Flink统一引擎运行时改进:阿里巴巴的实践与未来
需积分: 9 130 浏览量
更新于2024-07-17
收藏 19.9MB PDF 举报
"FlinkForwardChina2018RuntimeImprovementsforFlinkasaUnifiedEngine.pdf"
这篇文章主要讨论了Apache Flink在2018年FlinkForward China大会上的运行时改进,以及它作为统一处理引擎的发展。阿里巴巴在大规模使用Flink进行实时计算和流处理方面扮演了重要角色,并对其进行了深入优化。
1. **Flink在阿里巴巴**
阿里巴巴是Flink的重要使用者,拥有超过10,000节点的集群,处理PB级别的状态数据,每天处理万亿级别的事件,每秒处理4.72亿条事务(TPS)。阿里内部开发了FOAS(Flink Open Api Service)和Dataphin Streaming等工具,用于支持流式计算、BI分析、推荐系统、搜索等多个业务场景。
2. **统一处理的新Flink API栈**
新的Flink API栈旨在实现统一的批处理和流处理。DataStream API专注于流处理,而DataSet API用于批处理。同时,引入了Table API和SQL,提供了关系型查询接口,使得用户可以使用统一的API处理流和批数据。新架构下,JobGraph、StreamGraph和OptimizationPlan分别对应于任务图、流图和优化计划。
3. **Flink运行时改进**
Flink的运行时优化包括分布式流数据处理、YARN集群管理以及对HDFS的支持。Flink的分布式流数据处理模型(DistributedStreamingDataFlow)确保了高并发和低延迟。此外,还有针对操作符树的StreamTransform和任务执行层面的StreamTask与BatchTask的优化。
4. **未来规划**
文档中提到了未来的计划,可能涉及到进一步提升性能、优化API以简化使用,以及适应更多云环境(如EC2/GCE),这表明Flink将持续演进以满足更广泛的计算需求。
5. **总结**
Flink在阿里巴巴的实践展示了其在大规模实时处理中的能力,新的API栈设计反映了对统一处理的追求,而运行时改进则强化了其作为高效流处理引擎的地位。这些发展为开发者提供了更加灵活和强大的工具,推动了大数据处理技术的进步。
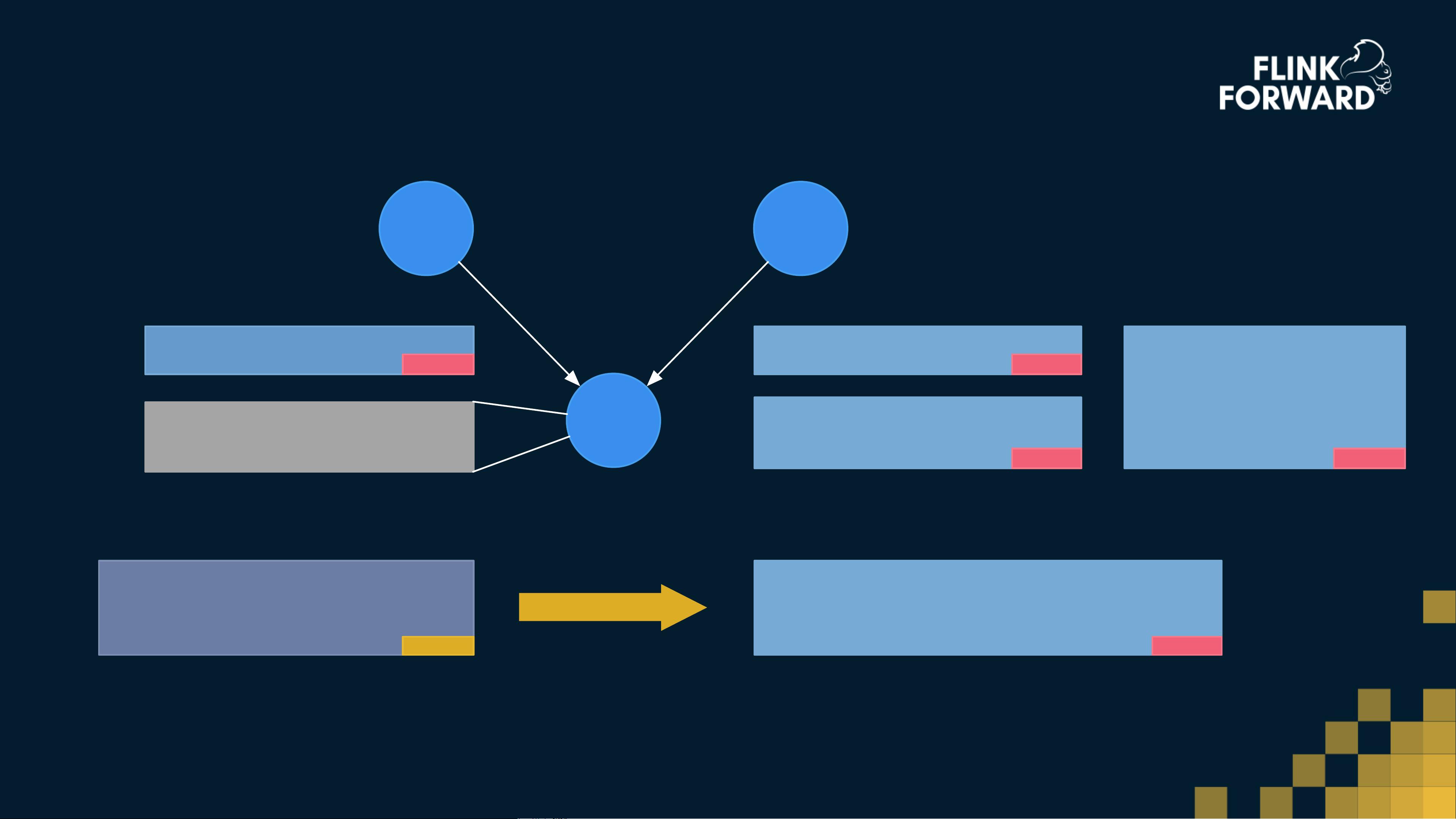
Proposed New Flink API Stack
DataStream
Streaming
Runtime
Distributed Streaming DataFlow
DataSet
Batch
Local
Single JVM
Cluster
Standalone/Yarn
Cloud
EC2/GCE
Table & SQL
Relational
DAG & StreamOperator
Unified Core API
DataStream API
Streaming Process
Runtime
Distributed Streaming DataFlow
DataSet API
Batch Process
Table API & SQL
Relational
Local
Single JVM
Cluster
Standalone/Yarn
Cloud
EC2/GCE
OLD NEW
剩余44页未读,继续阅读
2019-08-29 上传
2019-08-29 上传
2019-08-29 上传
2019-08-29 上传
2019-08-29 上传
2019-08-29 上传
2021-10-05 上传
2019-08-29 上传
2019-08-29 上传

weixin_38743968
- 粉丝: 404
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
