尚硅谷大数据技术解析:Kafka深度剖析
需积分: 50 170 浏览量
更新于2024-07-15
收藏 2.08MB PDF 举报
"尚硅谷大数据技术之Kafka学习资料,涵盖了Kafka的基础概念、消息队列的应用场景以及两种模式的介绍。"
Kafka是Apache软件基金会开发的一个分布式流处理平台,它最初由LinkedIn设计并开源,现在已经成为大数据领域中不可或缺的组件。作为一个基于发布/订阅模式的消息队列,Kafka主要用于大数据实时处理,它能够高效地处理大量的实时数据流。
在传统的消息队列应用场景中,Kafka展示了其强大的异步处理能力。例如,在注册流程中,当用户填写信息并提交后,系统可以直接将注册信息写入数据库,然后将发送短信的请求放入消息队列,而不是直接调用发送短信接口。这样,用户可以立刻得到注册成功的反馈,而短信发送则在后台异步进行。这种模式带来了诸多好处:
1. **解耦**:消息队列使得生产者(如注册信息的创建)和消费者(如短信发送服务)之间的依赖关系降低,允许各自独立扩展和维护,只需遵守共同的接口规范。
2. **可恢复性**:如果某个处理组件故障,消息仍会保留在队列中,等待系统恢复后继续处理,提高了系统的健壮性。
3. **缓冲**:消息队列可以缓存大量数据,平衡生产和消费的速度差异,避免因消费速度跟不上生产速度而导致的数据丢失或系统压力过大。
4. **灵活性与峰值处理能力**:面对突然的高流量,消息队列能帮助核心组件应对,确保系统在高峰期间保持稳定运行,避免了为偶尔的峰值需求过度配置资源。
5. **异步通信**:消息队列支持异步处理,允许延迟处理,用户可以按需处理队列中的消息,提高系统效率。
消息队列主要有两种模式:
1. **点对点模式**:在这种模式下,每个消息只有一个消费者,消费者主动从队列中拉取消息并消费,消息一旦被消费就会从队列中删除。这种模式适合一对一的通信场景,例如,订单处理系统。
