堆排序与快速排序:为何快速排序实战表现更优?
需积分: 0 196 浏览量
更新于2024-07-01
收藏 3.36MB PDF 举报
"28|堆和堆排序:为什么说堆排序没有快速排序快?\n数据结构与算法之美\n进入课程\n讲述:修阳\n时长15:34\n大小7.14M"
本文主要探讨了堆和堆排序的概念,以及它们与快速排序之间的性能差异。堆是一种特殊的数据结构,常用于实现堆排序算法,其时间复杂度为O(nlogn)。堆排序虽然在理论时间复杂度上与快速排序相当,但在实际应用中,快速排序通常表现出更好的性能。
首先,堆是一种完全二叉树,即除了最后一层外,所有层的节点都充满,最后一层的节点都靠左排列。堆分为大顶堆和小顶堆,大顶堆中每个节点的值大于等于其子节点的值,反之在小顶堆中则是小于等于。这些性质使得堆在查找最大或最小元素时非常高效。
堆排序的实现过程包括两个主要步骤:建堆和调整堆。建堆是将无序序列构造成一个合法的堆,然后通过交换堆顶元素(最大或最小元素)与末尾元素并缩小堆范围,重复此过程,最终达到排序目的。这个过程是原地的,即不需要额外的存储空间。
然而,相比于快速排序,堆排序在实际应用中的效率较低。快速排序采用分治策略,通过选取一个基准元素,将数组分为两部分,使得一部分元素小于基准,另一部分大于基准,然后递归地对这两部分进行排序。快速排序的平均时间复杂度也是O(nlogn),但其常数因子较小,且在最坏情况下也能保持O(n^2)的时间复杂度,这在实际数据分布均匀时表现得尤为突出。
堆排序的性能劣势主要体现在以下几个方面:
1. 堆排序在调整堆的过程中,频繁地交换元素,而快速排序的交换次数相对较少。
2. 快速排序在处理大规模数据时,由于其内部循环可以在多核处理器上并行化,因此速度更快。
3. 快速排序的局部性较好,利于缓存优化,而堆排序的随机访问性较差。
总结来说,虽然堆排序在理论上有良好的时间复杂度,但由于其内在的效率问题,如更多的元素交换和较差的缓存行为,在实际应用中往往不如快速排序。了解这些差异有助于我们在设计和选择排序算法时做出更合适的选择。
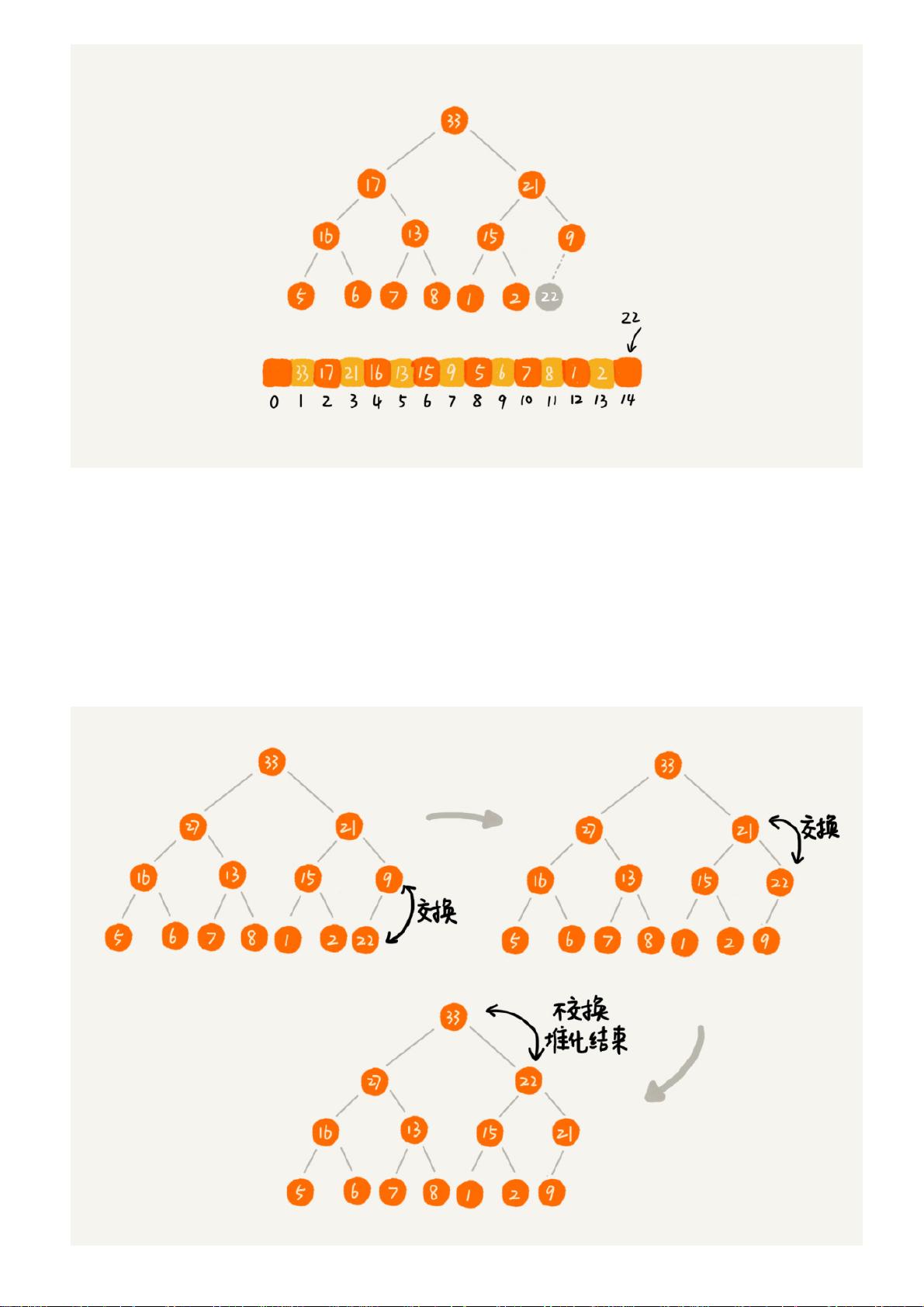
堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比,然后交换。
我这里画了一张堆化的过程分解图。我们可以让新插入的节点与父节点对比大小。如果不满
足子节点小于等于父节点的大小关系,我们就互换两个节点。一直重复这个过程,直到父子
节点之间满足刚说的那种大小关系。
剩余21页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2017-10-13 上传

小米智能生活
- 粉丝: 46
- 资源: 300
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
