HBase:大数据的实时列式存储系统
需积分: 5 113 浏览量
更新于2024-07-06
收藏 488KB DOCX 举报
"Apache HBase 技术参考手册提供了关于这个基于Hadoop的分布式列式存储系统的详细信息。作为Google Bigtable的开源实现,HBase在处理大规模、随机读写的实时数据场景中表现出色,尤其适合大数据环境。它利用HDFS进行文件存储,依赖Hadoop MapReduce进行批量处理,并借助Zookeeper进行协同服务。然而,HBase并不适用于大规模数据分析,而是针对实时检索和快速写入。"
Apache HBase是Apache软件基金会开发的一个开源、非关系型数据库,设计用于处理和存储海量结构化数据。它是Hadoop生态系统的组成部分,建立在Hadoop文件系统(HDFS)之上,为用户提供对数据的随机实时读/写访问。HBase的设计灵感来源于Google的Bigtable,两者都有类似的架构:使用分布式文件系统存储数据,通过MapReduce处理大数据,并采用协同服务(Bigtable使用Chubby,HBase使用Zookeeper)来保证服务的高可用性。
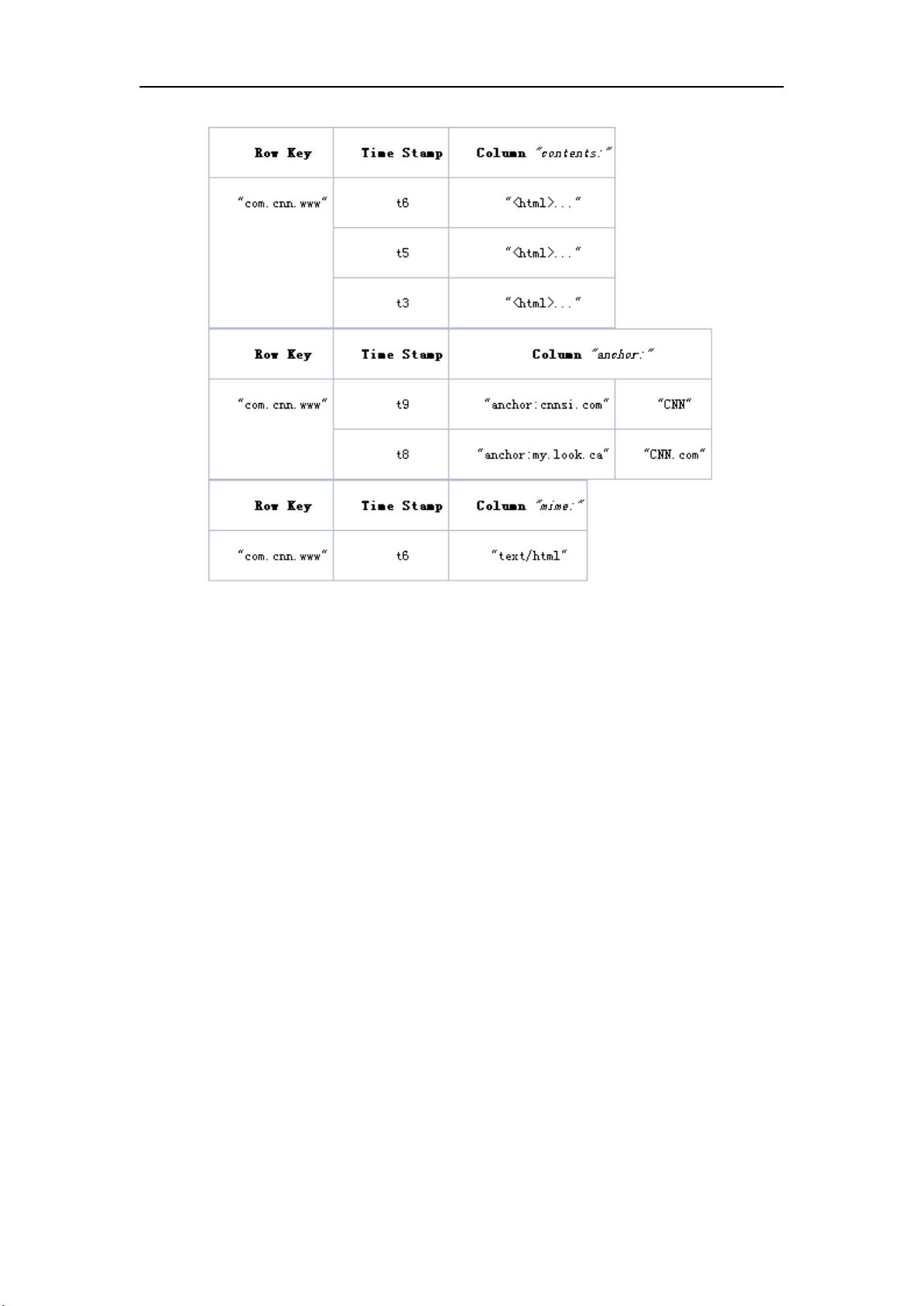
HBase的数据模型基于列族(Column Family),允许快速访问特定列的数据,而不是像传统关系型数据库那样按行存储所有数据。这种列式存储结构使得HBase在处理大规模数据时能进行高效的检索,特别适合于那些需要频繁查询特定列的情况。此外,HBase可以轻松地进行水平扩展,支持非常大的表规模,包括数十亿行和数百万列。
然而,HBase并非万能的解决方案。由于其列式存储特性,HBase在进行大范围的数据扫描和复杂的查询时效率较低,这使得它不适合于大规模的数据分析任务,这些任务通常由Hadoop的批处理能力来完成。相反,HBase更适合实时写入和实时检索场景,例如在线日志记录、实时监控或者需要快速响应的大型数据应用。
在处理数据时,Hadoop和HBase的角色有所不同。Hadoop通过HDFS提供高容错的数据存储,并通过MapReduce执行大规模的离线分析。而HBase则填补了Hadoop的空白,提供了低延迟的随机访问,满足了实时应用的需求。Hadoop与HBase结合使用,可以构建出既能够进行大规模批处理又能支持实时查询的综合数据处理平台。
Apache HBase是应对大数据实时处理需求的关键工具,尤其适用于需要快速随机访问和更新数据的应用场景。但同时,理解它的适用范围和局限性——例如不适用于复杂查询和大数据分析——至关重要,这样才能合理地将其融入到整体的数据处理架构中。
技术参考手册
应用
HBase 是用来当有需要写重的应用程序。
HBase 可以帮助快速随机访问数据。
HBase 被许多公司所采纳,例如,
Facebook、Twitter、Yahoo!、Adobe、OpenPlaces、WorldLingo 等等。
Apache HBase 曾经是随机,实时的读/写访问大数据。
它承载在集群普通硬件的顶端是非常大的表。
Apache HBase 是此前谷歌 Bigtable 模拟非关系型数据库。 Bigtable 对谷
歌文件系统操作,同样类似 Apache HBase 工作在 Hadoop HDFS 的顶部。


剩余63页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-06-22 上传
2019-04-10 上传
2019-11-02 上传
2018-12-29 上传
点击了解资源详情
点击了解资源详情

weixin_30777913
- 粉丝: 678
- 资源: 78
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
