MongoDB聚合框架:管道操作与AggregationPipeline解析
17 浏览量
更新于2024-08-30
收藏 2.12MB PDF 举报
"MongoDB聚合管道(AggregationPipeline)"
MongoDB的聚合管道(Aggregation Pipeline)是一种强大的数据处理工具,它允许开发者对数据库中的数据进行一系列的处理步骤,类似于数据流处理中的管道概念。这个概念借鉴了操作系统中多线程的流水线方式,数据文档按照预设的顺序通过一系列处理阶段(stages),每个阶段执行特定的操作,如过滤、转换、分组等,最终生成所需的输出结果。
聚合管道的核心在于其串联的处理阶段,每个阶段都接收前一阶段的输出作为输入,并产生新的输出供下一阶段使用。这种设计使得数据处理具有高度的灵活性和效率,因为每个阶段可以独立优化,且无需在内存中一次性加载所有数据。
MongoDB在2.2版本中引入聚合框架,以满足用户对复杂数据查询和分析的需求。这个框架提供了多种操作符,包括但不限于:
1. `$match`:用于过滤文档,类似于SQL的WHERE子句,只保留满足条件的文档进入后续阶段。
2. `$project`:改变文档的结构,可以选择性地显示或隐藏字段,或者进行简单的计算和转换。
3. `$group`:根据指定的字段对文档进行分组,可以计算分组内的聚合值,如求和、平均值等。
4. `$sort`:对结果进行排序,可以根据一个或多个字段的值进行升序或降序排列。
5. `$lookup`:执行数据库间的关联操作,类似于SQL的JOIN。
6. `$unwind`:用于展开文档中的数组字段,将每个数组元素转化为单独的文档。
7. `$bucket`:对数据进行桶式分组,常用于统计分析。
聚合管道的一个显著优点是它提供了相对MapReduce更简洁的接口,避免了编写复杂的JavaScript代码。虽然MapReduce也能实现类似功能,但聚合管道的固定操作符和声明式语法使得开发和维护更为简便。
此外,由于MongoDB支持在文档内存储数组,聚合框架特别适合处理包含数组的数据。例如,可以使用`$unwind`操作符来处理数组字段,然后使用`$group`进行分组计算,这在关系型数据库中可能需要更复杂的子查询或自连接操作。
MongoDB聚合管道是处理和分析数据的强大工具,它结合了灵活性、效率和易用性,能够应对各种数据处理挑战,尤其在需要对文档内的数组进行操作时,其优势更加明显。通过熟练掌握聚合管道,开发者可以更高效地从MongoDB数据库中提取和分析信息,满足复杂的数据需求。
MongoDB聚合管道(聚合管道(AggregationPipeline))
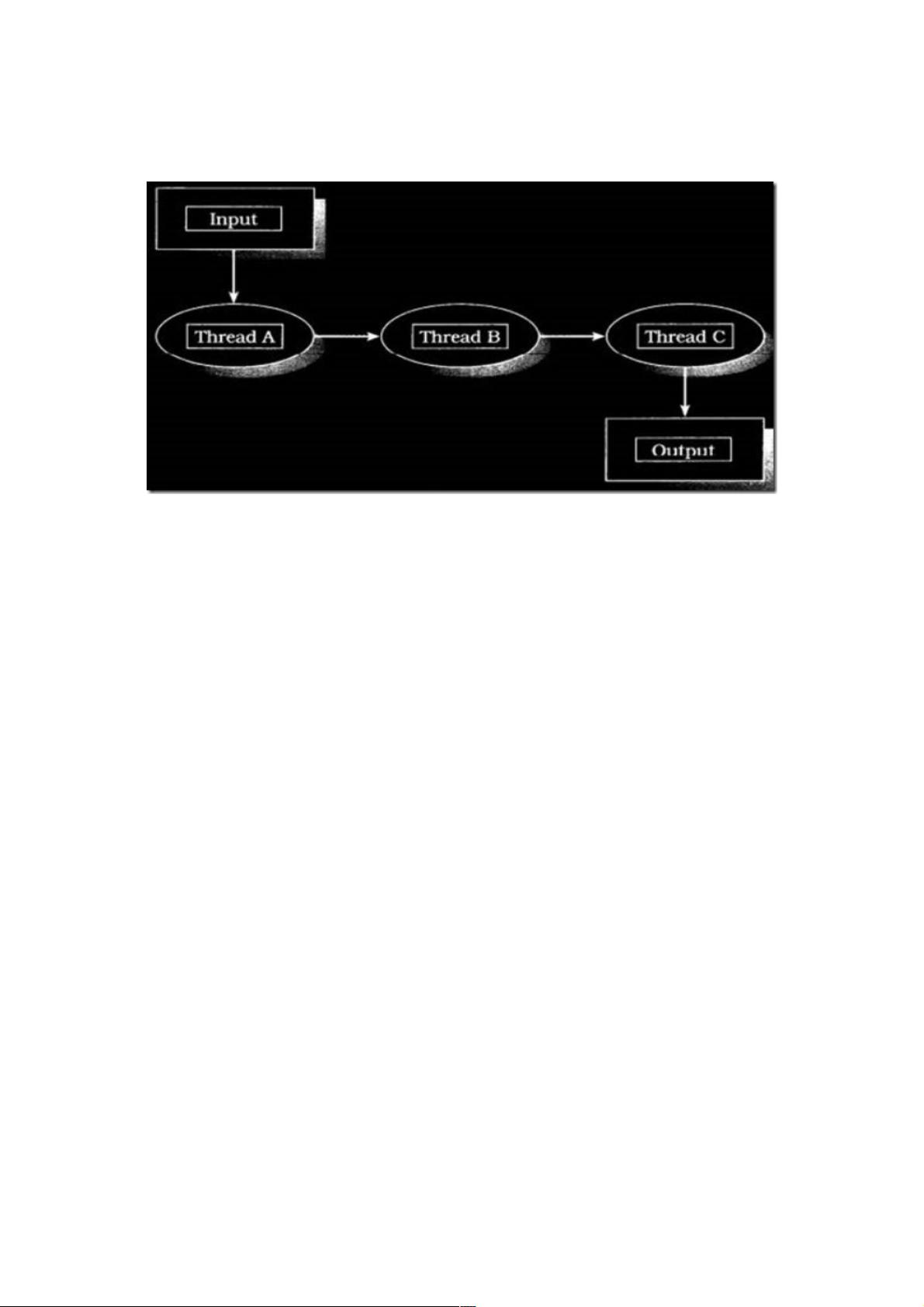
管道概念
POSIX多线程的使用方式中, 有一种很重要的方式-----流水线(亦称为“管道”)方式,“数据元素”流串行地被一组线程按顺序
执行。它的使用架构可参考下图:
以面向对象的思想去理解,整个流水线,可以理解为一个数据传输的管道;该管道中的每一个工作线程,可以理解为一个整个
流水线的一个工作阶段stage,这些工作线程之间的合作是一环扣一环的。靠输入口越近的工作线程,是时序较早的工作阶段
