信息检索模型详解:从布尔到向量空间
"该教学资料是关于信息检索模型的PPT,主要涵盖了信息检索模型的基本概念、形式化定义以及常见的模型分类,如布尔模型和向量空间模型等。此外,还详细介绍了布尔模型的优缺点以及向量空间模型的工作原理。"
在信息检索领域,模型是用来描述文档和用户查询的表示形式,以及它们之间相关性的理论框架。模型是通过数学工具对现实世界问题的抽象描述,其目标是使模型的输出尽可能接近实际世界的输出。信息检索模型的四元素包括文档集合(D)、查询集合(Q)、建模框架(F)和排序函数(R),这些元素共同决定了信息检索的效果。
布尔模型是最经典的检索模型之一,基于集合论和线性代数。它使用AND、OR和NOT三个逻辑运算符来构造查询,例如,查询"病毒AND(计算机OR电脑)ANDNOT医药"。布尔模型的优点在于其形式简洁、查询语言表达简单、实现容易且计算速度快。然而,它也有明显的局限,如二值判断标准导致的相关性单一,无法进行相关性排序,以及布尔表达式难以完全体现用户需求,可能导致检索结果过多或过少。
向量空间模型(VSM)是一种更复杂的检索模型,它将文档和查询视为高维空间中的向量。每个文档和查询都是由共同的词项(基向量)构成的向量,相似度通过计算两个向量之间的夹角或使用其他相关性度量来确定。这种方法允许对相关性进行连续的度量,从而提供更好的检索性能。VSM的一个关键点是选择合适的相似度计算方法,例如余弦相似度,来衡量向量间角度的大小,角度越小,表示两个向量(即文档和查询)越相似。
除此之外,信息检索模型还包括概率模型、结构化模型等,这些模型在处理复杂查询、不确定性信息和语义理解等方面具有不同的优势。例如,概率模型如BM25,利用概率理论来估算文档与查询的相关性;而神经网络模型则利用深度学习技术来捕捉文本的语义信息。
信息检索模型是信息检索系统的核心,不同的模型适用于不同的检索场景和需求。理解并选择合适的模型对于提高信息检索的效率和准确性至关重要。
