




可解释机器学习:历史、现状与挑战
需积分: 16 184 浏览量
更新于2024-07-14
收藏 481KB PDF 举报
"这篇文章概述了可解释机器学习(IML)的历史、当前的状态以及面临的挑战。作者们来自慕尼黑大学统计学系,他们详细介绍了从20世纪60年代开始,可解释机器学习在回归建模和基于规则的学习中的发展,并强调了近年来该领域内的新方法,包括对深度学习和树形集成模型的特定解释技术。IML方法主要通过分析模型组件、研究输入扰动的敏感性或分析局部和全局的模型近似来实现解释。目前,许多方法已经从理论研究发展到实际应用阶段。"
可解释机器学习(IML)是一个日益重要的领域,尤其是在人工智能和数据科学中,因为理解和信任模型的决策过程是至关重要的。在20世纪60年代,可解释性主要集中在回归模型和基于规则的系统,如决策树,这些模型由于其内在的透明性而被认为是可解释的。这些早期的方法奠定了可解释性研究的基础,但直到最近几年,随着复杂模型如神经网络的普及,对模型解释的需求变得更加迫切。
近年来,IML的研究经历了爆炸性增长,提出了一系列新的模型 agnostic 方法,这些方法不依赖于特定的模型结构,而是关注如何揭示模型的决策逻辑。例如,局部可解释性模型如LIME(Local Interpretable Model-agnostic Explanations)和SHAP(SHapley Additive exPlanations)通过对单个预测实例的解释来帮助理解模型行为。同时,针对深度学习的解释技术,如可视化工具和注意力机制,也得到了发展,帮助用户理解神经网络内部的工作原理。
此外,对于树形模型,如随机森林和梯度提升机,有专门的解释方法,如PDP(Partial Dependence Plots)和ICE(Individual Conditional Expectation)图,它们展示了特征与预测目标之间的关系。这些方法提供了一种全局视角,帮助我们理解模型是如何根据输入特征来做出预测的。
IML领域的挑战依然存在,包括如何量化解释的准确性,如何处理黑箱模型的复杂性,以及如何在保证模型性能的同时提高可解释性。此外,还有隐私问题,解释过程中可能暴露敏感信息,以及在大数据和高维空间中的解释效率问题。
随着越来越多的IML方法从理论研究走向实践应用,这个领域正在逐步成熟,为用户提供更多工具来理解并信任AI系统的决策。未来的趋势可能包括开发更加自动化和集成化的解释工具,以及建立一套标准和准则来评估模型的可解释性。可解释机器学习不仅是技术发展的必然结果,也是确保人工智能安全、公正和可信的关键步骤。
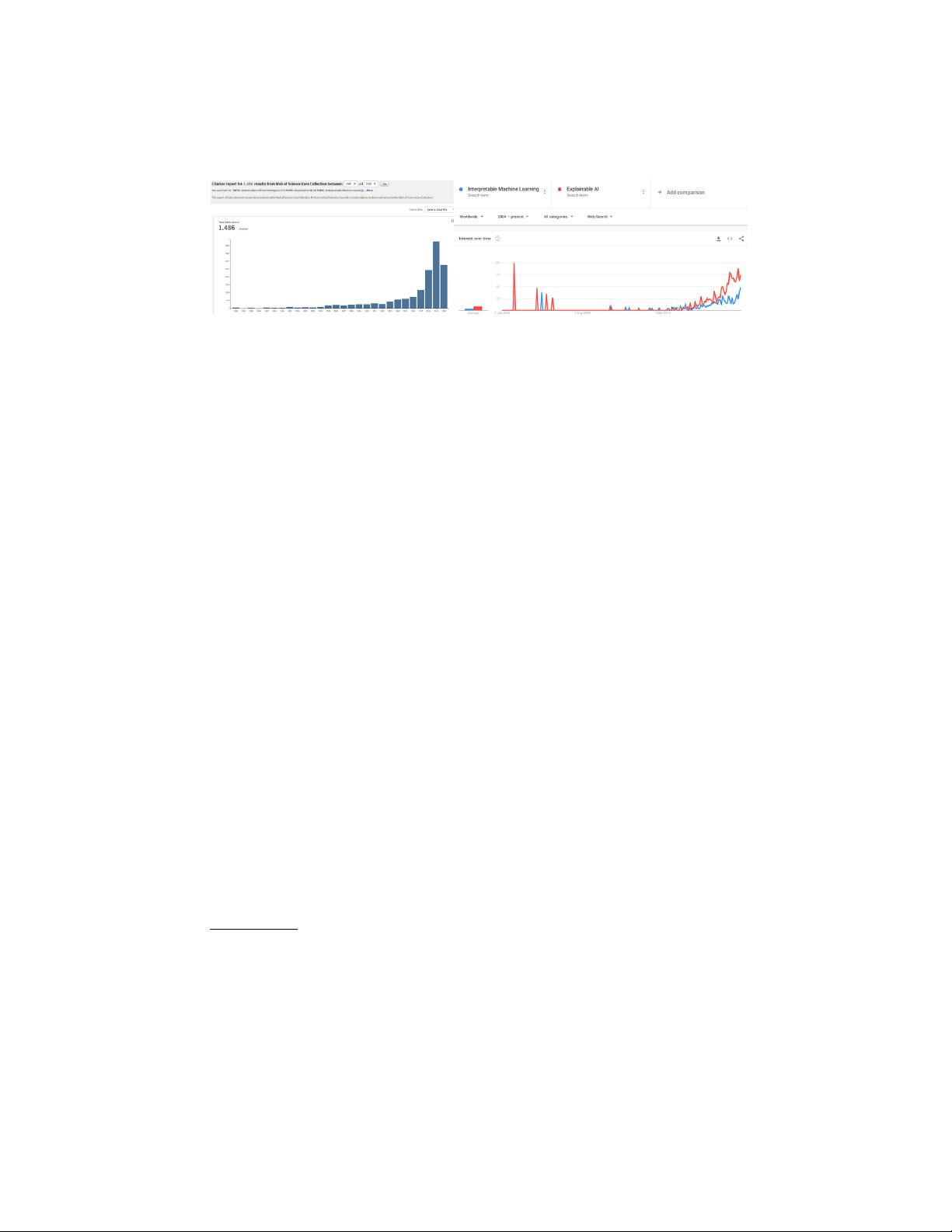
IML - History, Methods, Challenges 3
Fig. 1. Left: Citation count for research articles with keywords “Interpretable Ma-
chine Learning” or “Explainable AI” on Web of Science (accessed August 10, 2020).
Right: Google search trends for “Interpretable Machine Learning” and “Explainable
AI” (accessed August 10, 2020).
rule-based ML serve as stand-alone ML algorithms, but also as building blocks
for many IML approaches.
3 Today
IML has reached a first state of readiness. Research-wise, the field is maturing in
terms of methods surveys [75,41,120,96,1,6,23,15], further consolidation of terms
and knowledge [42,22,82,97,88,17], and work about defining interpretability or
evaluation of IML methods [74,73,95,49]. We have a better understanding of
