LightGBM深度解析:原理、优势与实战应用
版权申诉
13 浏览量
更新于2024-06-21
收藏 1.74MB PDF 举报
LightGBM最强解析深入探讨了这个高效、并行化的GBDT(梯度提升决策树)框架。首先,我们回顾了GBDT的基本概念,它作为机器学习中的经典模型,以其良好的训练效果和抵抗过拟合的能力,在诸如多分类、点击率预测和搜索排序等领域大放异彩。然而,传统的GBDT在处理大规模数据时面临挑战,因为每次迭代都需要遍历整个数据集,这在内存限制和时间效率上存在瓶颈。
LightGBM正是针对这一问题提出的解决方案。它旨在解决XGBoost(另一个知名GBDT工具)存在的问题,尤其是XGBoost依赖于预排序策略构建决策树,这虽然能精确找到分割点,但带来了显著的空间消耗,因为它需要存储特征值和特征的预排序信息。相比之下,LightGBM通过采用更优化的技术,如利用稀疏性减少内存占用,同时支持并行计算和分布式训练,实现了更快的训练速度和更低的内存需求。
LightGBM的核心优化包括:
1. **列式存储**:它采用了列式而非行式存储数据,减少了内存占用,因为每个特征的值只存储一次,而不是每个样本的所有特征。
2. **特征选择**:LightGBM采用了更聪明的特征选择策略,它仅在构建每个叶子节点时考虑一部分特征,这样既减少了计算量又保持了模型的准确性。
3. **叶子编码**:它使用一种称为“叶子编码”的方法,使得数据在叶子节点的表示更加紧凑,进一步减小内存占用。
4. **并行分发**:LightGBM支持多核并行计算,通过任务分解加速模型训练,特别是在大数据集上显著提高效率。
5. **优化算法**:LightGBM采用了一种新颖的优化算法,比如二阶泰勒展开,提高了模型训练的速度。
总结来说,LightGBM通过这些创新改进,不仅解决了GBDT在处理大规模数据时的性能瓶颈,还提升了模型的训练效率和准确性,使其成为工业级应用中的首选算法之一,特别是在Kaggle等数据挖掘竞赛中占据了主导地位。通过深入理解LightGBM的工作原理和代码实现,数据科学家和工程师可以更好地利用这个强大的工具来应对复杂的机器学习任务。
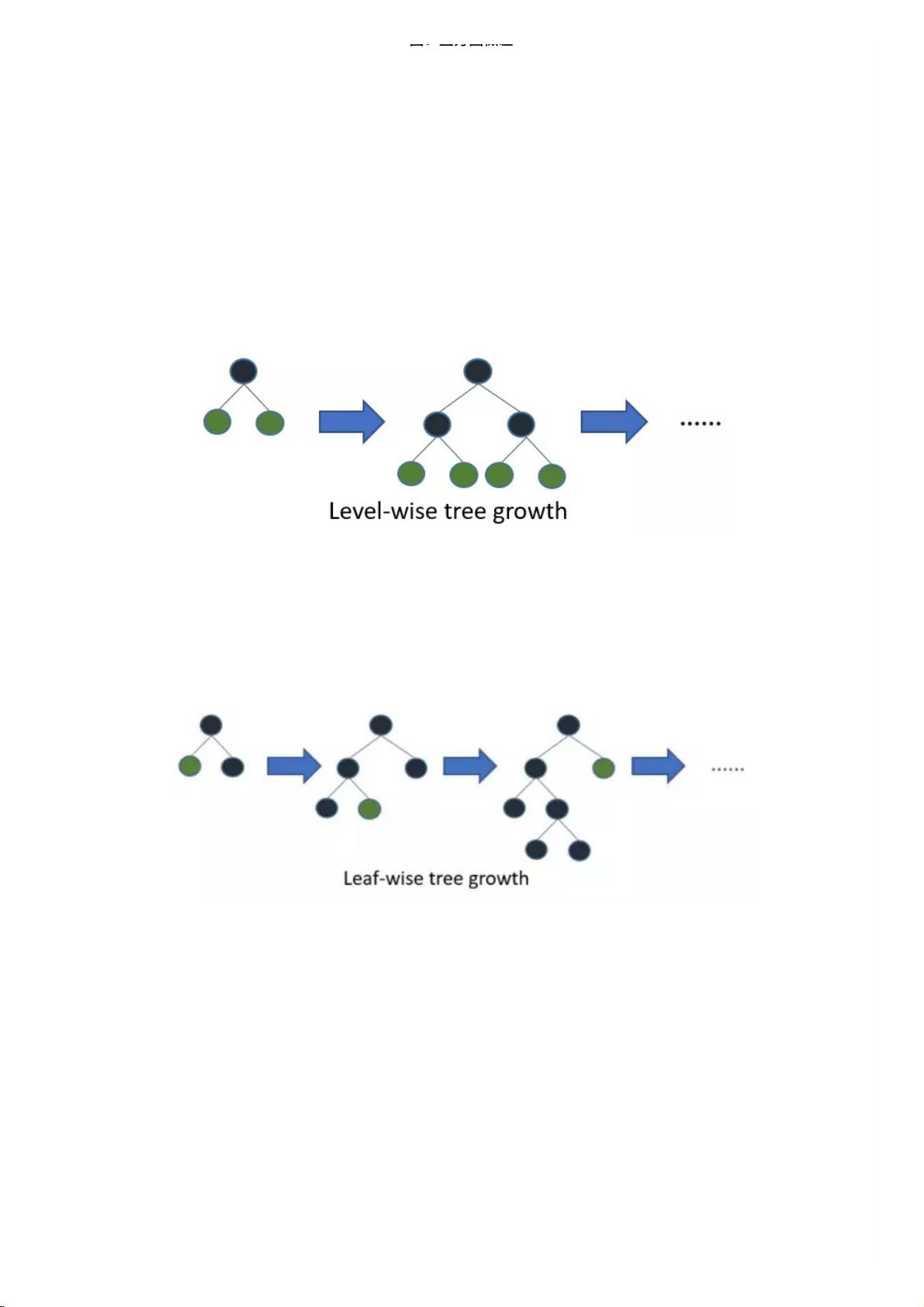
图:直⽅图做差
注意: XGBoost 在进⾏预排序时只考虑⾮零值进⾏加速,⽽ LightGBM 也采⽤类似策略:只⽤⾮零特征构建直⽅图。
2.2 带深度限制的 Leaf-wise 算法
在Histogram算法之上,LightGBM进⾏进⼀步的优化。⾸先它抛弃了⼤多数GBDT⼯具使⽤的按层⽣⻓ (level-wise) 的决策
树⽣⻓策略,⽽使⽤了带有深度限制的按叶⼦⽣⻓ (leaf-wise) 算法。
XGBoost 采⽤ Level-wise 的增⻓策略,该策略遍历⼀次数据可以同时分裂同⼀层的叶⼦,容易进⾏多线程优化,也好控制
模型复杂度,不容易过拟合。但实际上Level-wise是⼀种低效的算法,因为它不加区分的对待同⼀层的叶⼦,实际上很多叶
