Oracle数据库快速入门与安装指南
需积分: 41 42 浏览量
更新于2024-07-19
收藏 4.5MB DOCX 举报
"Oracle快速入门文档,包括Oracle数据库系统介绍、Oracle 10g安装步骤、PLSQL Developer安装指南以及PowerDesigner的简述"
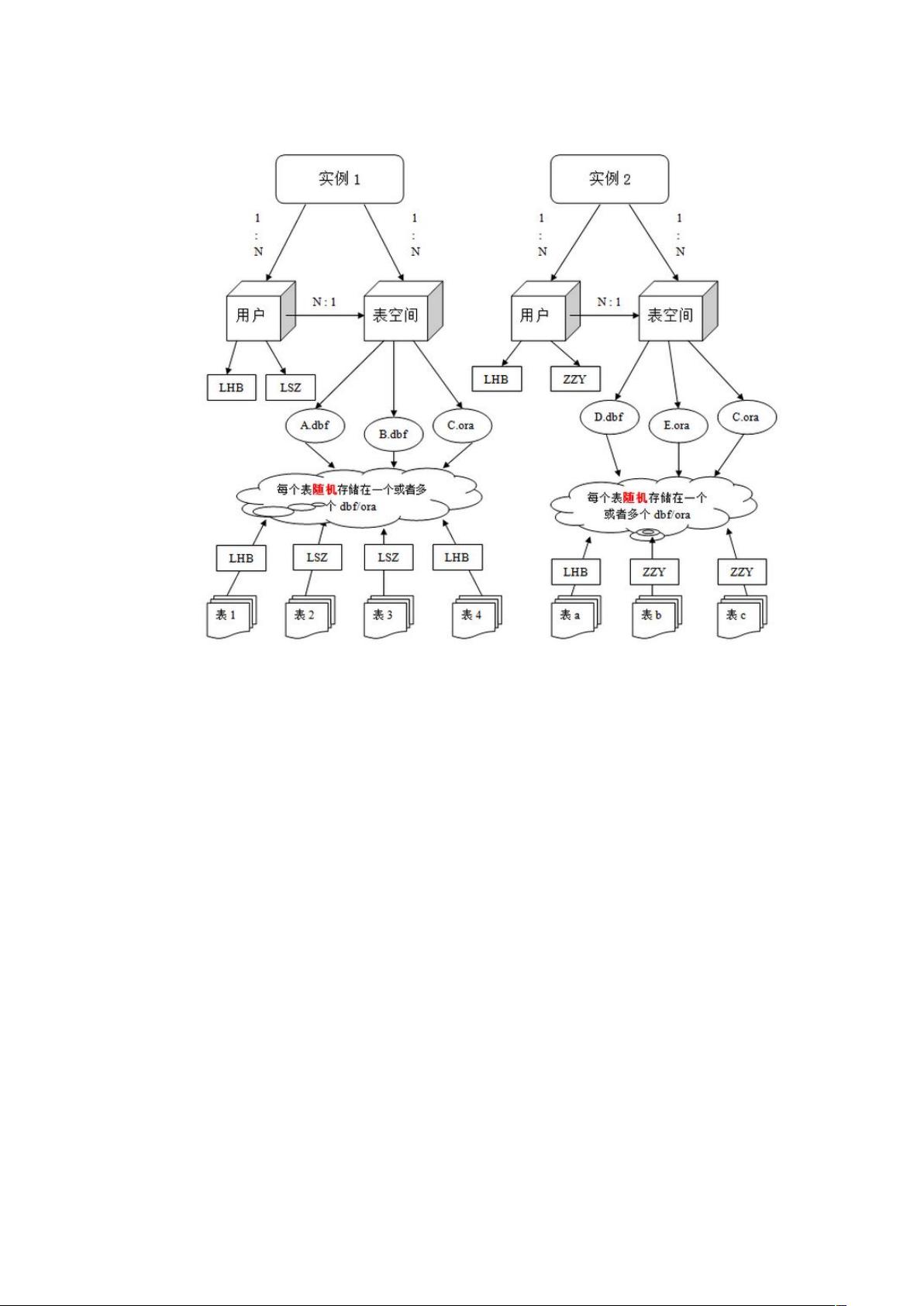
在IT领域,Oracle数据库系统是不可或缺的一部分,尤其对于大型企业和组织,它是管理和存储数据的核心工具。Oracle数据库系统由美国Oracle公司开发,以其分布式数据库功能和强大的客户/服务器或B/S架构闻名。Oracle数据库不仅提供全面的数据管理功能,还实现了关系数据库的完整特性,并具备分布式处理能力。因此,学习Oracle知识意味着可以在各种硬件平台上进行操作。
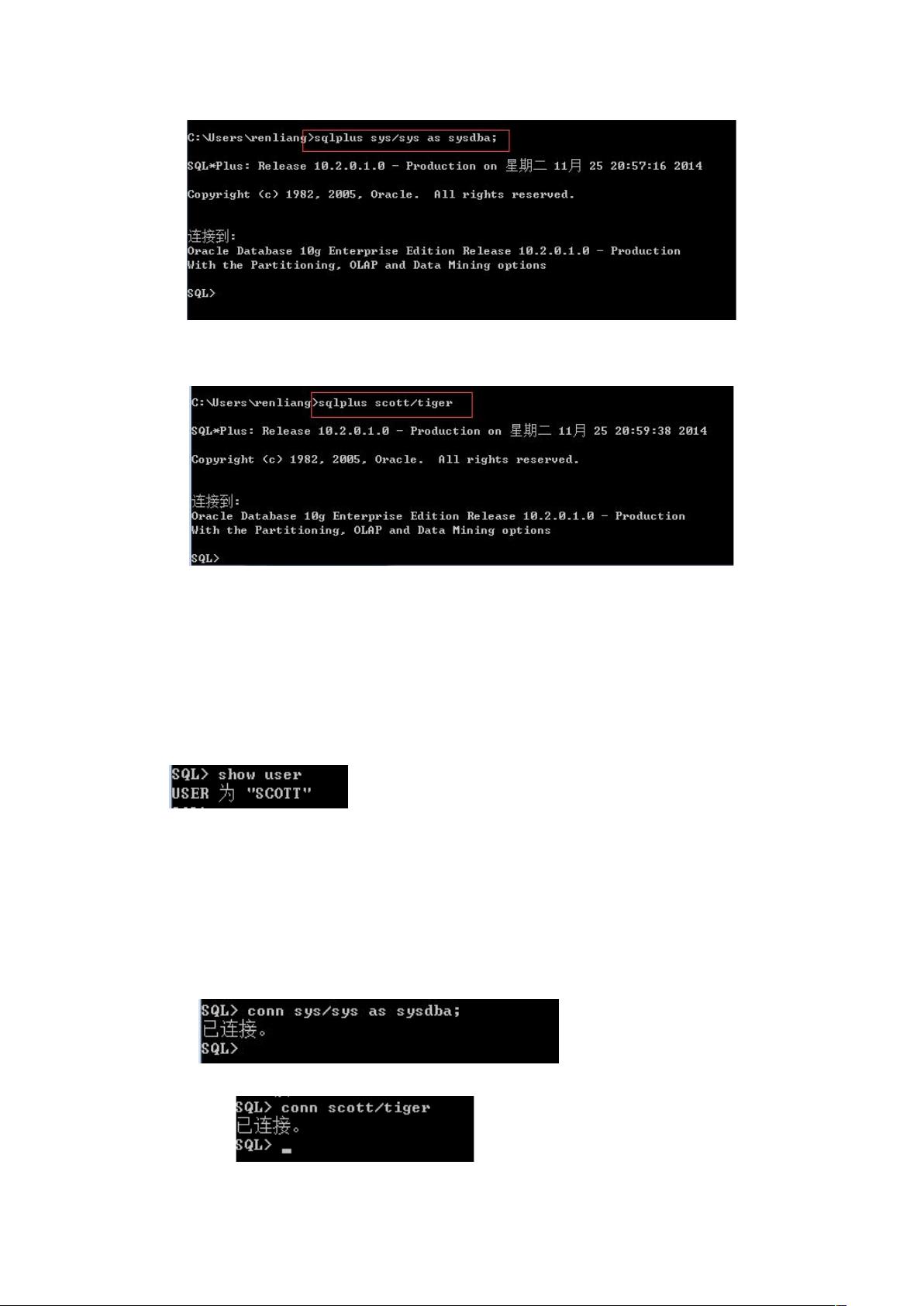
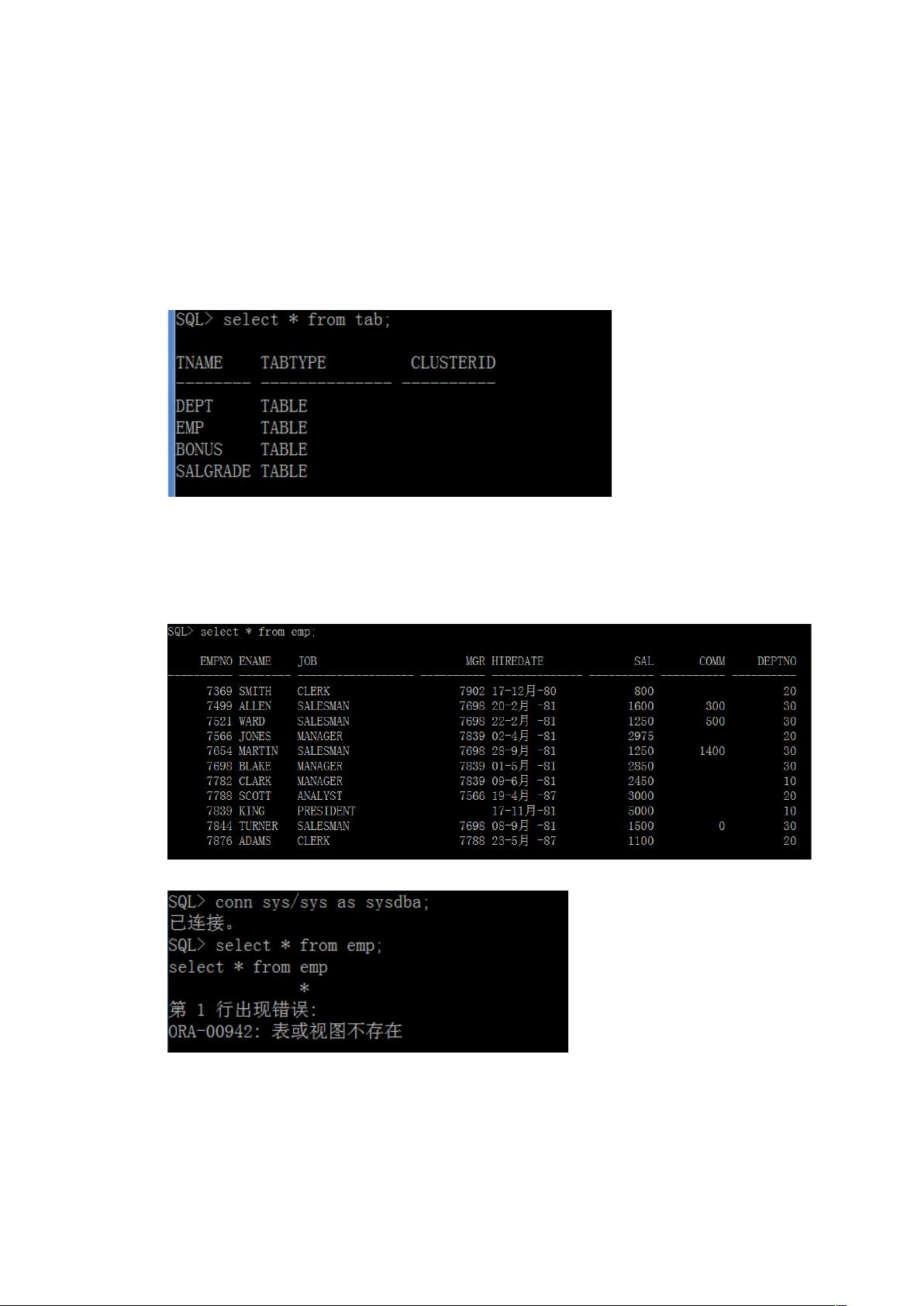
Oracle 10g的安装过程相对简单,但对于Windows 7或8系统,需要确保以管理员权限并兼容XP模式运行安装程序。启动setup.exe后,设置管理员口令,然后按照向导进行安装,包括检查先决条件、选择安装类型、配置网络组件等步骤。安装完成后,别忘了通过配置向导解锁默认的SCOTT和HR用户,以便后续使用。
