时间序列早期分类:基于排名的交叉熵损失方法
7 浏览量
更新于2024-06-23
收藏 4.81MB PPTX 举报
"这篇论文介绍了一种名为Ranking-based Cross-Entropy Loss (RCE) 的新方法,用于时间序列的早期分类。该方法被应用于重症监护病房中的早期败血症诊断等时间敏感的应用中,旨在在有限的数据观测下提高分类的准确性和及时性。RCE方法通过学习时间序列数据中的类别特征和早期顺序,改善了分类器的边界清晰度,提升了每个时间步的分类精度。此外,通过重点关注高阶样本,加速了训练过程。实验证明,这种方法在三个真实数据集上均优于基线模型。"
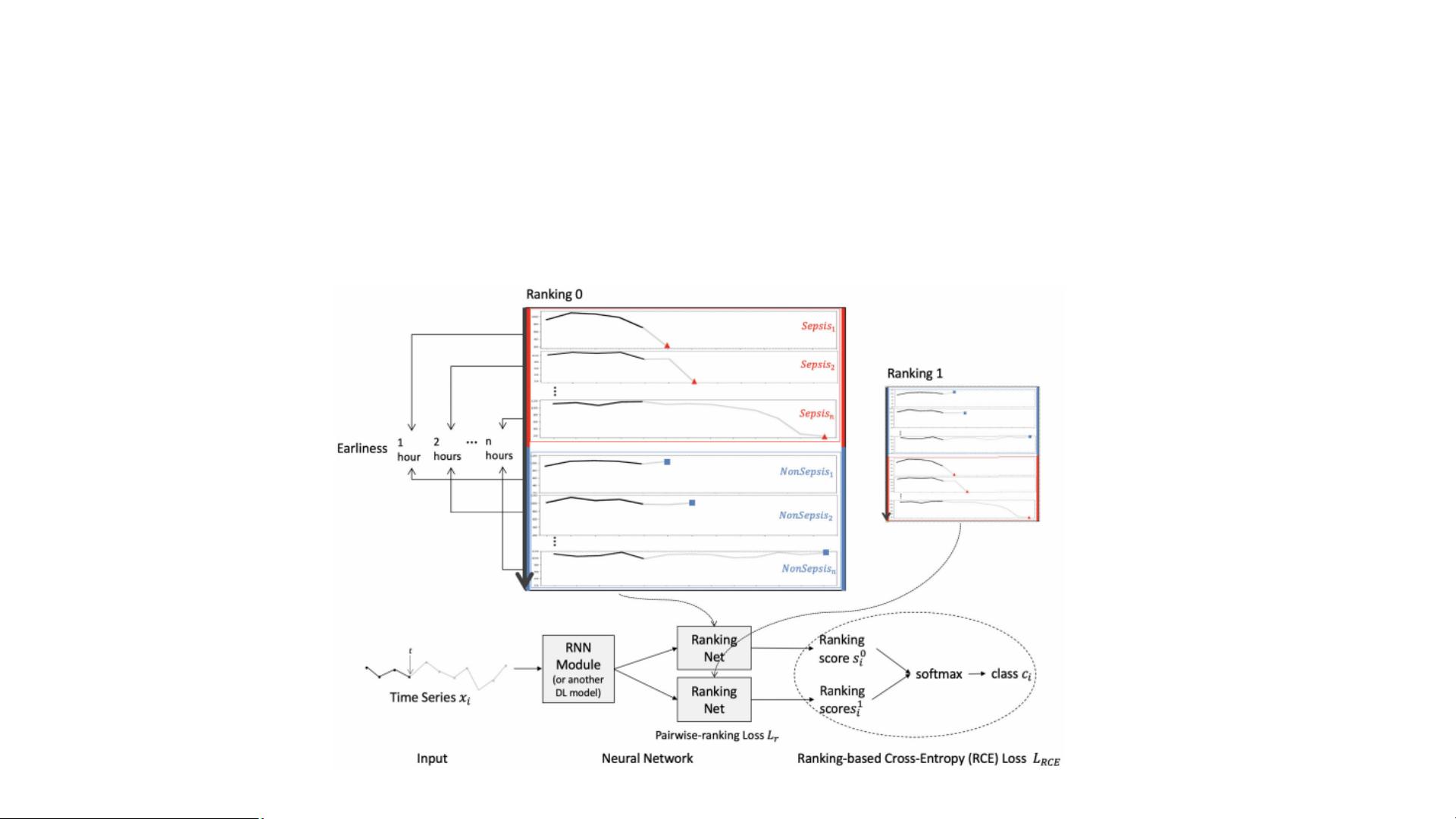
《Ranking-Based Cross-Entropy Loss 阅读PPT》讨论的是如何解决时间序列早期分类(Early Classification of Time Series, ECTS)的问题。在许多应用中,如ICU的早期败血症诊断,早期识别是至关重要的,因为它能提供宝贵的时间来采取干预措施。传统的分类方法往往在追求准确性的同时牺牲了早期性,因为模型倾向于等待更多的数据输入才做出决策。
论文指出,传统的交叉熵损失函数在处理ECTS问题时存在不足,因为它无法有效地提取和利用时间序列中的早期信息。RCE方法的创新之处在于它引入了一个排名机制,使得模型能够根据时间阶段调整概率分布的边界,增强类别间的区分度,从而在各个时间步骤上提高分类的准确性。同时,通过关注高阶样本,可以更快地学习到关键特征,提升模型训练效率。
问题的定义中,ECTS任务是给定一组标记的时间序列数据集,目标是构建一个能够在早期时间点准确分类时间序列的模型。每个时间序列由一系列连续的观测值组成,类别信息可能在序列的早期阶段难以捕捉。RCE方法的目标是创建一个分类器,它能在任何时间点都做出高精度的预测,而不仅仅是某个特定时间点。
在实验部分,作者展示了RCE方法在多个真实数据集上的优越性能,证明了其对于早期分类问题的有效性和通用性。提供的代码链接(https://github.com/SCXsunchenxi/RCE文献阅读12挑战)允许研究者和开发者进一步探索和复现这些结果。
这篇论文提出的RCE损失函数为时间序列的早期分类提供了一个新的视角,通过改进传统交叉熵损失的功能,实现了更早、更准确的分类,这对于时间敏感的应用具有重大意义。
5
A. Problem Formulation
Definition 3 (Class Order, CO):类序CO=c
1
▷c
2
··· ▷c
M
记录了类集C的排序顺序(M表示类的个数)。c
i
▷c
j
表示c
i
在c
j
之前。对
于二元分类,有两种类序,c
0
▷c
1
和c
1
▷c
0
。对于三种分类,有三种分类顺序:c
1
▷c
2
▷c
3
、c
2
▷c
1
▷c
3
和c
3
▷c
1
▷c
2
。对于n分类,有n个
类顺序,每个类都在顶部(不应该是全排列吗?三种123,132,213,231,312,321)。因此,简化表示为CO=c
i
▷c
{m\i}
。
c
{m\i}
={c
m
|m∈{1,…,M}−{i}}。将n类数据集改为二进制类数据集的话,则数据分为属于c
i
和不属于c
i
。二进制类被简单地标记为
{c
0
, c
1
}。
剩余21页未读,继续阅读
2018-11-15 上传
2021-12-11 上传
2021-02-21 上传
2021-05-29 上传
2021-02-23 上传
2022-05-30 上传
2019-02-12 上传
2021-02-05 上传

WXiujie123456
- 粉丝: 515
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
