"Hadoop可靠性概述:HDFS操作流程、副本策略与常见故障处理"
需积分: 5 62 浏览量
更新于2024-04-12
收藏 353KB PPT 举报
Hadoop是一个可靠性很高的分布式系统,其核心组件之一是HDFS(Hadoop分布式文件系统)。HDFS的可靠性保证主要依赖于其系统架构和副本放置策略。
首先,让我们来看一下HDFS的系统架构。HDFS由两部分组成:NameNode和DataNode。NameNode负责存储文件系统的元数据,包括文件路径、块键信息等;而DataNode负责存储实际的数据块。这种分离的设计使得HDFS能够有效地管理PB级数据,并且具有较高的扩展性和可靠性。
在HDFS中,文件被分成大小固定的数据块,并通过副本放置策略来保证数据的可靠性。HDFS会将每个数据块复制多份,并将这些副本分布在不同的DataNode上,从而防止单点故障导致数据丢失。当某个DataNode失效时,HDFS会自动将该DataNode上的数据块复制到其他正常的DataNode上,保证数据的可靠性和可用性。
除了系统架构和副本放置策略外,HDFS还具有一些特性和应用场景。HDFS适合存储和管理PB级数据,处理非结构化数据,并注重数据处理的吞吐量,适合应用模式为write-once-read-many的存取模式。然而,HDFS并不适合存储大量小文件、进行大量的随机读操作或需要频繁修改文件的场景。
在实际的应用中,许多公司和组织都选择使用Hadoop来处理海量数据。比如百度等互联网公司就是Hadoop的重要用户之一,通过HDFS来存储和处理海量数据,实现各种数据分析和挖掘的应用。
总的来说,Hadoop的可靠性主要体现在其系统架构、副本放置策略以及一系列特性和应用场景上。通过合理的设计和部署,HDFS能够保证数据的可靠性和可用性,为用户提供高效稳定的数据存储和处理服务。在面对节点失效等常态情况时,HDFS能够自动处理并恢复数据,确保数据的完整性和可靠性。因此,Hadoop作为一个成熟和可靠的分布式系统,被广泛应用于各种大数据场景中,为用户带来了便利和价值。
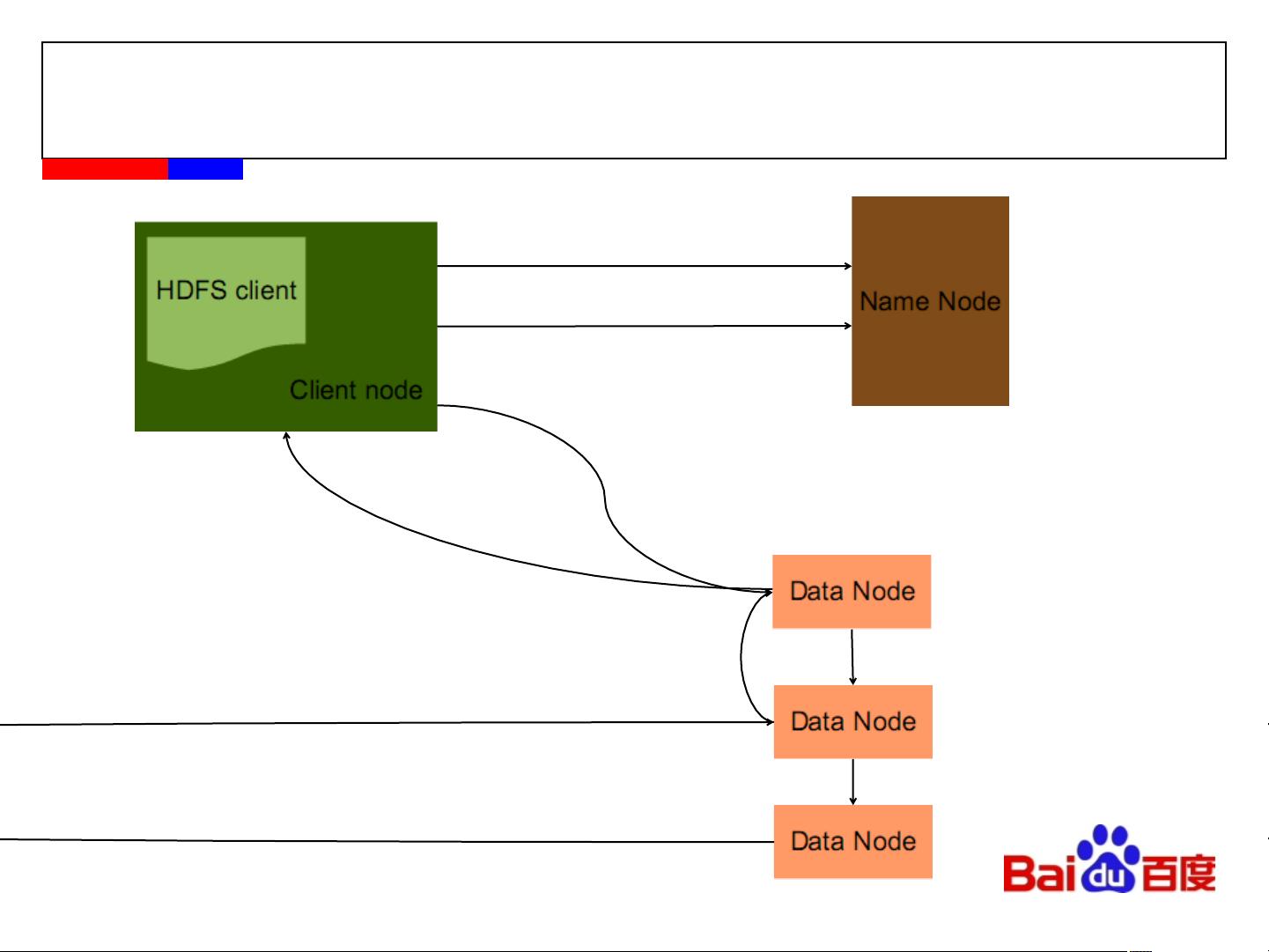
Example:HDFS如何写文件?
Writepacket
Createfile
Write packet
Write packet
Send ack
Send ack
Send ack
Closefile

剩余41页未读,继续阅读
2013-07-23 上传
2022-01-04 上传
2024-03-13 上传
2018-11-12 上传
2018-04-03 上传
2021-09-14 上传
2011-05-19 上传

myshare2022
- 粉丝: 81
- 资源: 149
 我的内容管理
展开
我的内容管理
展开







最新资源
- Postman安装与功能详解:适用于API测试与HTTP请求
- Dart打造简易Web服务器教程:simple-server-dart
- FFmpeg 4.4 快速搭建与环境变量配置教程
- 牛顿井在围棋中的应用:利用牛顿多项式求根技术
- SpringBoot结合MySQL实现MQTT消息持久化教程
- C语言实现水仙花数输出方法详解
- Avatar_Utils库1.0.10版本发布,Python开发者必备工具
- Python爬虫实现漫画榜单数据处理与可视化分析
- 解压缩教材程序文件的正确方法
- 快速搭建Spring Boot Web项目实战指南
- Avatar Utils 1.8.1 工具包的安装与使用指南
- GatewayWorker扩展包压缩文件的下载与使用指南
- 实现饮食目标的开源Visual Basic编码程序
- 打造个性化O'RLY动物封面生成器
- Avatar_Utils库打包文件安装与使用指南
- Python端口扫描工具的设计与实现要点解析
