B树、B-树、B+树与B*树:数据结构特征详解
需积分: 3 160 浏览量
更新于2024-08-03
收藏 328KB PDF 举报
本文将详细介绍数据结构中的四种重要变种——B树、B-树、B+树和B*树。这些数据结构都是基于二叉搜索树的概念,但各自具有独特的设计和特性,使得它们在数据库和文件系统中发挥着关键作用。
**B树(Binary Tree)**:
B树是一种二叉搜索树,非叶子节点最多有两个子节点(左和右)。每个节点存储一个关键字,并遵循左指针指向小于当前关键字的子树,右指针指向大于关键字的子树。搜索时,从根节点开始,根据关键字大小递归地比较并定位到目标。B树的优势在于插入和删除操作通常具有常数开销,无需大规模数据移动,有利于维护高效的数据索引。
**B-树 (B-TREE)**:
B-树是一种多路搜索树,非叶子节点的子节点数量在[2,M]之间,其中M>2,且根节点的儿子数范围更大。每个节点可以存储多于两个关键字,最少为M/2-1个,同时每个非叶子节点的关键字数量等于指向儿子的指针数量减一。所有叶子节点位于同一层级,搜索过程类似于二分查找,但根据节点内关键字有序序列进行。B-树的特性包括关键字均匀分布在树中,以及平衡性,通过平衡算法确保插入和删除操作的效率。
**B+树 (B+ TREE)**:
B+树是对B树的一种优化,它所有的叶子节点都在同一层,形成一个连续的链表,这有助于磁盘I/O的优化。内部节点只存储指向叶子节点的指针,不包含实际数据,使得搜索、插入和删除操作主要在叶子节点进行,减少了磁盘访问次数。B+树非常适合用于文件系统和数据库索引。
**B*树 (B* TREE)**:
B*树是B+树的一个简化版本,它省去了非叶子节点的键,只保留了指向叶子节点的指针。这种设计进一步降低了内部节点的复杂度,但可能会牺牲一些查找性能。B*树适用于内存空间有限但需要频繁插入和删除的场景。
选择B树、B-树、B+树还是B*树,取决于具体的应用需求,如数据的密集程度、磁盘I/O的优化、插入和删除操作的频率等因素。在实际应用中,这些数据结构都伴随着特定的平衡算法,如AVL树、红黑树等,来维持树的平衡,确保查询性能。理解这些数据结构的特性及其在不同场景下的优劣,对于优化数据库和文件系统的设计至关重要。
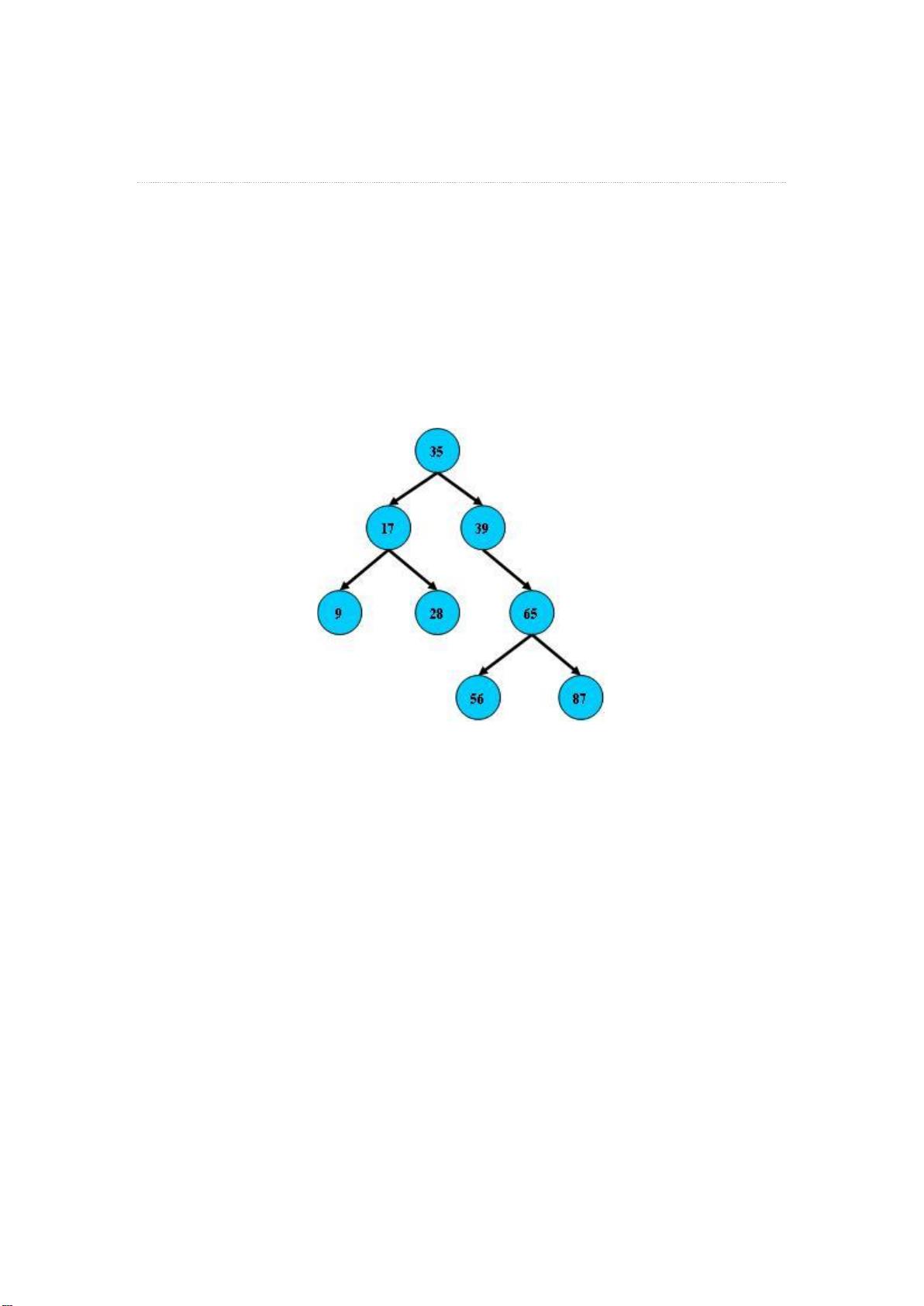
B 树、B-树、B+树、B*树
B 树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left 和 Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
B 树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入
右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果 B 树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么 B 树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变 B 树结构
(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
下载后可阅读完整内容,剩余5页未读,立即下载
2022-09-24 上传
2021-09-17 上传
2022-08-08 上传
2021-02-06 上传
2022-09-24 上传
2022-09-19 上传
2019-08-03 上传
2013-01-22 上传
2022-09-14 上传

shandongwill
- 粉丝: 5745
- 资源: 676
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
