Sora视频生成:LDM与DiT结合的高效流程
DOCX格式 | 277KB |
更新于2024-08-03
| 134 浏览量 | 举报
"Sora是一种视频生成技术,它结合了Latent Diffusion Model (LDM)和Diffusion Transformer (DiT)。LDM通过自编码器对高分辨率图像进行无损压缩,然后用扩散模型训练低分辨率的压缩图像,以减少计算需求。DiT则是在LDM基础上用Transformer替换U-Net,增强模型的扩展性和性能。Sora的创新在于其视频压缩网络,能同时在空间和时间上压缩视频,以及使用空间时间补丁对数据进行处理,适应不同分辨率、长宽比和时长的视频输入,无需预处理。"
Sora视频生成流程的核心在于其高效利用计算资源的方法和独特的模型架构。LDM模型是基于Stable Diffusion的,主要解决了传统扩散模型在处理高分辨率图像时计算量过大的问题。LDM通过训练一个自编码器,能够将512x512的图像压缩到64x64,同时保持图像质量几乎不变。随后,扩散模型被训练来拟合这个低分辨率的压缩图像,从而在有限的计算资源下生成高分辨率的图像。
Transformer架构在深度学习领域中因其强大的表征能力和参数扩展性而备受青睐。DiT(Diffusion Transformer)正是基于这一原理,将LDM中的U-Net结构替换为Transformer,以提高模型的性能。这使得Sora具备了更高效的图像生成能力。
Sora的独特之处在于其视频压缩网络,该网络不仅能够在空间维度上压缩图像,还能够在时间维度上压缩视频序列。通过自编码器,Sora能够处理不同大小、分辨率和长度的视频,将其转化为统一的压缩格式,方便后续处理。这种压缩并不牺牲原始数据的特性,而是将其转换为模型易于处理的形式。
在处理压缩后的视频数据时,Sora采用“空间时间补丁”(SpaceTimePatches)的概念,将数据进一步细分为小块,便于模型进行逐块处理。这种方式允许Sora灵活地处理各种输入视频,无需进行额外的缩放或裁剪等预处理步骤。
Sora通过巧妙的模型设计和数据处理策略,实现了高效、灵活的视频生成,能够应对多样化的输入条件,且降低了对计算资源的需求。这种技术在AIGC(人工智能生成内容)领域具有重要的应用潜力,可以用于创造高质量的视频内容,如动画、特效、甚至电影场景。
