server crash
o Data unavailable till replay completes
o Large Mean Time To Recover (MTTR)
o Takes several minutes on large cluster (Complaint from many
users like Alibaba – HBaseConAsia , Huawei)
剩余10页未读,继续阅读
2023-08-28 上传
2023-09-10 上传
2023-08-30 上传
2023-09-09 上传
2023-09-09 上传
2023-09-09 上传
2023-09-01 上传
2023-09-09 上传

weixin_40191861_zj
- 粉丝: 83
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ Qt影院票务系统源码发布,代码稳定,高分毕业设计首选
- 纯CSS3实现逼真火焰手提灯动画效果
- Java编程基础课后练习答案解析
- typescript-atomizer: Atom 插件实现 TypeScript 语言与工具支持
- 51单片机项目源码分享:课程设计与毕设实践
- Qt画图程序实战:多文档与单文档示例解析
- 全屏H5圆圈缩放矩阵动画背景特效实现
- C#实现的手机触摸板服务端应用
- 数据结构与算法学习资源压缩包介绍
- stream-notifier: 简化Node.js流错误与成功通知方案
- 网页表格选择导出Excel的jQuery实例教程
- Prj19购物车系统项目压缩包解析
- 数据结构与算法学习实践指南
- Qt5实现A*寻路算法:结合C++和GUI
- terser-brunch:现代JavaScript文件压缩工具
- 掌握Power BI导出明细数据的操作指南