PLSQL Developer是Oracle数据库开发者常用的一款图形化工具,它简化了与数据库的交互,提供了丰富的功能,如查询、调试、数据管理等。安装时需要注意避免在包含特殊字符或中文的路径下安装,以防止连接问题。在安装过程中输入序列号激活软件。
PowerDesigner则是一款强大的数据库建模工具,支持创建和设计数据模型,包括概念数据模型、逻辑数据模型和物理数据模型。这对于数据库的设计和规划非常有帮助,能够提高数据库的规范化程度和性能。尽管PowerDesigner的安装相对直观,但其功能的深入使用需要一定的学习和实践。
这些工具的掌握是成为Oracle数据库专家的基础。通过Oracle 10g的安装,可以理解数据库系统的运行环境;使用PLSQL Developer能提升开发效率;而PowerDesigner则有助于在项目早期阶段就建立清晰的数据库结构。这三者结合,构成了Oracle数据库管理与开发的基本工具链。
2017-05-06 上传
2011-05-12 上传
2013-09-11 上传
2016-10-19 上传
2019-07-23 上传
2010-03-31 上传
2010-09-10 上传

祁连山的野孩子
- 粉丝: 3
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- react-transform-boilerplate:一种新的Webpack样板,具有热重载React组件,以及模块和组件级别的错误处理
- jsp+ssm+mysql实现图书馆预约占座管理系统
- kappa-architecture.com:围绕 Kappa 架构的信息、实现和示例存储库
- Saskatoon Public Library Search-crx插件
- 清新雅致绿色植物背景的工作计划PPT模板
- 小型项目:较小的项目
- Zenoss/MindTouch Mashup-开源
- geneticAlgoWords:我第一次尝试遗传算法-matlab开发
- 定时器quartz API文档
- Reading Helper-crx插件
- lab3-ansible-role2
- 网页设计
- Shared:ICPSR-共享软件存储库
- HC32460串口接收发送不定长数据
- Nanas0100
- Sahil190_C_Programs_Repository
