深度学习实践:过拟合与欠拟合解决方案、梯度问题及Kaggle房价预测
10 浏览量
更新于2024-08-30
收藏 149KB PDF 举报
"该资源是动手学深度学习的第二次打卡作业,涵盖了过拟合、欠拟合的解决方案,以及梯度消失、梯度爆炸问题,同时提到了在Kaggle房价预测实战中需要考虑的因素。内容包括权重衰减、L2范数正则化等技术,并提供了使用Python和PyTorch进行数据处理的代码示例。"
正文:
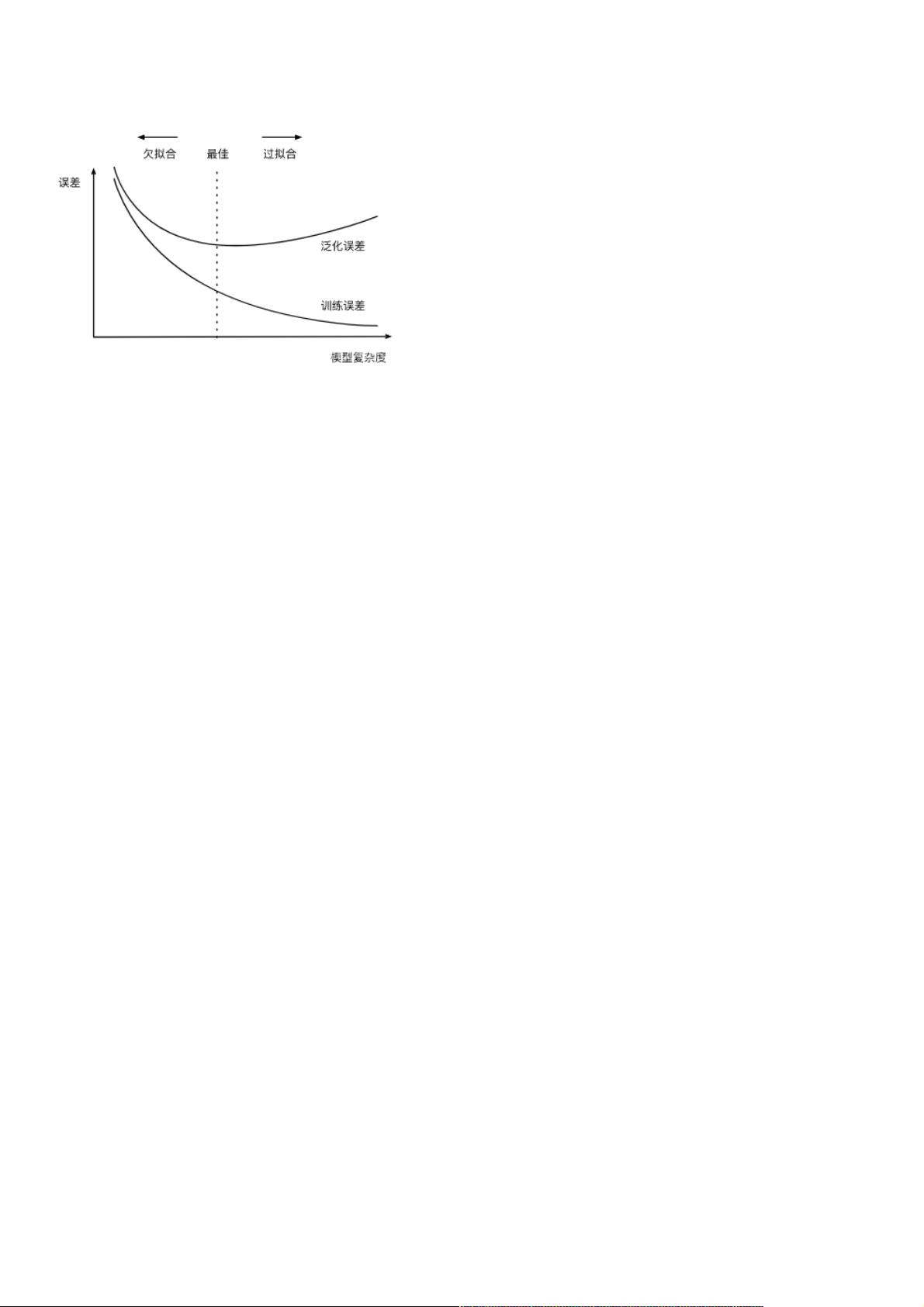
深度学习中,过拟合和欠拟合是两个关键问题,它们直接影响模型的泛化能力。过拟合是指模型在训练数据上表现优秀,但在未见过的数据(测试集)上表现糟糕,这通常是因为模型过于复杂,过度学习了训练数据中的噪声和特有模式。而欠拟合则是模型无法捕获数据中的复杂关系,表现为训练和测试性能都较差。
为了解决过拟合,通常采用以下策略:
1. 验证数据集和交叉验证:通过将数据集划分为训练集、验证集和测试集,可以在训练过程中监控模型在验证集上的性能,避免过拟合。交叉验证进一步通过多次划分和训练,提高模型的稳健性。
2. 权重衰减(Weight Decay):这是L2范数正则化的另一种说法。在优化目标函数中添加权重参数的平方和,即L2范数,可以限制权重的大小,防止模型过于复杂。当λ(正则化参数)增大时,模型会倾向于较小的权重值,从而减少过拟合的风险。若λ为0,则没有正则化效果。
对于深度学习中常见的梯度消失和梯度爆炸问题,它们主要出现在多层神经网络中。梯度消失是指深层网络中,反向传播过程中梯度变得极小,导致权重更新几乎停止,学习缓慢。梯度爆炸则是梯度值过大,可能使权重参数超出合理范围,同样阻碍学习。这两种情况都可能导致训练困难。
为解决这些问题,可以采取以下措施:
1. 使用激活函数如ReLU(Rectified Linear Unit),它解决了sigmoid和tanh等函数在某些区域梯度接近于0的问题。
2. 初始化权重:如Xavier初始化或He初始化,这些方法有助于在前向传播中保持每一层的输出方差大致相等,从而减缓梯度消失。
3. 批量归一化(Batch Normalization):对每一层的输入进行标准化,稳定梯度流,加速训练。
在实际应用,如Kaggle房价预测任务中,除了模型结构和训练策略,还需要注意以下环境因素:
1. 协变量偏移(Covariate Shift):训练数据和测试数据的分布不一致,可能需要持续更新模型以适应新的数据分布。
2. 标签偏移(Label Shift):不同数据集的标签分布不同,需要对模型的预测概率进行调整。
3. 概念偏移(Concept Drift):随着时间推移,数据的含义或相关性发生变化,模型需具备一定的适应性。
在给定的代码片段中,可以看到使用了`pandas`进行数据读取和预处理,包括标准化数值特征和处理缺失值,这些都是深度学习中数据预处理的常见步骤。`torch`库用于构建和训练神经网络模型,这里已经设置了默认的张量类型为`torch.FloatTensor`,并加载了数据集。然而,完整的模型定义和训练过程并未给出。在实际操作中,你可能需要构建一个适当的神经网络架构,如使用卷积神经网络(CNN)或循环神经网络(RNN),并结合优化器、学习率调度等策略进行模型训练。
动手学深度学习第二次打卡动手学深度学习第二次打卡2/18