2. **主题(Topic)订阅模式**:在这种模式下,消息发布到一个主题,多个消费者可以订阅同一个主题,消息会被复制到所有订阅者,提供了一对多的通信。这适用于广播或者需要多个服务同时处理同一消息的场景,例如日志收集。
Kafka在设计上强调了高性能、持久化和高可用性,它的分区和复制机制保证了数据的可靠性,同时其低延迟特性和大规模并行处理能力使其在实时数据处理和流计算中广泛应用。通过了解Kafka的基本概念和工作原理,开发者可以更好地利用这一工具来构建可扩展且高效的实时数据处理系统。
尚硅谷大数据技术之 Kafka
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --topic first
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic first
--from-beginning:会把主题中以往所有的数据都读取出来。
6)查看某个 Topic 的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper
hadoop102:2181 --describe --topic first
7)修改分区数
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper
hadoop102:2181 --alter --topic first --partitions 6
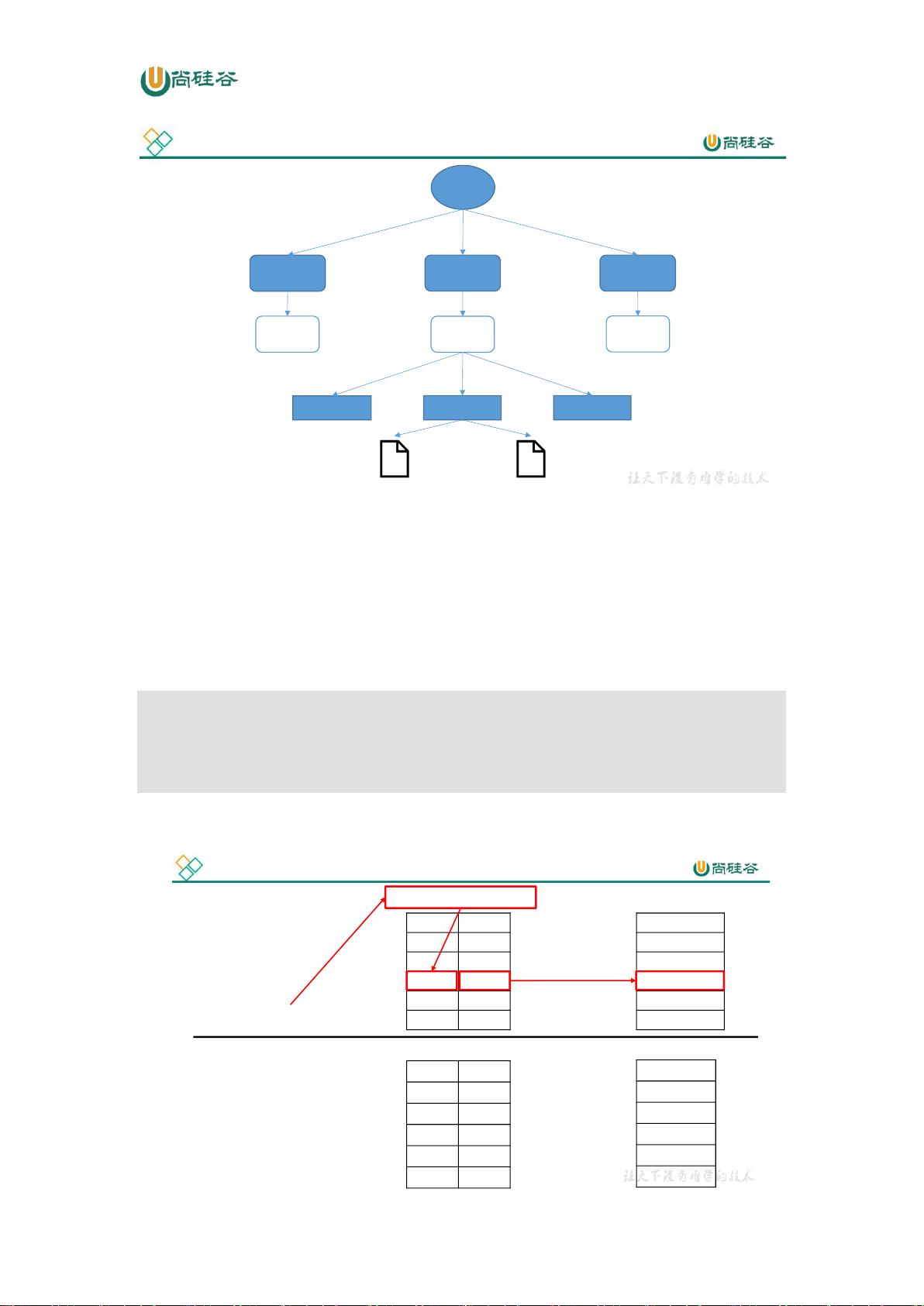
第 3 章 Kafka 架构深入
3.1 Kafka 工作流程及文件存储机制
Kafka 工作流程
Producer
Kafka cluster
broker0