stage,它的工作成果会影响下一个工作线程阶段(stage)的工作结果,即下个阶段依赖于上一个阶段的输出,上一个阶段的输
出成为本阶段的输入。这也是pipeline的一个共有特点!
为了回应用户对简单数据访问的需求,MongoDB2.2版本引入新的功能聚合框架(Aggregation Framework) ,它是数据聚合的
一个新框架,其概念类似于数据处理的管道。 每个文档通过一个由多个节点组成的管道,每个节点有自己特殊的功能(分
组、过滤等),文档经过管道处理后,最后输出相应的结果。管道基本的功能有两个:
一是对文档进行“过滤”,也就是筛选出符合条件的文档;
二是对文档进行“变换”,也就是改变文档的输出形式。
其他的一些功能还包括按照某个指定的字段分组和排序等。而且在每个阶段还可以使用表达式操作符计算平均值和拼接字符串
等相关操作。管道提供了一个MapReduce 的替代方案,MapReduce使用相对来说比较复杂,而管道的拥有固定的接口(操作
符表达),使用比较简单,对于大多数的聚合任务管道一般来说是首选方法。
该框架使用声明性管道符号来支持类似于SQL Group By操作的功能,而不再需要用户编写自定义的JavaScript例程。
大部分管道操作会在“aggregate”子句后会跟上“$match”打头。它们用在一起,就类似于SQL的from和where子句,或是
MongoDB的find函数。“$project”子句看起来也非常类似SQL或MongoDB中的某个概念(和SQL不同的是,它位于表达式尾
端)。
接下来介绍的操作在MongoDB聚合框架中是独一无二的。与大多数关系数据库不同,MongoDB天生就可以在行/文档内存储
数组。尽管该特性对于全有全无的数据访问十分便利,但是它对于需要组合投影、分组和过滤操作来编写报告的工作,却显得
相当复杂。“$unwind”子句将数组分解为单个的元素,并与文档的其余部分一同返回。
“$group”操作与SQL的Group By子句用途相同,但是使用起来却更像是LINQ中的分组运算符。与取回一行平面数据不
同,“$group”操作的结果集会呈现为一个持续的嵌套结构。正因如此,使用“$group”可以返回聚合信息,例如对于每个分组中
的实际文档,计算文档整体或部分的数目和平均值。
管道操作符
管道是由一个个功能节点组成的,这些节点用管道操作符来进行表示。聚合管道以一个集合中的所有文档作为开始,然后这些
文档从一个操作节点 流向下一个节点 ,每个操作节点对文档做相应的操作。这些操作可能会创建新的文档或者过滤掉一些不
符合条件的文档,在管道中可以对文档进行重复操作。
先看一个管道聚合的例子:
下载后可阅读完整内容,剩余9页未读,立即下载
2015-08-11 上传
2015-08-07 上传
2021-06-21 上传
2021-07-02 上传
2021-06-25 上传
2021-06-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38704011
- 粉丝: 3
- 资源: 947
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
