Apache Kylin手动搭建与入门教程:配置与实践
需积分: 10 42 浏览量
更新于2024-07-15
收藏 7.3MB PDF 举报
Apache Kylin是一款开源的分布式数据仓库工具,它能够提供实时的数据分析和商业智能(BI)解决方案,尤其适用于大数据环境。本文档详细介绍了如何在Linux环境下手动安装和配置Apache Kylin,结合Hadoop进行操作。以下是关键步骤:
1. **手动搭建与下载**: 文档首先指导读者从Apache官方网站下载预编译的二进制包`apache-kylin-2.5.1-bin-hbase1x.tar.gz`,并将其解压到`opt/module`目录下。这一步涉及到对FTP或网络存储的使用。
2. **目录结构设置**: 安装完成后,文件被解压至`kylin-2.5.1`目录,并配置了环境变量,如`JAVA_HOME`、`HADOOP_HOME`、`SPARK_HOME`和`HIVE_HOME`,这些是Kylin运行所需的基础Java、Hadoop、Spark和Hive的安装路径。
3. **配置文件管理**: 提供了一个示例,说明如何备份默认配置文件`kylin.properties.template`并对其进行个性化定制,如设置`kylin.server.cluster-servers`和`kylin.server.mode`,这用于指定集群服务器和运行模式。
4. **集成Hive**: 文档还强调了如何将Kylin与Hive集成,这是构建数据立方体(Cube)的基础,立方体是Kylin中用来进行复杂分析的数据结构。通过Hive,用户可以编写SQL查询来处理和分析数据。
5. **系统环境配置**: 最后,文档提到修改系统环境变量`etc/profile`,确保Kylin的环境设置能在系统启动时自动加载,从而简化后续的使用过程。
6. **注意事项**: 对于遇到问题的用户,作者鼓励及时私信寻求帮助,表明了文档的互动性和支持性。
本文档是一份实用的Apache Kylin安装教程,适合初学者和有一定Linux基础的IT专业人士快速上手和理解Kylin的工作原理,特别是对于希望通过Hadoop生态进行大数据分析的用户来说,是一份宝贵的参考资源。
由于上⾯在 /etc/profile ⽂件中新增了内容,需要键⼊ source /etc/profile 让刚刚做的修
改⽴即⽣效
正式分发 /etc/profile ⽂件,键⼊命令 xsync /etc/profile
echo no args;
exit;
fi
#2 获取⽂件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级⽬录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前⽤户名称
user=`whoami`
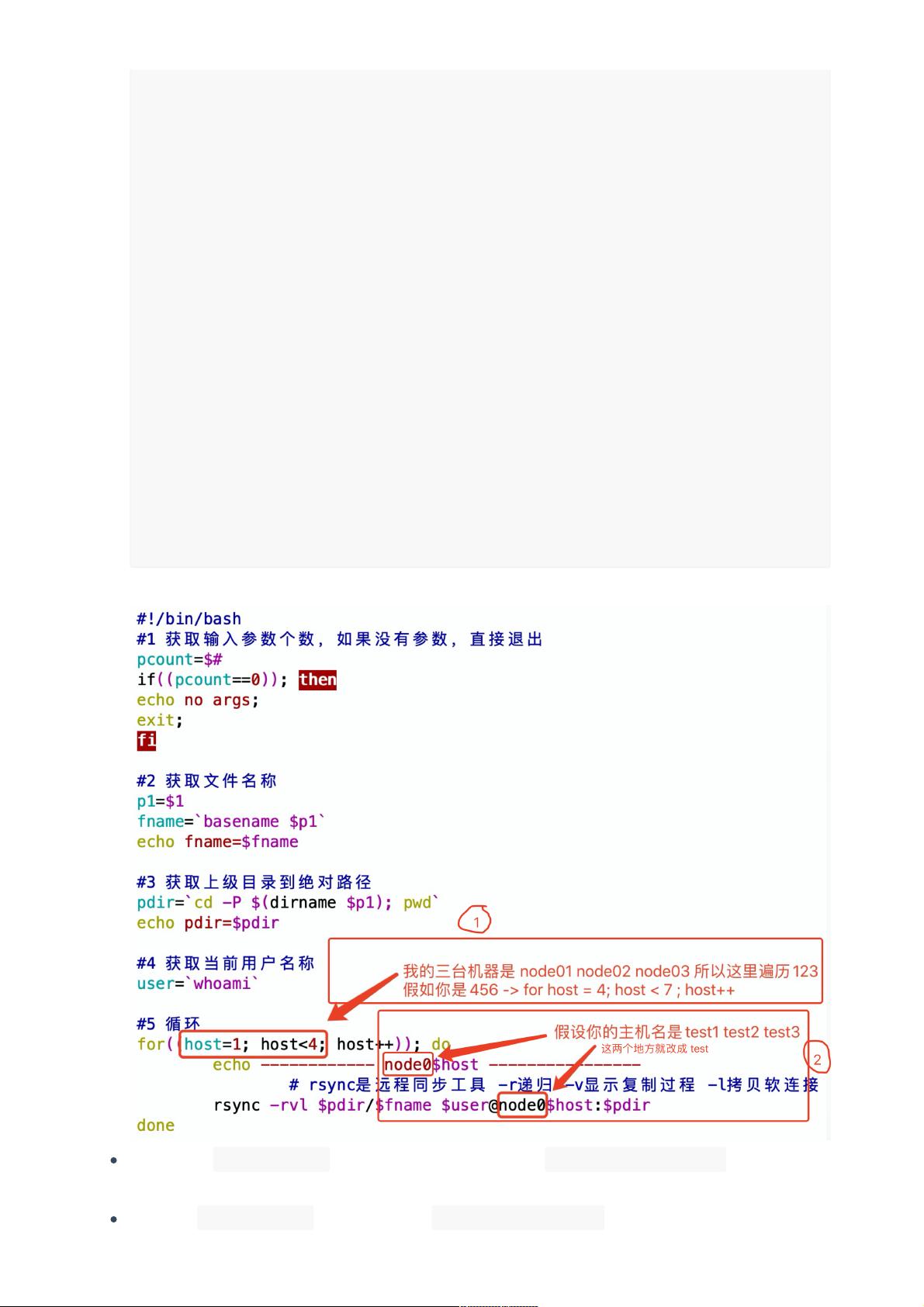
#5 循环
for((host=1; host<4; host++)); do
echo ------------ node0$host ----------------
# rsync是远程同步⼯具 -r递归 -v显示复制过程 -l拷⻉软连接
rsync -rvl $pdir/$fname $user@node0$host:$pdir
done
剩余14页未读,继续阅读
2018-03-23 上传
2017-04-19 上传
点击了解资源详情
2019-01-29 上传
2022-03-18 上传
2021-07-13 上传
2015-10-29 上传
点击了解资源详情

我与共饮长江水
- 粉丝: 4
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