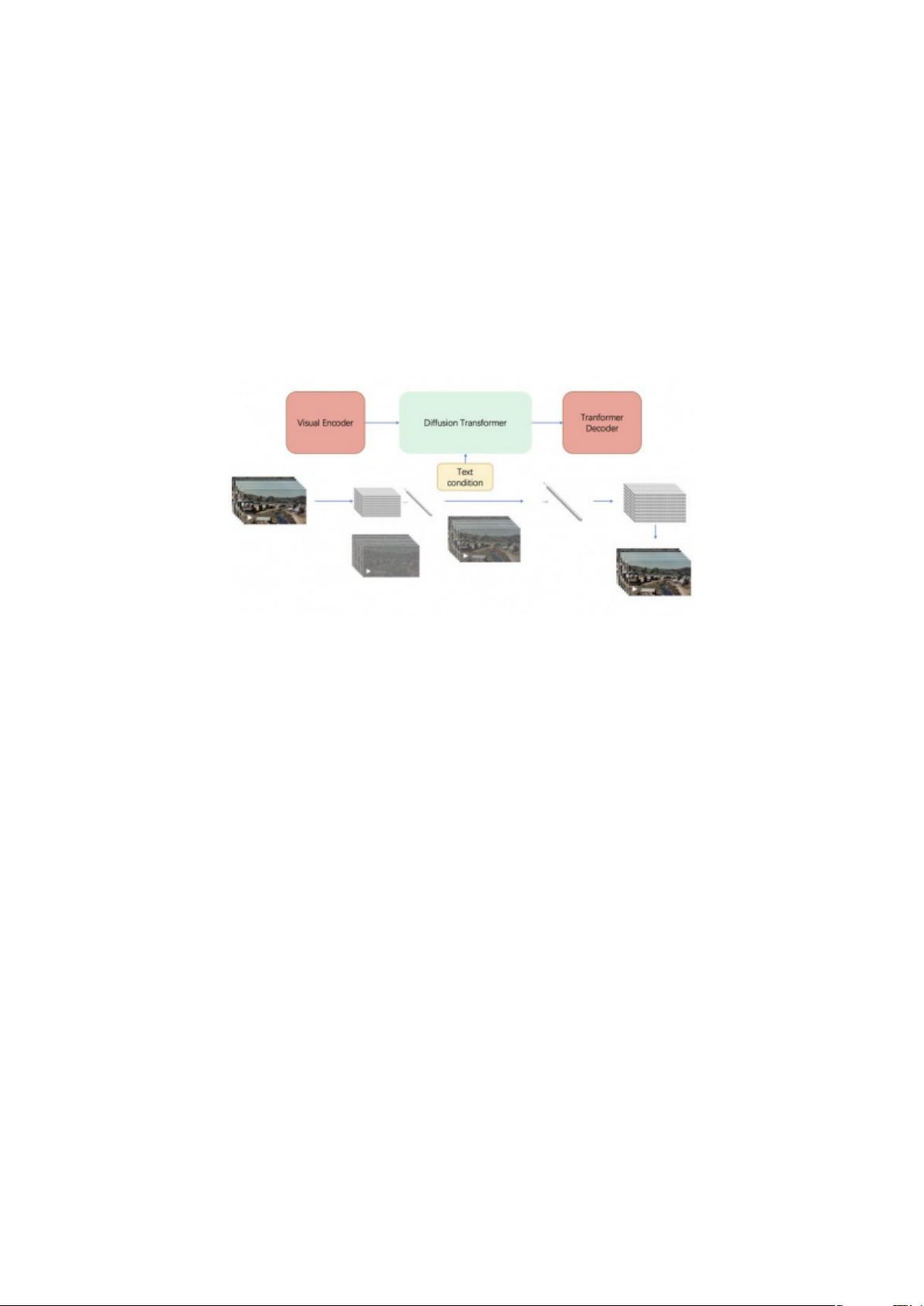
Sora 生成视频的流程
那 Sora 是怎么做的呢?接下来我们通过一张图来了解下 Sora 的工作流程,
大概可以简化为三个部分:
简单来说,Sora 就是依赖了两个模型 Latent Diffusion Model (LDM) 加上
Diffusion Transformer (DiT)。我们先简要回顾一下这两种模型架构。
LDM 就是 Stable Diffusion 使用的模型架构。扩散模型的一大问题是计算需求
大,难以拟合高分辨率图像。为了解决这一问题,实现 LDM 时,会先训练一
个几乎能无损压缩图像的自编码器,能把 512x512 的真实图像压缩成 64x64
的压缩图像并还原。接着,再训练一个扩散模型去拟合分辨率更低的压缩图像。
这样,仅需少量计算资源就能训练出高分辨率的图像生成模型。
LDM 的扩散模型使用的模型是 U-Net。而根据其他深度学习任务中的经验,相
比 U-Net,Transformer 架构的参数可拓展性强,即随着参数量的增加,
下载后可阅读完整内容,剩余7页未读,立即下载
相关推荐








工程师堡垒营
- 粉丝: 4870
 我的内容管理
展开
我的内容管理
展开







最新资源
- 安装Oracle必备:unixODBC-2.2.11-7.1.x86_64.rpm
- Spring Boot与Camel XML聚合快速入门教程
- React开发新工具:可拖动、可调整大小的窗口组件
- vlfeat-0.9.14 图像处理库深度解析
- Selenium自动化测试工具深度解析
- ASP.NET房产中介系统:房源信息发布与查询平台
- SuperScan4.1扫描工具深度解析
- 深入解析dede 3.5 Delphi反编译技术
- 深入理解ARM体系结构及编程技巧
- TcpEngine_0_8_0:网络协议模拟与单元测试工具
- Java EE实践项目:在线商城系统演示
- 打造苹果风格的Android ListView实现与下拉刷新
- 黑色质感个人徒步旅行HTML5项目源代码包
- Nuxt.js集成Vuetify模块教程
- ASP.NET+SQL多媒体教室管理系统设计实现
- 西北工业大学嵌入式系统课程PPT汇总