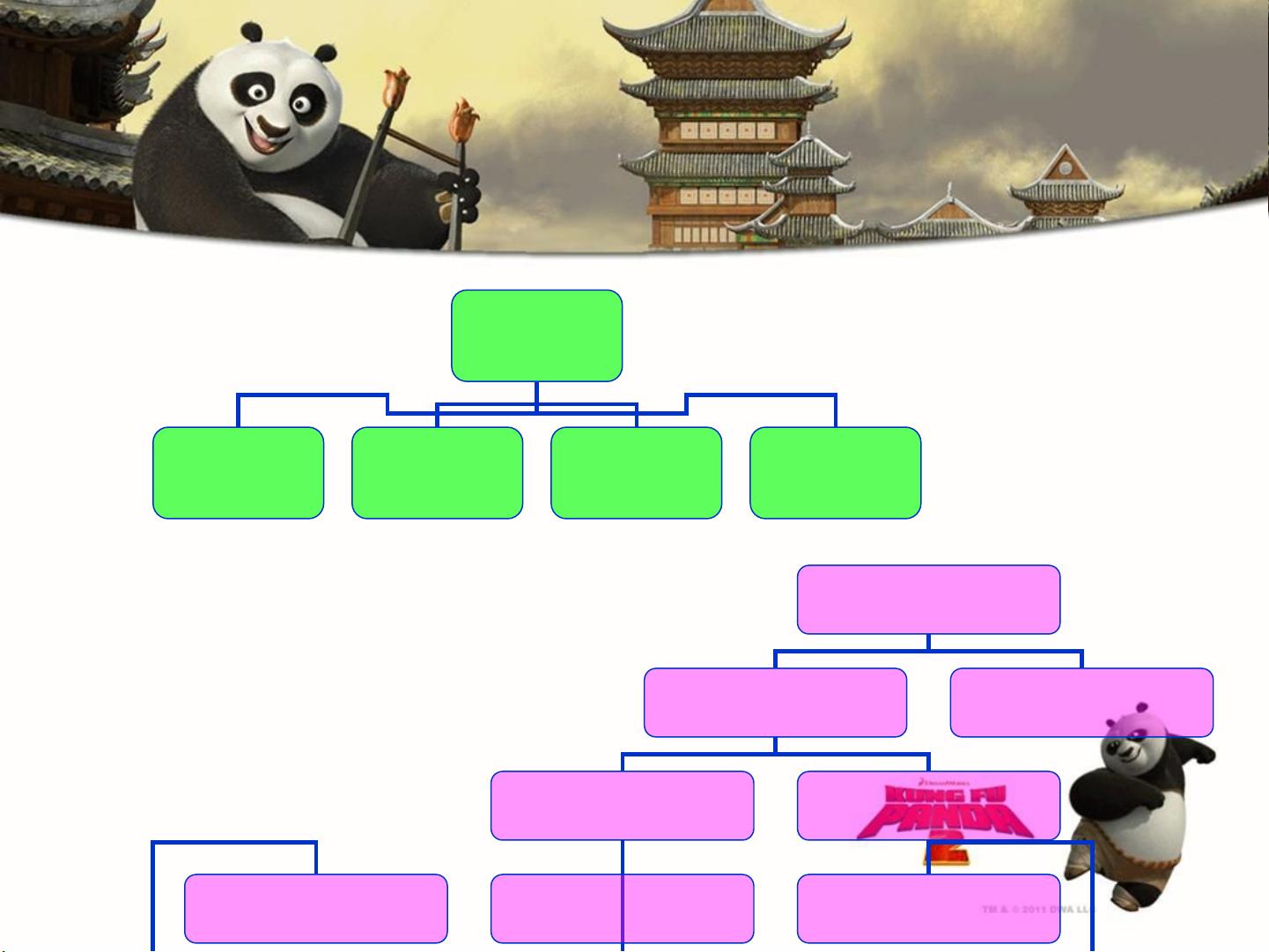
信息检索模型的形式化定义及分类
信息检索的四元素
信息检索模型分类
信息检索模型
D( 文档集合 )
由文档逻辑视
图表示
Q( 查询集合 )
由查询需求的逻辑
视图表示
F (建模的框架)
R ( q
i
, d
j
)
(排序函数)
信息检索模型
检索模型
浏览模型
(结构化导航、
超链接)
经典模型
(根据数学基础)
结构化模型
集合论模型
(布尔模型)
代数模型
(向量空间模型)
概率模型
( BY25 )
剩余14页未读,继续阅读
1013 浏览量
304 浏览量
163 浏览量
262 浏览量
935 浏览量
130 浏览量

xijianqiuxue
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- DeepFreeze密码移除工具6.x版本使用教程
- MQ2烟雾传感器无线报警器项目解析
- Android实现消息推送技术:WebSocket的运用解析
- 利用jQuery插件自定义制作酷似Flash的广告横幅通栏
- 自定义滚动时间选择器,轻松转换为Jar包
- Python环境下pyuvs-rt模块的使用与应用
- DLL文件导出函数查看器 - 查看DLL函数名称
- Laravel框架深度解析:开发者的创造力与学习资源
- 实现滚动屏幕背景固定,提升网页高端视觉效果
- 遗传算法解决0-1背包问题
- 必备nagios插件压缩包:实现监控的关键
- Asp.Net2.0 Data Tutorial全集深度解析
- Flutter文本分割插件flutter_break_iterator入门与实践
- GD Spi Flash存储器的详细技术手册
- 深入解析MyBatis PageHelper分页插件的使用与原理
- DELPHI实现斗地主游戏设计及半成品源码分析
