爬虫精进:从入门到精通的知识笔记
需积分: 9 71 浏览量
更新于2024-07-09
收藏 3.66MB PDF 举报
"该资源是一份关于爬虫精进的学习笔记合集,涵盖了从第0关到第15关的逐步提升内容。笔记中详细介绍了爬虫的基本概念、工作原理,以及如何使用requests库进行数据获取和处理。此外,还提到了网站链接的更新情况,并提供了用于练习的账号和密码。"
在爬虫技术的学习过程中,了解和掌握以下几个关键知识点至关重要:
1. **浏览器的工作原理**:
浏览器通过HTTP或HTTPS协议与服务器交互,发送请求(Request)获取资源(Response),渲染HTML页面,展示给用户。这个过程包括DNS解析、建立TCP连接、发送请求、接收响应、关闭连接等步骤。
2. **爬虫的工作原理**:
爬虫程序模拟浏览器的行为,通过编程方式自动发送HTTP请求到服务器,接收响应数据,解析HTML或其他格式的数据,提取所需信息,最后将这些信息存储在本地数据库或文件中。
3. **爬虫的四个步骤**:
- **第0步:获取数据** - 使用如requests这样的库,向目标URL发送GET请求,获取网页的HTML源码。
- **第1步:解析数据** - 解析获取的HTML,通常使用BeautifulSoup、lxml等库,将HTML转换成可操作的对象结构。
- **第2步:提取数据** - 从解析后的数据中定位并提取有价值的信息,如特定标签内的文本、属性值等。
- **第3步:储存数据** - 将提取到的数据保存在合适的格式,如CSV、JSON,或者存储到数据库中。
4. **requests.get()函数**:
requests库的get()函数是Python爬虫中常用的方法,用于发送HTTP GET请求。它接受一个URL作为参数,返回一个Response对象,其中包含了服务器的响应信息。例如:
```python
import requests
res = requests.get('http://example.com')
```
Response对象包含状态码、头部信息、cookies、数据等内容,可以通过`res.text`或`res.content`访问响应的文本或二进制数据。
5. **实战练习与账号**:
