使用Go从零构建Lexer与Parser
需积分: 10 93 浏览量
更新于2024-07-09
收藏 4.72MB PDF 举报
"这篇内容是关于如何从零开始使用Go语言实现Lexer(词法分析器)和Parser(解析器)的教程,旨在为懂你英语的产品提供更稳定、高效的课程内容管理和开发流程。作者提到在产品 MVP 阶段面临快速变化、调试复杂、效率低下的问题,因此决定采用标记语言替代表单录入,并引入Git进行版本控制和自动化流程。教程分为三个主要步骤:编写Parser将课程文件转换为protobuf文件,实现Lexer,以及将两者整合。还涉及了EBNF(扩展巴科斯范式)来定义语法。"
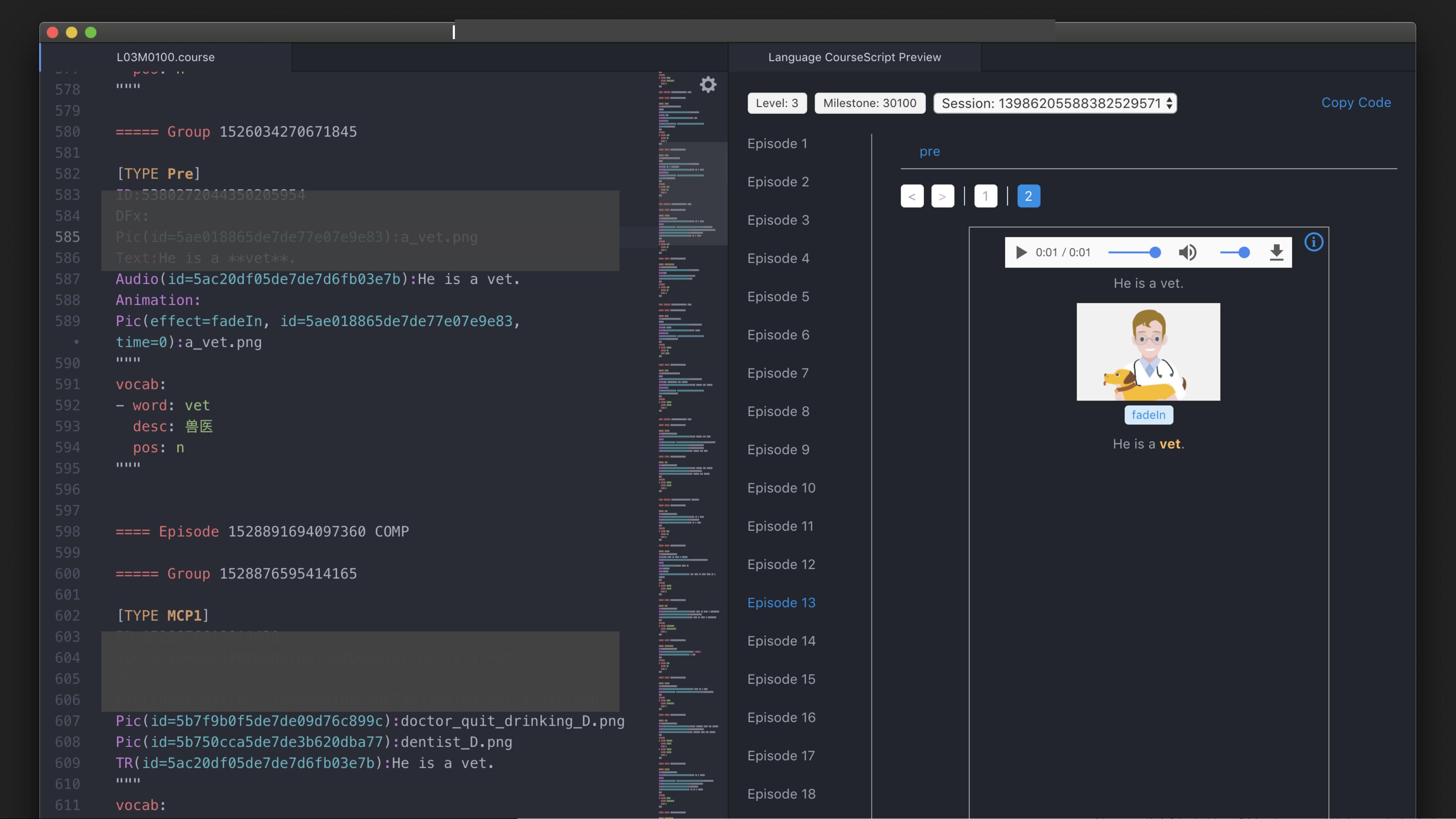
在IT领域,Lexer和Parser是编译器设计和解析技术中的核心组件。Lexer,也称为扫描器或词法分析器,负责将源代码分解成一系列有意义的符号或标记(tokens),这些标记是语言的最小单位,如关键字、标识符、数字等。Lexer通常基于正则表达式或规则集来识别这些符号。
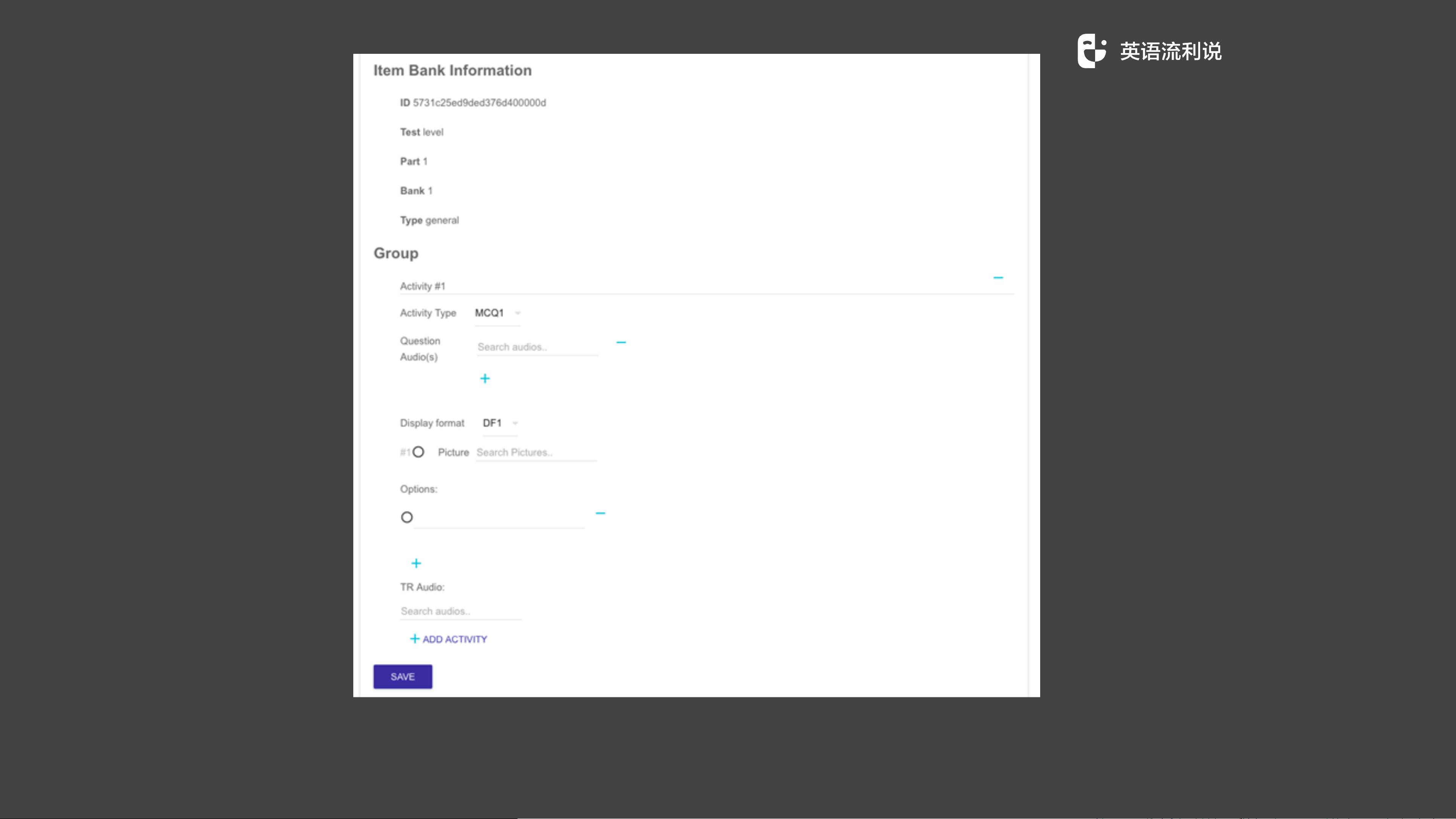
Parser,或解析器,接着词法分析器的工作,它将词法分析器产生的token流转换为抽象语法树(AST,Abstract Syntax Tree)。Parser可以分为不同的类型,如递归下降解析器、LL解析器、LR解析器等。在这个案例中,Parser的目标是将课程文件转换为protobuf文件,这是一种数据序列化格式,常用于跨语言通信和存储数据。
