Actor-Critic算法解析与PPO推导
需积分: 50 10 浏览量
更新于2024-08-05
7
收藏 599KB PDF 举报
"Actor-Critic框架是强化学习中的一种算法,它结合了Actor(策略网络)和Critic(价值网络)两个部分。该框架在PPO(Proximal Policy Optimization)算法中得到了广泛应用,这是一种高效的近似策略优化方法。本文将依据李宏毅的课程内容对Actor-Critic和PPO算法进行解释和推导。
在Actor-Critic框架中,策略网络(Actor)负责生成执行动作的概率分布,而价值网络(Critic)则估计状态的价值。具体步骤如下:
1. 首先,策略网络(Actor)接收当前状态s,并通过神经网络计算出每个动作的概率action_prob,选择概率最大的动作a执行于环境Env中,得到即时奖励r和新的状态s_。
2. 然后,状态s和s_被输入到价值网络(Critic)中,分别得到对应的预测价值v和v_。接着,利用时间差分(TD)学习方法,计算值函数的误差:td_error = r + γ * v_ - v,其中γ是折扣因子。
3. td_error的平方作为价值网络的损失函数,即𝑐_𝑙𝑜𝑠𝑠=𝑡𝑑_𝑒𝑟𝑟𝑜𝑟²。通过反向传播更新价值网络的参数,以减小这个损失。
4. 在Actor网络中,结合每个动作的概率action_prob和td_error,构造损失函数:𝑎_𝑙𝑜𝑠𝑠=−log(𝑎𝑐𝑡𝑖𝑜𝑛_𝑝𝑟𝑜𝑏)∗𝑡𝑑_𝑒𝑟𝑟𝑜𝑟。这个损失函数鼓励Actor网络选择那些导致高奖励的动作。同样通过反向传播更新策略网络的参数。
5. 上述步骤反复进行,不断迭代优化策略和价值网络。
强化学习的基本组件包括Actor(策略)、Env(环境)和Reward Function(奖励函数)。环境和奖励函数是固定的,学习的目标是通过策略网络(Actor,也称为Policy π)来最大化在一个episode中的总奖励Totalreward:𝑅=∑𝑟𝑡/𝑇,其中𝑡=1...𝑇。
策略π是一个参数为𝜃的神经网络,根据状态state输出每个动作的概率,然后选择一个动作执行。在一系列状态-动作对组成的轨迹𝜏={𝑠1,𝑎1,𝑠2,𝑎2,…,𝑠𝑇,𝑎𝑇}中,我们可以计算Actor参数为𝜃时,轨迹τ发生的概率𝑝𝜃(𝜏),以及轨迹回报𝑅(𝜏)的期望值𝑅𝜃。
为了最大化𝑅𝜃,我们需要计算梯度∇𝑅𝜃。通过链式法则和重要性采样,我们可以得到近似的梯度表达式。这使得我们可以用梯度上升法来优化策略网络,从而改进策略,使其更倾向于产生高奖励的行动序列。
PPO算法是一种限制策略更新步长的策略梯度方法,防止策略在网络更新中发生过大的跳跃,从而提高学习稳定性。通过设置一个近似Kullback-Leibler(KL)散度的阈值,PPO确保策略的更新在旧策略附近进行。
