CUDA:GPU并行计算的利器与应用
需积分: 9 48 浏览量
更新于2024-07-21
收藏 490KB PDF 举报
CUDA,全称为Compute Unified Device Architecture,是由NVIDIA公司于2007年6月推出的一种用于利用图形处理器(GPU)进行通用并行计算的技术框架。它允许开发者将原本在中央处理器(CPU)上执行的计算密集型任务转移到GPU上,以提升性能和效率。
CUDA的核心理念是利用GPU的高度并行性和大量核心来加速那些可以分解为大量独立任务的计算过程。GPU的设计初衷是为图形渲染提供强大的并行处理能力,但CUDA将其扩展到通用计算领域,使得诸如科学计算、数值模拟、机器学习等任务也能受益于GPU的性能优势。
在CUDA编程模型中,CPU通常扮演主机角色,负责控制整个程序的串行逻辑和任务调度,而GPU则作为协处理器或设备,执行那些可以被高度线程化和并行化的计算部分。程序员通过编写内核函数(Kernel)实现这些并行操作,内核函数类似于C语言中的函数,但它们是在GPU设备上运行的。内核函数的调用使用`<<<>>>`执行配置运算符,如`testkernel<<<dimgrid,dimblock>>>(d_A,d_B,d_C);`,其中`dimgrid`和`dimblock`分别定义了全局网格和块的维度,`threadIdx`和`blockIdx`则是线程和块的索引。
CUDA支持多种数据类型的限定符,如 `_device_`(显存)、`_shared_`(共享内存)、`_constant_`(常量内存),用于指定数据存储的位置,以便优化内存访问和提高性能。此外,CUDA还提供了五个内建变量,如`gridDim`、`blockDim`、`blockIdx`、`threadIdx`和`warpSize`,帮助开发者管理和组织计算任务的执行。
决定是否使用GPU并行计算的关键因素通常包括大数据量处理的需求和计算任务的并行性。当需要处理的数据量巨大,且任务可以通过分割成多个独立的子任务并行执行时,CUDA可以显著提升计算速度。应用领域广泛,包括石油勘测、天文计算、流体力学模型、生物计算、图像处理、视频编码和解码等。
CUDA为程序员提供了一种将计算负载转移到GPU的强大工具,通过巧妙地利用GPU的并行架构,实现了高性能的并行计算,极大地推动了现代计算机科学和信息技术的发展。
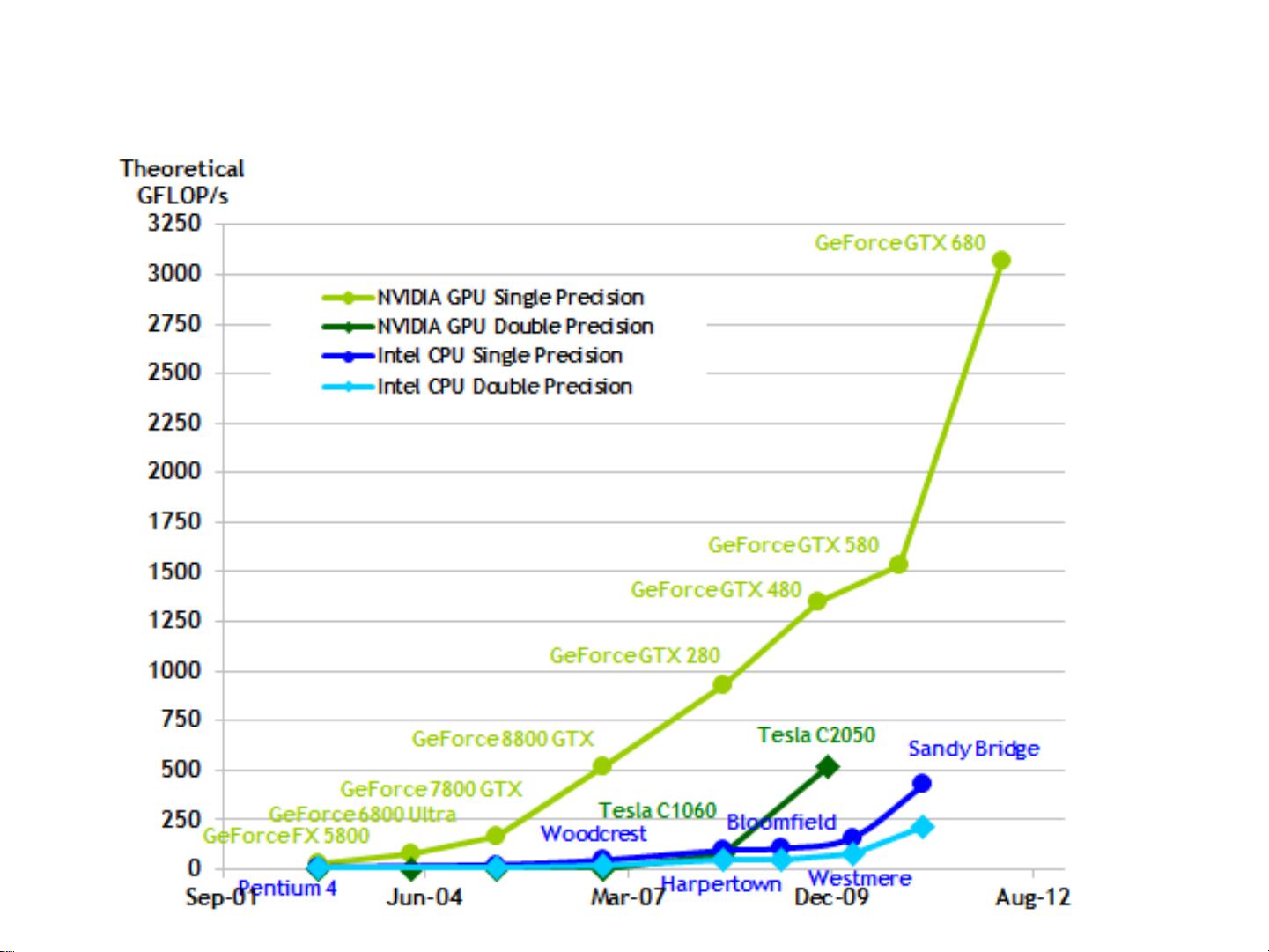
浮点计算能力
剩余14页未读,继续阅读
2012-01-12 上传
2021-05-23 上传
2023-06-07 上传
2023-06-06 上传
2023-03-30 上传
2023-07-23 上传
2023-06-06 上传
2023-06-04 上传
2023-06-07 上传

甜粽_86
- 粉丝: 3
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