扩展巴科斯范式(EBNF)是一种形式化语言,用于描述编程语言或标记语言的语法结构。EBNF通过使用结构和重复符号来简化语法的表示,使得阅读和理解更加直观。在课程文件的解析过程中,EBNF用于定义课程文件的结构和各个部分的语法。
在实际应用中,使用Lexer和Parser的自动化流程能够极大地提高内容开发的效率和质量。例如,通过教研发团队使用Git管理课程内容,可以方便地追踪版本,实现版本控制和回滚。同时,结合CI(持续集成)系统,每次内容改动都会触发自动化测试和构建,确保内容符合预期,并在验证无误后自动部署。
此外,用标记语言替代表单录入可以降低前端开发的复杂性,因为前端开发者不再需要处理复杂的用户输入验证,而是专注于呈现和交互。自动化录入流程通过git push触发,减少了手动操作,提升了工作效率。
本教程通过实例展示了如何使用Go语言构建Lexer和Parser来改进教育产品的内容管理流程,以及如何利用现代软件工程实践(如Git和CI/CD)提升研发效率。这对于任何需要处理结构化内容或语言解析的项目都有很高的参考价值。

•
结构需要灵活,但也要有定的约束
•
内容发布之前 CI 检查, 每次改动都 CI
•
使标记语代替表单录,保住前端发际线!
•
教教研 git 管内容
•
动化录流程,git push -> CI -(tag) -> deploy

剩余80页未读,继续阅读
2021-01-26 上传
2024-05-30 上传
2023-03-27 上传
2023-05-26 上传
2023-03-27 上传
2023-06-09 上传
2023-05-25 上传
2023-06-02 上传
2023-06-09 上传

Saar
- 粉丝: 4
- 资源: 37
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
