数据预处理通用方法:Binarizer与OneHotEncoder详解
需积分: 31 116 浏览量
更新于2024-09-01
收藏 283KB PDF 举报
数据预处理是数据分析和机器学习项目中的关键步骤,它涉及清洗、转换和规范化原始数据,以便让算法能够有效地理解和利用。在给出的PDF文档《数据预处理的一些通用办法》中,主要讨论了两种常见的数据预处理方法:Binarizer 和 OneHotEncoder。
1. **Binarizer** 是一个简单但实用的工具,用于将连续数值型数据转换为二进制表示。它的`threshold`参数决定了一个阈值,当输入数值超过这个阈值时,结果被设置为1,否则为0。Binarizer的`copy`参数控制是否创建数据的副本,以防原始数据被修改。`fit()`、`transform()`和`fit_transform()`方法分别用于模型训练、单独转换数据和同时训练并转换数据。
2. **OneHotEncoder** 用于将分类变量编码成一组虚拟变量(one-hot encoding),每一种类别对应一个特征。该类有以下几个关键参数:
- `n_values` 可以设置为 'auto',表示自动检测可能的类别数量,或者指定特定的数量。
- 当`n_values`为 'auto' 时,编码器会计算输入数据中的唯一类别数目。如果选择特定值,必须确保这个值涵盖了所有可能的类别。
- `'auto'` 或者用户自定义的`n_values`会影响编码后的特征矩阵结构。
- `categorical`属性可能指的是处理类别数据的方式,这在实际应用中非常重要,因为它决定了如何对非数值型数据进行编码。
这些预处理方法都是为了标准化数据,减少噪声,以及准备数据以适应机器学习算法的需求。在实际操作中,根据数据特性和任务需求,可能还需要组合使用其他预处理技术,如缺失值处理、异常值检测、标准化或归一化等。通过理解并熟练运用这些通用的数据预处理方法,可以大大提高数据分析和模型构建的效率和效果。
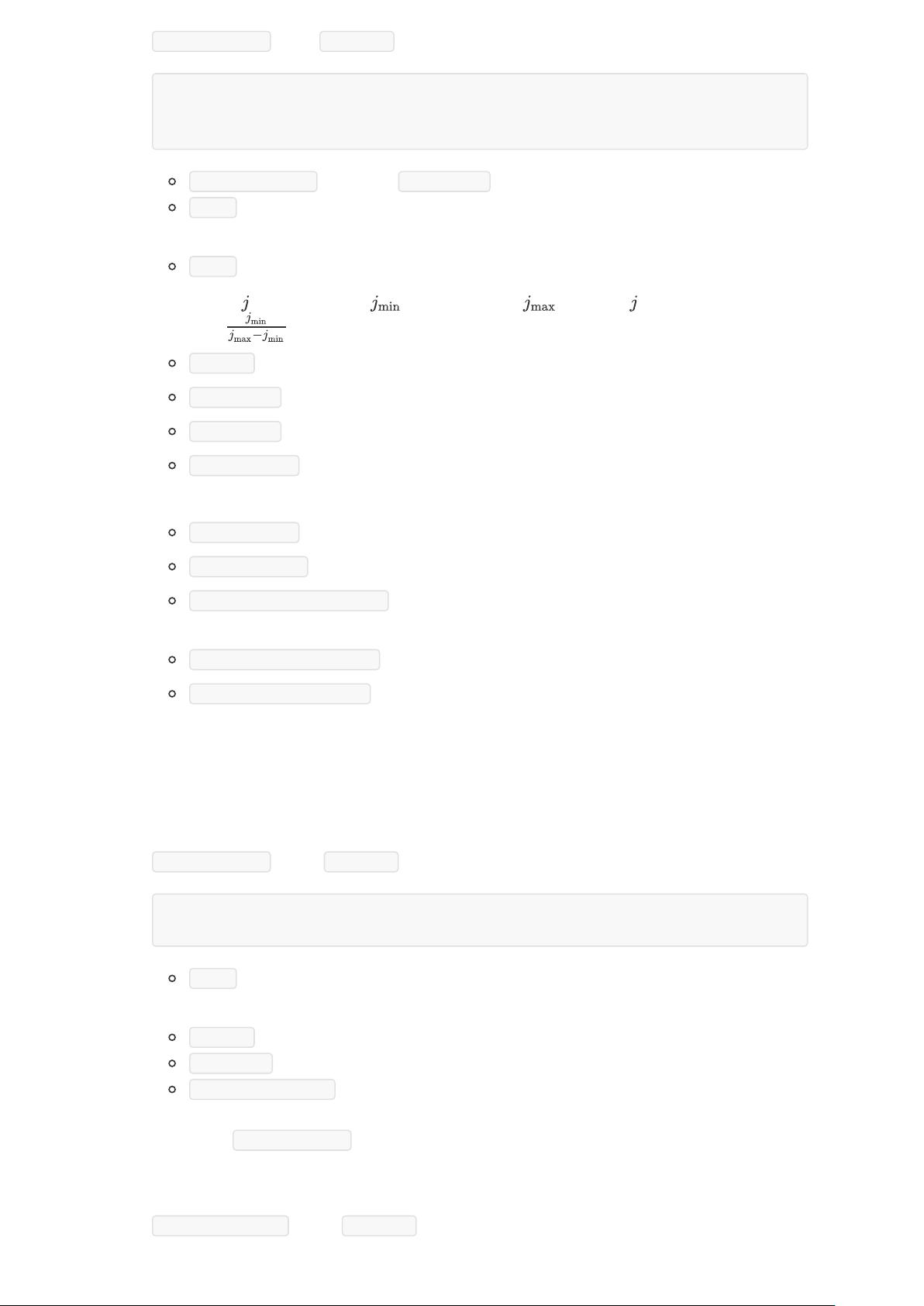
1. MinMaxScaler min-max
feature_range (min,max)
copy
2.
min_
scale_
data_min_
data_max_
data_range_
3.
fit(X[, y])
transform(X)
fit_transform(X[, y])
inverse_transform(X)
partial_fit(X[, y])
1.3.2 MaxAbsScaler
1. MaxAbsScaler max-abs
copy
2.
scale_
max_abs_
n_samples_seen_
3. MinMaxScaler
1.3.3 StandardScaler
1. StandardScaler z-score
class sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1),
copy=True)
class sklearn.preprocessing.MaxAbsScaler(copy=True)
剩余10页未读,继续阅读
209 浏览量
2021-09-08 上传
106 浏览量
2023-06-13 上传
172 浏览量
2023-08-29 上传
129 浏览量
2023-10-24 上传

hiHins
- 粉丝: 7
- 资源: 103
 我的内容管理
展开
我的内容管理
展开







最新资源
- 英语学习常用网站 附写作翻译之类的网站
- SQLServer的简介和使用
- linux入门笔记.pdf 初学者学习linux的最佳选择
- Image segmentation by histogram thresholding
- 恺撒(caesar)密码
- Bookends user guide
- struts in action中文版1.2
- ARM微处理器教程全集
- 用U盘安装系统.doc
- 华为编程规范--相当的严谨
- showModalDialog()、showModelessDialog()方法的使用.
- DOOM启示录(中文版)
- linux内核源码分析0.11.pdf
- DOS工具箱使用方法
- java深入浅出设计模式
- 经典的CCNA笔记 十分精简 短小精悍