task3 task4 and task5
1.过拟合、欠拟合及其解决方案
解决方法包括:验证数据集和交叉验证
权重衰减
L2 范数正则化(regularization)
例如在线性回归中加入带有l2范数惩罚项的损失函数。
当 λ 较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当 λ 设为0时,惩罚项完全不起
作用。
2.(1)梯度消失、梯度爆炸以及Kaggle房价预测
当神经网络的层数较多时,模型的数值稳定性容易变差
(2)考虑环境因素
协变量偏移
标签偏移
概念偏移
Kaggle 房价预测实战
%matplotlib inline
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
torch.set_default_tensor_type(torch.FloatTensor)
获取和读取数据集
test_data = pd.read_csv("/home/kesci/input/houseprices2807/house-prices-advanced-regression-techniques/test.csv")
train_data = pd.read_csv("/home/kesci/input/houseprices2807/house-prices-advanced-regression-techniques/train.csv")
预处理数据
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 标准化后,每个数值特征的均值变为0,所以可以直接用0来替换缺失值
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# dummy_na=True将缺失值也当作合法的特征值并为其创建指示特征
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
#转为tersor
n_train = train_data.shape[0] train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float)
train_labels = torch.tensor(train_data.SalePrice.values, dtype=torch.float).view(-1, 1)
训练模型
loss = torch.nn.MSELoss()
def get_net(feature_num):
net = nn.Linear(feature_num, 1)
for param in net.parameters():
nn.init.normal_(param, mean=0, std=0.01)
return net
下载后可阅读完整内容,剩余6页未读,立即下载
2021-01-06 上传
2020-03-15 上传
2021-01-06 上传
2021-01-20 上传
2021-01-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38686542
- 粉丝: 1
- 资源: 938
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
