LinDB时序数据库架构从1.0到3.0的演进
版权申诉
114 浏览量
更新于2024-07-05
收藏 14.81MB PDF 举报
"时序数据库LinDB架构演进(22页).pdf"
这篇文档讲述了时序数据库LinDB从早期版本到LinDB3.0的架构演进过程,重点介绍了其在解决数据存储、处理效率、扩展性以及功能增强等方面的关键技术变革。以下是主要的知识点:
1. **Zookeeper集成**:
在早期版本中,LinDB开始采用Zookeeper作为集群管理工具,用于协调分布式系统中的节点状态和数据一致性,确保服务的高可用性和稳定性。
2. **Measurement+Tags+Fields设计**:
LinDB引入了时间序列数据模型,包括Measurement(度量)、Tags(标签)和Fields(字段),这种设计使得数据组织更加灵活且易于查询,便于对大规模时序数据进行高效管理和分析。
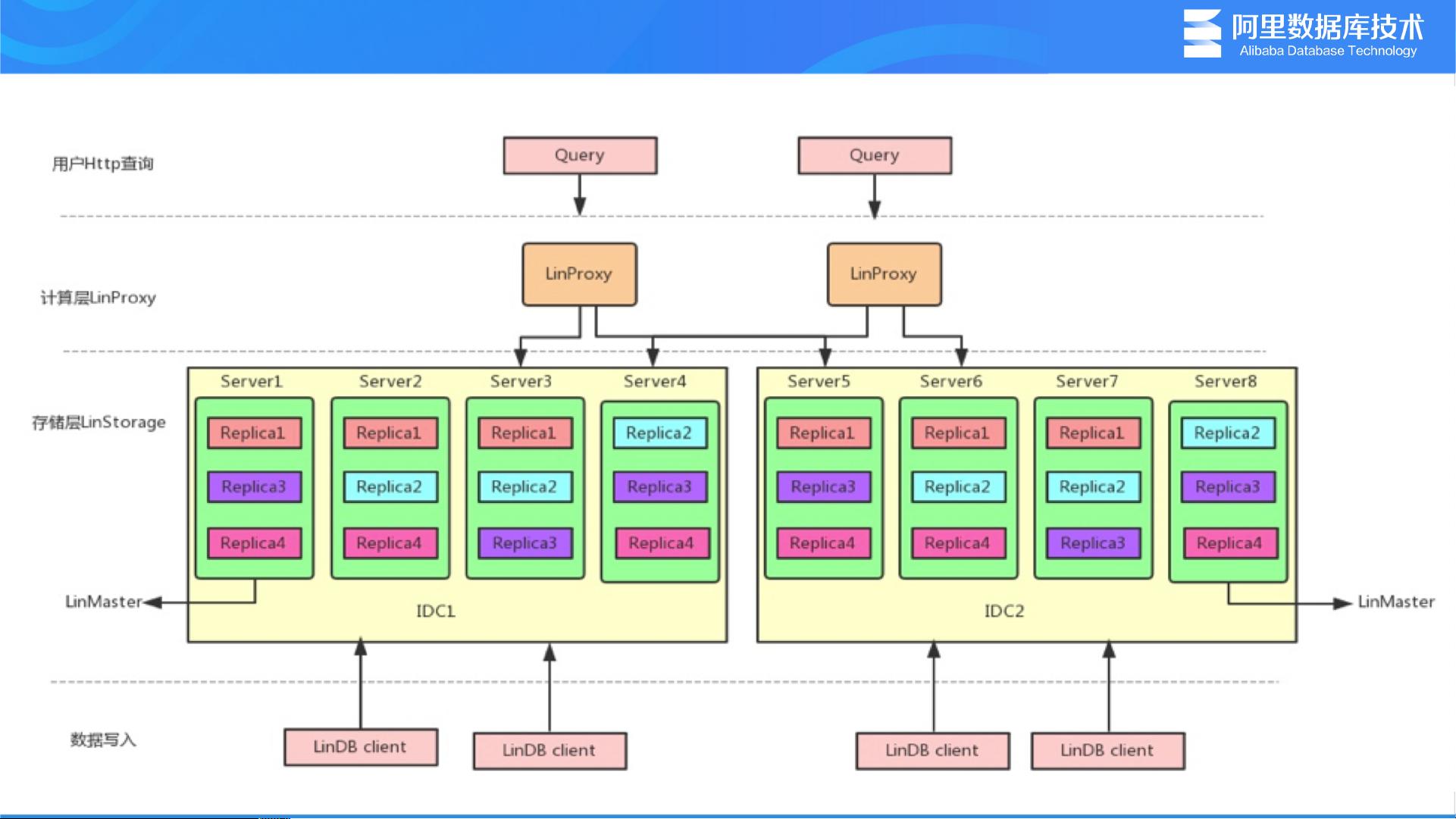
3. **Series Sharding策略**:
随着版本升级,LinDB采用了Series Sharding策略来提高数据存储的并行性和可扩展性,将数据分布到多个节点,通过哈希或范围分区来分片,优化了数据写入和查询性能。
4. **WAL(Write-Ahead Log)**:
文档提到了WAL日志,这是一种事务持久化机制,可以保证数据的一致性,并在系统崩溃后能够快速恢复。在LinDB中,WAL用于记录所有待写入的数据,确保数据安全可靠。
5. **Client Acknowledgement**:
客户端确认机制,当客户端接收到服务器的确认消息后,表示数据已被成功写入,提高了数据写入的可靠性。
6. **Rollup(数据压缩)**:
为了优化存储空间和提升查询效率,LinDB实现了Rollup功能,将原始数据进行聚合和压缩,降低数据量的同时保持查询精度。
7. **增强SQL支持**:
随着版本迭代,LinDB增强了SQL查询能力,提供了更丰富的查询语法和函数,使得用户可以通过标准SQL语句操作时序数据,提升了用户体验和数据分析的便捷性。
8. **Kafka集成**:
LinDB开始与Kafka集成,利用Kafka作为消息队列,提高了数据的吞吐量和系统的可扩展性,同时保证了数据流的可靠传输。
9. **Replication(复制)与Fault Tolerance**:
架构演进中,LinDB加强了数据复制和故障容忍机制,通过Leader-Follower模式保证数据的安全性,即使在节点故障时也能保持服务的连续性。
10. **Segment和Shard设计**:
LinDB在存储层采用了Segment(段)的概念,每个Segment代表一段连续的时间窗口内的数据,而Shard则将数据分散到不同的物理节点,实现水平扩展和负载均衡。
11. **TTL(Time To Live)**:
实现了数据的自动过期和清理功能,通过设置TTL,可以控制数据的生命周期,避免无用数据占用存储空间。
12. **Shard Segmentation**:
Shard内部进一步细分为Segment,每个Segment包含一定量的数据,按需分裂和合并,以适应数据增长和查询需求。
这些演进展示了LinDB如何从一个基础的时序数据库发展成为一个具有高可用性、高性能、易扩展性的解决方案,满足了时序数据应用场景日益复杂的需求。
剩余21页未读,继续阅读
2021-10-05 上传
299 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-12-20 上传
168 浏览量
2025-02-17 上传
2025-02-17 上传
2025-02-17 上传

行业报告
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 脱粒机Mod:优化RAM分配提升游戏体验
- SParse: 大规模日志文件高效解析工具
- CC3D电缆摄像机控制器项目发布
- 易语言实现软件后台自动下载与安装技术源码
- Qt实现获取当前屏幕分辨率的方法
- ShaderLab技术在操场渲染效果中的应用
- Apache+PHP+MySQL环境快速搭建工具Appserv-win32介绍
- 酷派F1手机USB驱动下载与安装指南
- 跨平台JavaScript小部件集 - 适用于各种开发环境
- 易语言实现文本数字字母混合检测方法
- SwiftForms:自定义表格与单元格的高效库
- Go语言编程挑战:advent-of-code解析
- 幼儿园财务校务管理系统源码解析
- CintaNotes v3.6.0笔记管理软件高效实用操作指南
- 掌握函数操作,轻松实现字符串分离技巧
- 基于MyEclipse和Struts2的用户注册管理系统