学习笔记中提到的“人人都是蜘蛛侠”网站可能提供实践平台,账号为spiderman,密码为crawler334566,供学习者进行爬虫编程练习。
在实际爬虫项目中,还需要考虑反爬虫策略、IP代理、数据清洗、异常处理、多线程/异步请求等高级技巧。同时,要遵守相关法律法规,尊重网站的robots.txt协议,合法合规地进行数据抓取。随着学习深入,你还可以探索Scrapy框架、Selenium、Puppeteer等工具,以及更复杂的网络请求库,如aiohttp,来实现更高效、更智能的爬虫。
知识一:BeautifulSoup是什么
1.作用:解析和提取网页中的数据。
解析数据:把服务器返回来的HTML源代码翻译为能看懂的样子
提取数据:把我们需要的数据从众多数据中挑选出来
2.安装模块:pipinstallBeautifulSoup4(Mac电脑需要输入pip3install
BeautifulSoup4)
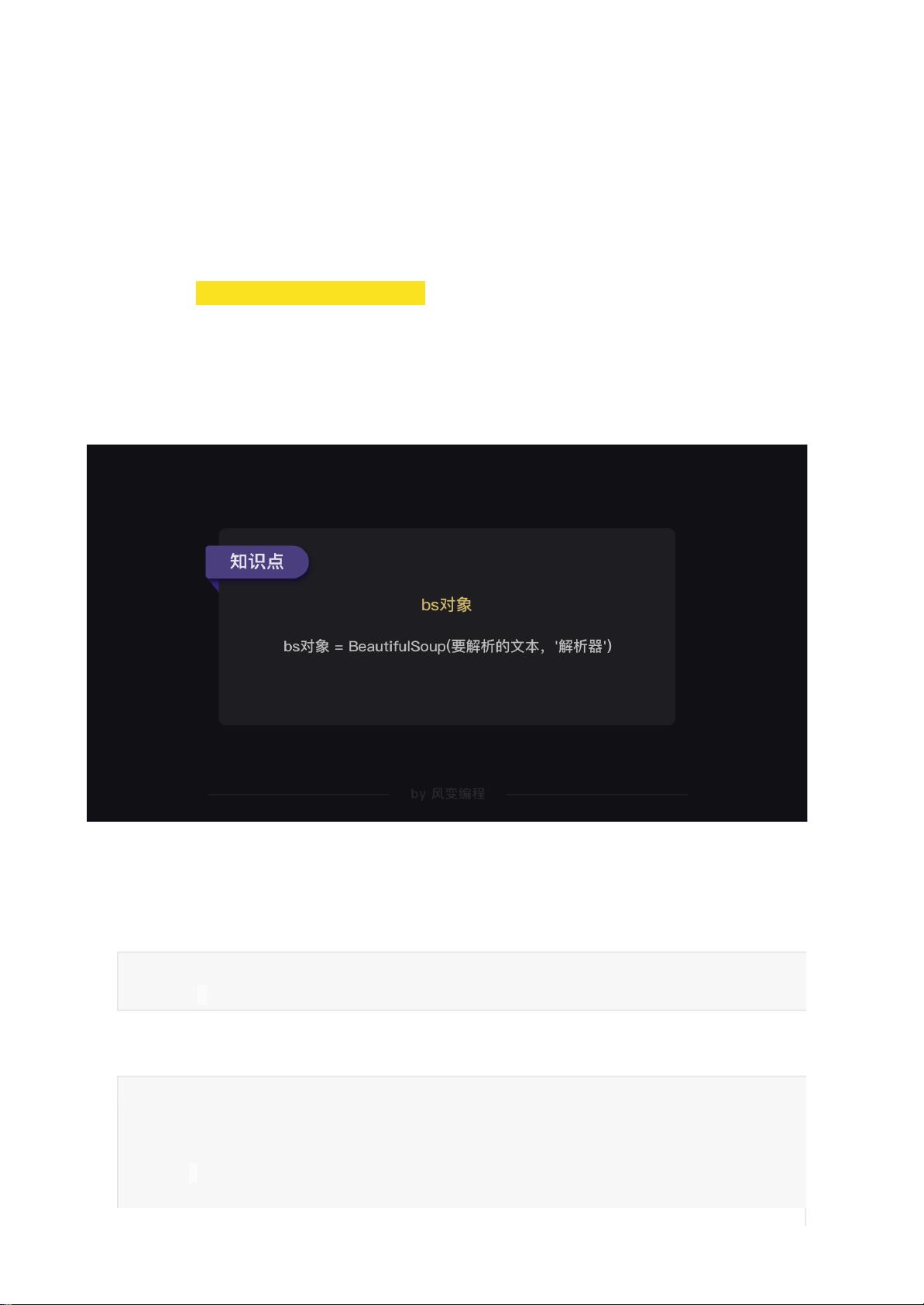
知识二:解析数据
1.格式
第0个参数是要被解析的文本,必须是字符串
第1个参数用来标识解析器,我们要用的是一个Python内置库:html.parser(它不是唯一
的解析器,但是比较简单的)
1 frombs4importBeautifulSoup
2 soup=BeautifulSoup(字符串,'html.parser')
实例:
1 importrequests
2 frombs4importBeautifulSoup#引入BS库
3
4 res=requests.get('https://localprod.pandateacher.com/python‐manuscript/
crawler‐html/spider‐men5.0.html')


剩余63页未读,继续阅读
2022-06-20 上传
2022-06-06 上传
2021-07-02 上传
2022-07-10 上传
2022-11-19 上传
2022-12-01 上传
2022-06-23 上传
2022-11-20 上传
2022-11-24 上传

huxujia2008
- 粉丝: 0
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