Actor-Critic框架结合了策略优化和价值估计,而PPO算法则提供了一种在Actor-Critic框架下有效且稳定的策略优化策略。这种结合使得强化学习算法能够有效地在复杂环境中学习并优化决策策略。"
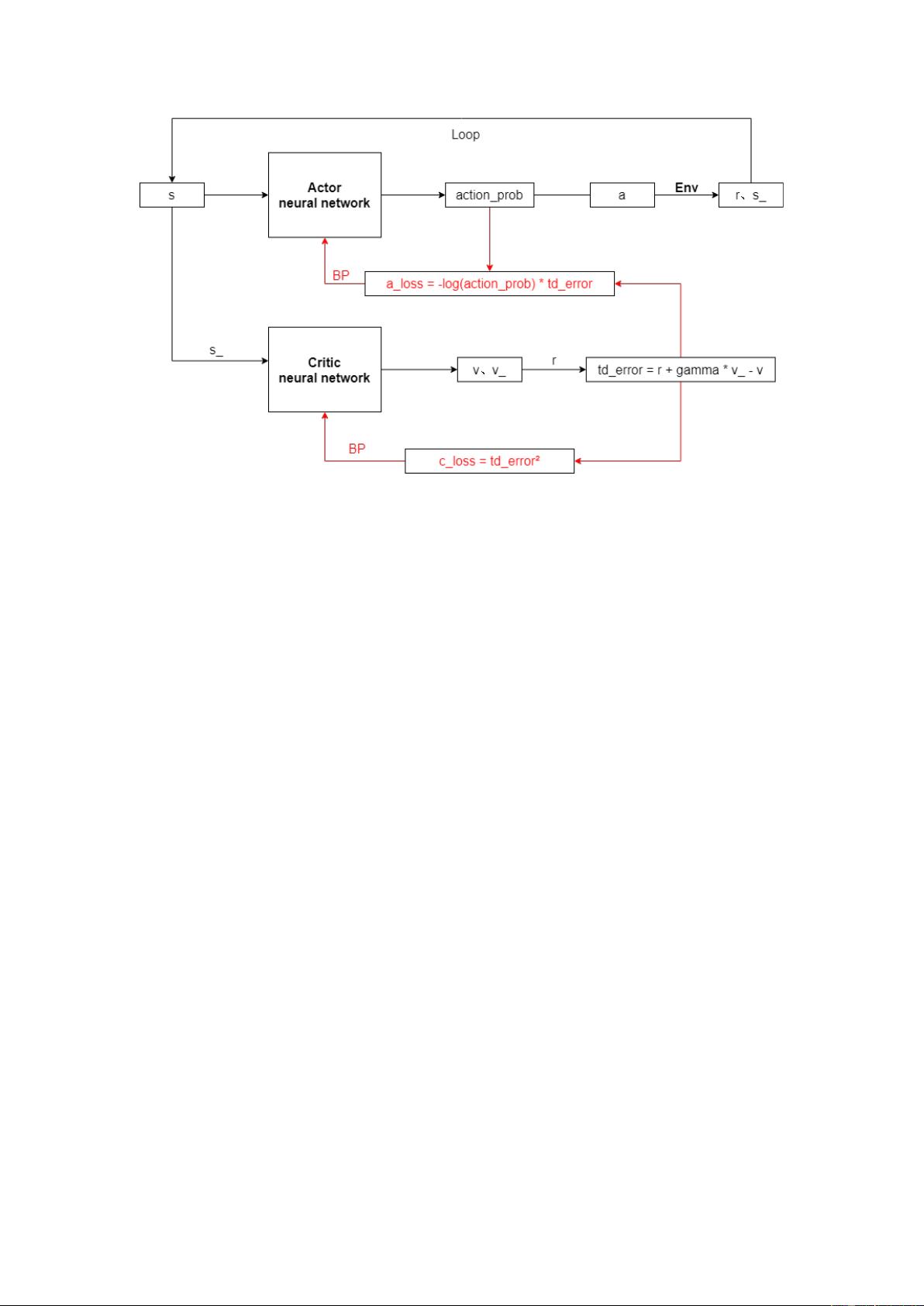
Actor-Critic 框架图
(1) 将当前状态 s 输入到 Actor 网络中,计算出选择每个动作的概率 action_prob,
输出概率最大的动作 a,在环境 Env 中执行 a,得到奖励 r 和下一个状态 s_;
(2) 将 s 和 s_分别输入 Critic 网络中,输出 v 和 v_,再结合 r 使用时间差分
(Temporal-difference,TD)方法计算值函数,即 ;
(3) 使用 td_error 的平方作为 Critic 网络的损失函数,即
²
,反
向传播更新网络参数;
(4) 结合第一步中每个动作的概率和 td_error 得到 Actor 网络的损失函数,即
,反向传播更新网络参数;
(5) 循环(1)~(4)。
下载后可阅读完整内容,剩余7页未读,立即下载
2021-03-22 上传
2021-09-30 上传
2023-06-20 上传
2023-09-05 上传
2024-10-31 上传
2024-10-31 上传
2023-03-29 上传
2024-10-31 上传

AllesGute666
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- netgamemud.rar_Delphi_
- hakuen
- RxSwift实现ComposableArchitecture-Swift开发
- Crewmate:“我们之间”交叉兼容服务器,用于自定义游戏模式和改装!
- log4j2-json-layout:Log4J 2 JSON布局插件
- fromedi:EDI到人类语言的翻译器
- OSEK完整版源码.rar
- DS1302.zip
- PyQt:PyQt示例(PyQt各种测试和例子)PyQt4 PyQt5
- Emoji Keyboard-crx插件
- clockwork-rnn-in-pytorch:该存储库包含使用pytorch的发条rnn的实现
- 高仿某讯网平台登录页
- 适用于iOS的完全可自定义的水平圆选择器视图-Swift开发
- 客户关系管理
- LCD1602_4X4key.rar_单片机开发_C/C++_
- This-Repo-Has-1635-Stars:对,是真的
