Faster R-CNN:实现实时目标检测的区域提议网络
需积分: 9 101 浏览量
更新于2024-09-09
收藏 1.15MB PDF 举报
Faster R-CNN是计算机视觉领域的一项重要突破,它首次将区域提议网络(Region Proposal Network, RPN)与目标检测网络紧密整合,实现了实时物体检测的重大进展。该论文发表于《模式分析与机器智能》(IEEE Transactions on Pattern Analysis and Machine Intelligence)期刊,由Shaoqing Ren、Kaiming He、Ross Girshick和Jian Sun等人共同完成。
传统的物体检测网络依赖于区域提议算法来猜测目标物体的位置,这些方法如SPPnet[1]和Fast R-CNN[2]虽然显著提高了检测速度,但区域提议计算成为了瓶颈。Faster R-CNN的核心创新在于引入了RPN,这是一个全卷积网络,它与检测网络共享整个图像的卷积特征。这样,RPN可以在几乎无额外成本的情况下生成高质量的区域提议,极大地提高了检测效率。
RPN的特点是能够同时在每个位置预测对象边界框(bounding box)和对象的存在概率(objectness score),并实现了端到端的训练。这意味着RPN能够指导检测网络专注于最有前景的区域,就像神经网络中的“注意力机制”一样。这种集成设计使得Faster R-CNN能够在保持准确性的同时,实现更高的检测速度,特别是在非常深的模型,如VGG-16[3],其检测速度可以达到每秒5帧(fps),这在当时是一个相当显著的进步。
通过RPN和Fast R-CNN的合并,Faster R-CNN克服了传统方法中单独处理区域提议和检测两个阶段的局限性,显著提升了整体系统的性能。这一工作不仅优化了计算机视觉任务的执行效率,也为后续的研究者们提供了构建高效实时检测系统的新思路和框架,对现代物体检测技术的发展产生了深远影响。
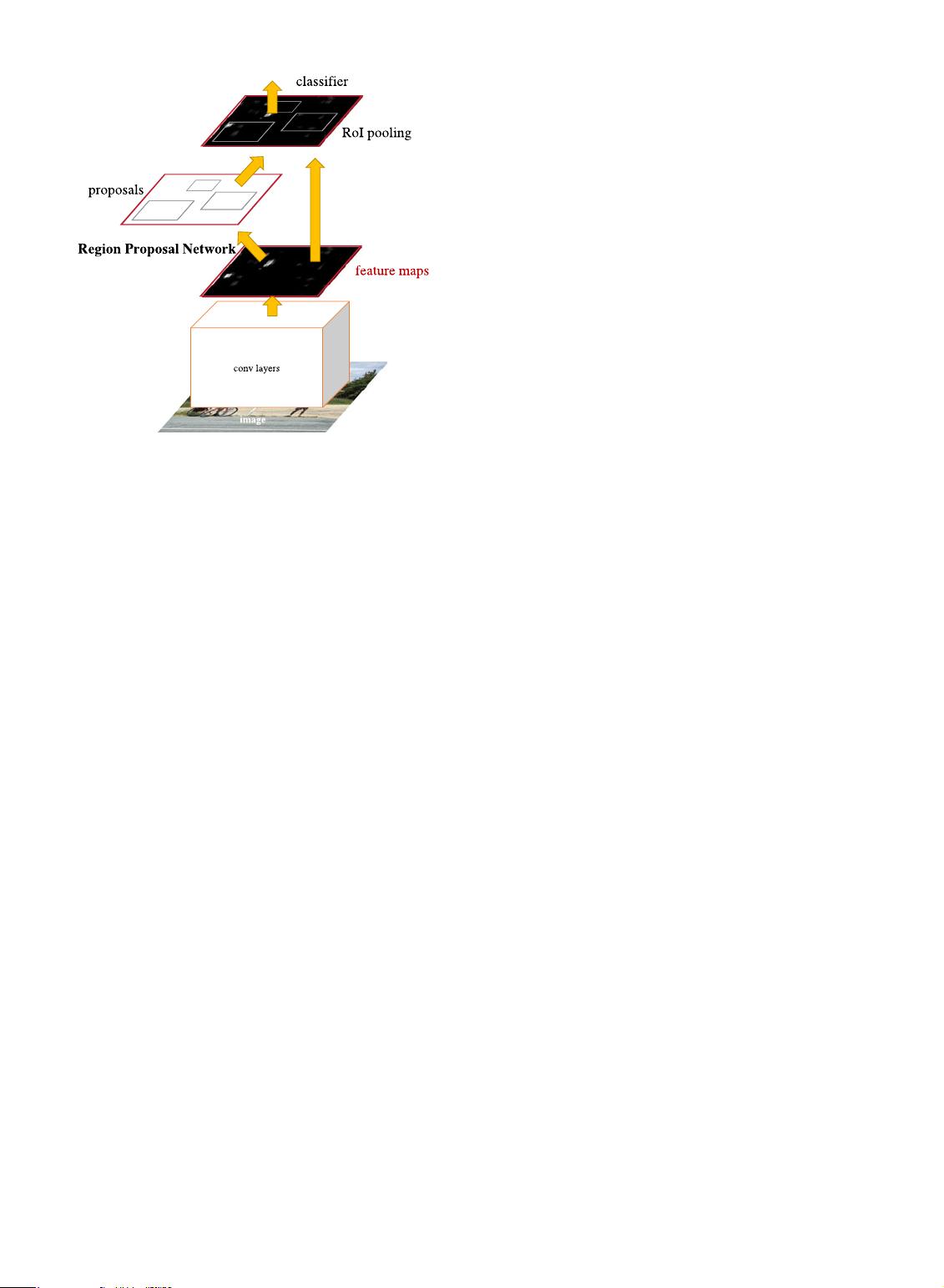
second module is the Fast R-CNN detector [2] that uses the
proposed regions. The entire system is a single, unified net-
work for object detection (Fig. 2). Using the recently popular
terminology of neural networks with ‘attention’ [31] mecha-
nisms, the RPN module tells the Fast R-CNN module where
to look. In Section 3.1 we introduce the designs and proper-
ties of the network for region proposal. In Section 3.2 we
develop algorithms for training both modules with features
shared.