weaknesses of IML methods in general [75,79], but also specifically for methods
such as permutation feature importance [51,110,7,111], Shapley values [57,113],
counterfactual explanations [63], partial dependence plots [51,50,7] and saliency
maps [2]. Open source software with implementations of various IML methods
is available, for example, iml [76] and DALEX [11] for R [91] and Alibi [58] and
InterpretML [83] for Python. Regulation such as GDPR and the need for ML
trustability, transparency and fairness have sparked a discussion around further
needs of interpretability [122]. IML has also arrived in industry [36], there are
startups that focus on ML interpretability and also big tech companies offer
software [126,8,43].
4 IML Methods
We distinguish IML methods by whether they analyze model components, model
sensitivity
3
, or surrogate models, illustrated in Figure 4.
4
3
Not to be confused with the research field of sensitivity analysis, which studies the
uncertainty of outputs in mathematical models and systems. There are methodolog-
ical overlaps (e.g., Shapley values), but also differences in methods and how input
data distributions are handled.
4
Some surveys distinguish between ante-hoc (or transparent design, white-box models,
inherently interpretable model) and post-hoc IML method, depending on whether
下载后可阅读完整内容,剩余14页未读,立即下载
191 浏览量
375 浏览量
112 浏览量
348 浏览量
点击了解资源详情
2021-01-27 上传
530 浏览量
2021-01-27 上传
点击了解资源详情

syp_net
- 粉丝: 158
 我的内容管理
展开
我的内容管理
展开








最新资源
- MastodonImageBot:从danbooru自动发布图像的C#机器人
- 模拟电路基础入门指南:快速掌握要点
- 探索OpenGL编程:随书光盘源码详解
- NSGA换热网络优化算法在matlab与C/C++中的实现
- JSTL必备jar包集合在Java中的应用
- 周宏版数字电路与逻辑设计课后习题答案
- OpenGL粒子系统模拟范例教程
- 初学者入门:Eclipse与Hibernate结合实例
- 跨平台Mastodon客户端:基于Vue和Electron技术
- ChromePass:快速找回Chrome浏览器密码工具
- 简单贪吃蛇游戏教程与Visual C++开发实践
- PHP5.4 Redis扩展实现与优化指南
- Winform分页控件的实现与优化指南
- 黑苹果系统必备Kext驱动介绍与指南
- 初学者适用ASP.NET网上书店管理系统教程
- 深入理解C++编程高效实践指南






