broker1
broker2
TopicA-partition0-leader
TopicA-partition1-leader
TopicA-partition2-leader
TopicA-partition1-follower
TopicA-partition2-follower
TopicA-partition0-follower
0
1
2
3
4
5
0
1
2
3
0
1
2
3
4
0
1
2
3
0
1
2
3
4
5
0
1
2
3
4
Consumer
Consumer
Consumer
group
Zookeeper
offset
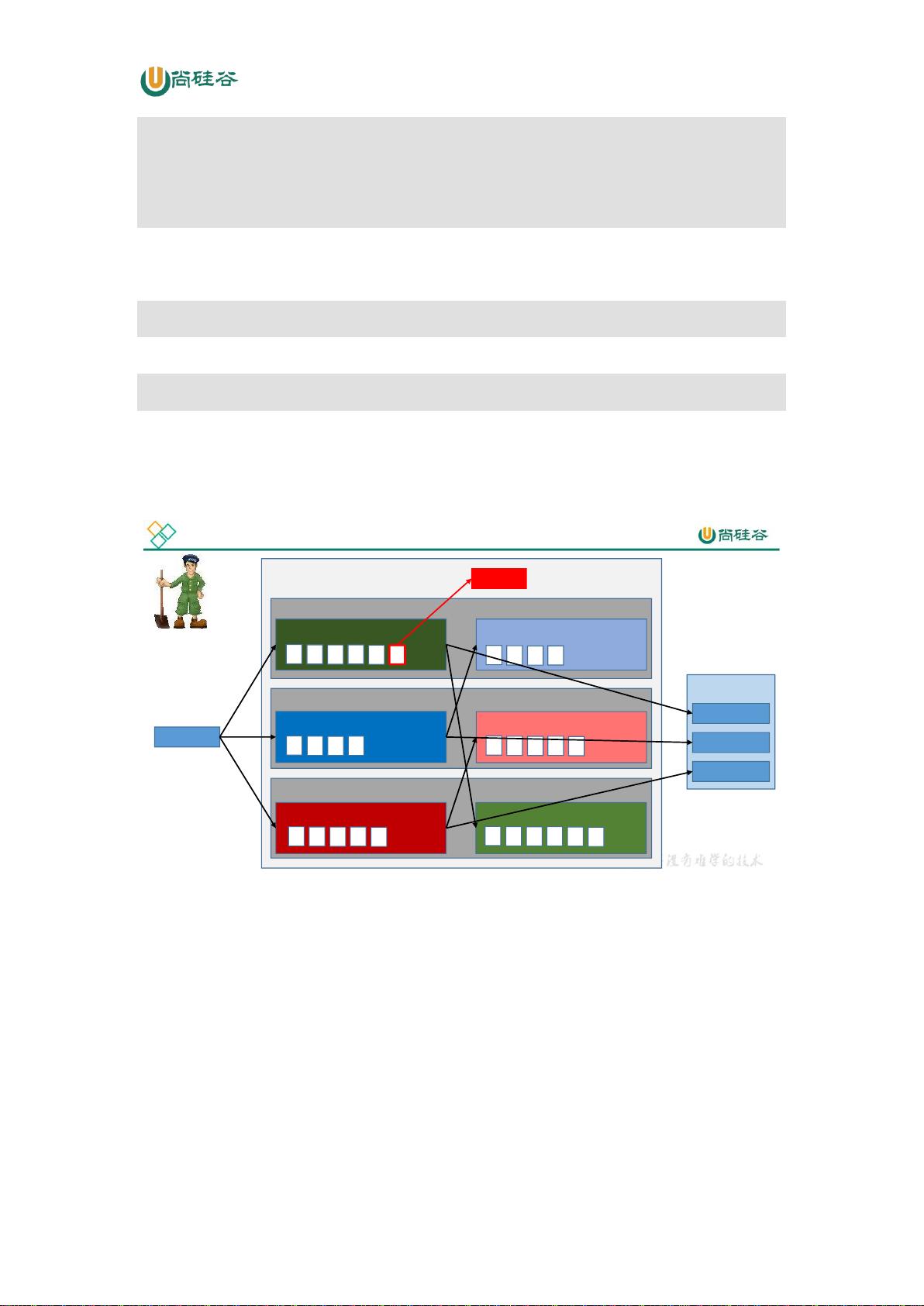
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic
的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文
件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该
log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己
消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
新版本,消费者的相关信息存储在Kafka本身
从消息队列的头开始消费
剩余35页未读,继续阅读
2020-09-10 上传
2023-06-06 上传
642 浏览量
2021-08-23 上传
2024-03-21 上传
2023-12-11 上传

要强不要秃
- 粉丝: 40
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