3.1 Region Proposal Networks
A Region Proposal Network takes an image (of any size)
as input and outputs a set of rectangular object proposals,
each with an objectness score.
3
We model this process
with a fully convolutional network [7], which we describe
in this section. Because our ultimate goal is to share com-
putation with a Fast R-CNN object detection network [2],
we assume that both nets share a common s et of convolu-
tional layers. In our experiments, we investigate the
Zeiler and Fergus model [32] (ZF), whic h has five share-
able convolutional layers and the Simo nyan and Zisser-
man model [3] (VGG-16), which has 13 sha reable
convolutional layers.
To generate region proposals, we slide a small network
over the convolutional feature map output by the last
shared convolutional layer. This small network takes as
input an n n spatial window of the input convolutional
feature map. Each sliding window is mapped to a lower-
dimensional feature (256-d for ZF and 512-d for VGG, with
ReLU [33] following). This feature is fed into two sibling
fully-connected layers—a box-regression layer (reg) and a
box-classification layer (cls). We use n ¼ 3 in this paper,
noting that the effective receptive field on the input image
is large (171 and 228 pixels for ZF and VGG, respectively).
This mini-network is illustrated at a single position in
Fig. 3 (left). Note that because the mini-network operates
in a sliding-window fashion, the fully-connected layers are
shared across all spatial locations. This architecture is natu-
rally implemented with an n n convolutional layer fol-
lowed by two sibling 1 1 convolutional layers (for reg
and cls, respectively).
3.1.1 Anchors
At each sliding-window location, we simultaneously pre-
dict multiple region proposals, where the number of maxi-
mum possible proposals for each location is denoted as k.
So the reg layer has 4 k outputs encoding the coordinates of
k boxes, and the cls layer outputs 2k scores that estimate
probability of object or not object for each proposal.
4
The k
proposals are parameterized relative to k reference boxes,
which we call anchors. An anchor is centered at the sliding
window in question, and is associated with a scale and
aspect ratio (Fig. 3, left). By default we use three scales and
three aspect ratios, yielding k ¼ 9 anchors at each sliding
position. For a convolutional feature map of a size W H
(typically 2; 400), there are WHk anchors in total.
Translation-Invariant Anchors. An important property of
our approach is that it is translation invariant, both in terms
of the anchors and the functions that compute proposals rel-
ative to the anchors. If one translates an object in an image,
the proposal should translate and the same function should
be able to predict the proposal in either location. This trans-
lation-invariant property is guaranteed by our method.
5
As
a comparison, the MultiBox method [27] uses k-means to
generate 800 anchors, which are not translation invariant. So
MultiBox does not guarantee that the same proposal is gen-
erated if an object is translated.
The translation-invariant property also reduces the
model size. MultiBox has a ð4 þ 1Þ800-dimensional fully-
connected output layer, whereas our method has a
ð4 þ 2Þ9-dimensional convolutional output layer in the
case of k ¼ 9 anchors.
6
As a result, our output layer has
2:8 10
4
parameters (512 ð4 þ 2Þ9 for VGG-16), two
orders of magnitude fewer than MultiBox’s output layer
that has 6:1 10
6
parameters (1; 536 ð4 þ 1Þ800 for
GoogleNet [34] in MultiBox [27]). If considering the feature
projection layers, our proposal layers still have an order of
magnitude fewer parameters than MultiBox.
7
We expect
our method to have less risk of overfitting on small datasets,
like PASCAL VOC.
Multi-Scale Anchors as Regression References.Ourdesign
of anchors presents a novel scheme for addressing multi-
ple scales (and aspect ratios). As shown in Fig. 1, there
have been two popular ways for m ulti-scale predictions.
The first way is based on image/feature pyramids, e.g., in
Fig. 2. Faster R-CNN is a single, unified network for object detection.
The RPN module serves as the ‘attention’ of this unified network.
3. “Region” is a generic term and in this paper we only consider rect-
angular regions, as is common for many methods (e.g., [4], [6], [27]).
“Objectness” measures membership to a set of object classes
versus background.
4. For simplicity we implement the cls layer as a two-class softmax
layer. Alternatively, one may use logistic regression to produce k
scores.
5. As is the case of FCNs [7], our network is translation invariant up
to the network’s total stride.
6. 4 is the dimension of reg term for each category, and 1 or 2 is the
dimension of cls term of sigmoid or softmax for each category.
7. Considering the feature projection layers, our proposal layers’
parameter count is 3 3 512 512 þ 512 6 9 ¼ 2:4 10
6
; Multi-
Box’s proposal layers’ parameter count is
7 7 ð64 þ 96 þ 64 þ 64Þ1; 536 þ 1; 536 5 800 ¼ 27 10
6
.
REN ET AL.: FASTER R-CNN: TOWARDS REAL-TIME OBJECT DETECTION WITH REGION PROPOSAL NETWORKS 1139
剩余12页未读,继续阅读
443 浏览量
121 浏览量
226 浏览量
191 浏览量
143 浏览量
628 浏览量
335 浏览量
142 浏览量
点击了解资源详情

小新GSUNG0222
- 粉丝: 13
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