⼦的分裂增益较低,没必要进⾏搜索和分裂,因此带来了很多没必要的计算开销。
图:按层⽣⻓的决策树
LightGBM采⽤Leaf-wise的增⻓策略,该策略每次从当前所有叶⼦中,找到分裂增益最⼤的⼀个叶⼦,然后分裂,如此循
环。因此同Level-wise相⽐,Leaf-wise的优点是:在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精
度;Leaf-wise的缺点是:可能会⻓出⽐较深的决策树,产⽣过拟合。因此LightGBM会在Leaf-wise之上增加了⼀个最⼤深度
的限制,在保证⾼效率的同时防⽌过拟合。
图:按叶⼦⽣⻓的决策树
2.3 单边梯度采样算法
Gradient-based One-Side Sampling 应该被翻译为单边梯度采样(GOSS)。GOSS算法从减少样本的⻆度出发,排除⼤部
分⼩梯度的样本,仅⽤剩下的样本计算信息增益,它是⼀种在减少数据量和保证精度上平衡的算法。
AdaBoost中,样本权重是数据重要性的指标。然⽽在GBDT中没有原始样本权重,不能应⽤权重采样。幸运的是,我们观察
到GBDT中每个数据都有不同的梯度值,对采样⼗分有⽤。即梯度⼩的样本,训练误差也⽐较⼩,说明数据已经被模型学习
得很好了,直接想法就是丢掉这部分梯度⼩的数据。然⽽这样做会改变数据的分布,将会影响训练模型的精确度,为了避免
此问题,提出了GOSS算法。
GOSS是⼀个样本的采样算法,⽬的是丢弃⼀些对计算信息增益没有帮助的样本留下有帮助的。根据计算信息增益的定义,
梯度⼤的样本对信息增益有更⼤的影响。因此,GOSS在进⾏数据采样的时候只保留了梯度较⼤的数据,但是如果直接将所
剩余16页未读,继续阅读
489 浏览量
2023-12-11 上传
2024-08-29 上传
2023-10-18 上传
2024-08-29 上传
1847 浏览量
2024-08-29 上传
245 浏览量

普通网友
- 粉丝: 1277
- 资源: 5623
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高速电路设计 A Practical Guide to High-Speed Printed-Circuit-Board
- 2006年4月二级C语言笔试试题.doc
- 华为编程规范.pdf
- Tapestry开发指南.pdf
- liferay portlet二次开发宝典
- C#自学笔记(崔北为)
- 一些软件公司的笔试题
- FORTRAN 77
- STATA 面板数据处理
- Beginning PHP and Oracle From Novice to Professional.2007
- C#,深入浅出全接触
- C#.NET 开发者手册
- 2410根文件系统实验
- C# Language Specification
- Flex 3 Cookbook 中文版.pdf
- s3c2410uboot移植实验
