
ENHANCING SIMILARITY MATRICES FOR MUSIC AUDIO ANALYSIS
Meinard M
¨
uller, Frank Kurth
Department of Computer Science III, University of Bonn
R
¨
omerstr. 164, D-53117 Bonn, Germany
{meinard, frank}@cs.uni-bonn.de
ABSTRACT
Similarity matrices have become an important tool in music audio
analysis. However, the quadratic time and space complexity as well
as the intricacy of extracting the desired structural information from
these matrices are often prohibitive with regard to real-world appli-
cations. In this paper, we describe an approach for enhancing the
structural properties of similarity matrices based on two concepts:
first, we introduce a new class of robust and scalable audio features
which absorb local temporal variations. As a second contribution,
we then incorporate contextual information into the local similarity
measure. The resulting enhancement leads to significant reduction in
matrix size and also eases the structure extraction step. As an exam-
ple, we sketch the application of our techniques to the problems of
audio summarization and audio synchronization, obtaining effective
and computationally feasible algorithms.
1. INTRODUCTION
The concept of similarity matrices has been introduced to the mu-
sic context by Foote in order to visualize the time structure of au-
dio and music [1]. The general idea is as follows: given two au-
dio data streams, one first transforms them into sequences
V :=
(v
1
,v
2
,...,v
N
) and
W := ( w
1
,w
2
,..., w
M
) of feature vectors
v
n
∈F, 1 ≤ n ≤ N,and w
m
∈F, 1 ≤ m ≤ M. Here, F denotes
a suitable feature space, e.g., a space of spectral, MFCC, or chroma
vectors. Based on a suitable similarity measure d : F×F →R,
one can form a similarity matrix S =(d(v
n
,w
m
))
nm
by pairwise
comparison of the features v
n
and w
m
. In case that
V =
W , the
resulting matrix is also referred to as self-similarity matrix.
Similarity matrices have proven to be a valuable tool in audio
analysis. In Sect. 3, we address two such analysis tasks: audio sum-
marization and audio synchronization. The underlying principle is
that similar segments are revealed as paths along diagonals in the
corresponding similarity matrix. As an example, we consider the
first 94 seconds of an Ormandy interpretation of Brahms’ Hungar-
ian Dance No. 5, having the musical form A
1
A
2
B
1
B
2
(segment
A
2
being a repetition of A
1
and B
2
being a repetition of B
1
). The
self-similarity matrix (with respect to some suitable audio features),
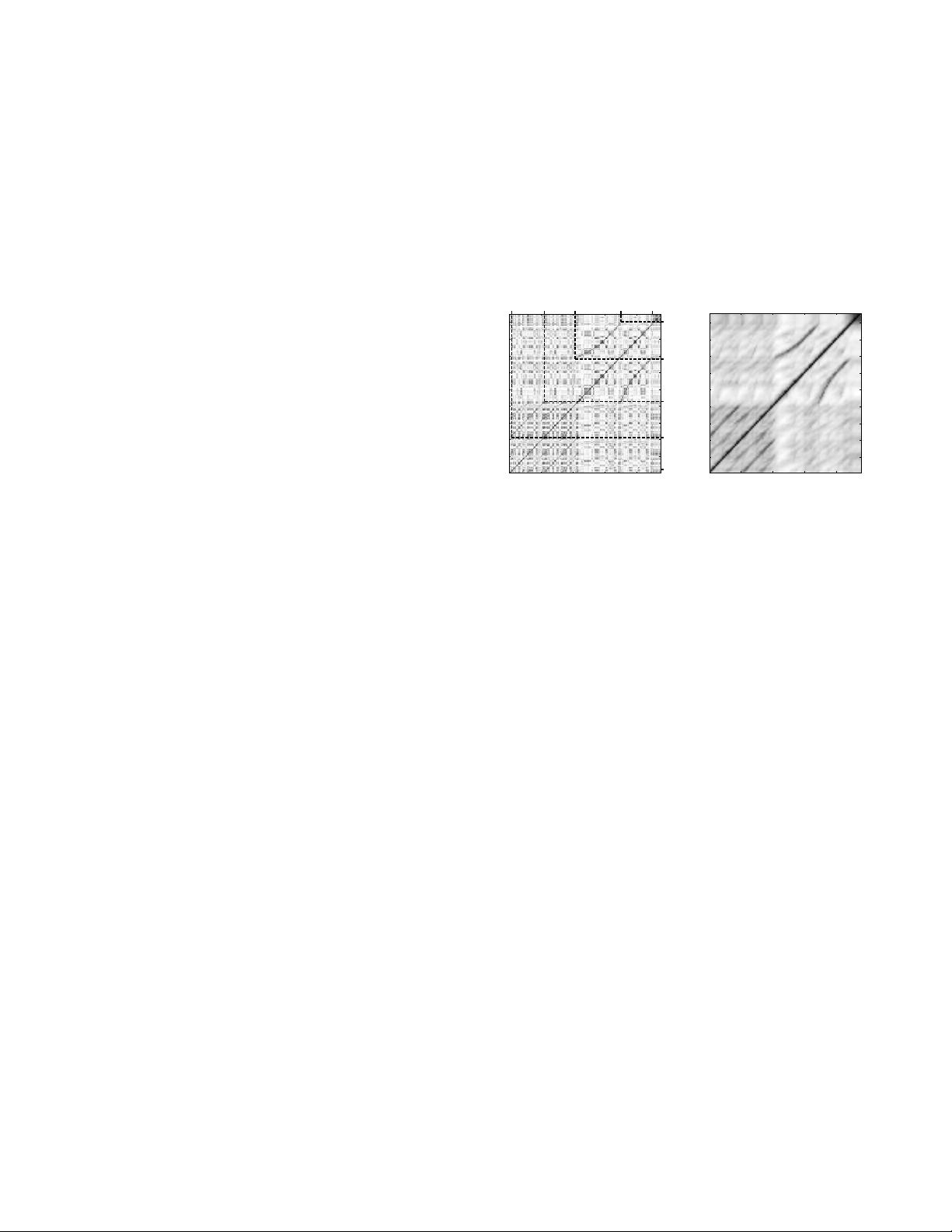
shown in Fig. 1, reveals this structure: the path in the lower left cor-
ner indicates that the segment between 1 and 22 is similar to the seg-
ment between 22 and 42 (measured in seconds), whereas the curved
path in the upper right corner indicates that the segment between 42
and 69 is similar to the segment between 69 and 89. Note that in
the Ormandy interpretation, the tempo of B
2
is much faster than that
of B
1
, which is revealed by the gradient of the path encoding the
relative tempo difference between the two segments.
There are two major problems in music audio analysis based on
similarity matrices: the first problem concerns the robust extraction
200 400 600 800
900
800
700
600
500
400
300
200
100
20 40 60 80
90
80
70
60
50
40
30
20
10
42
69
69
89
1 22
22
42
1
89
A
1
A
2
B
1
B
2
A
1
A
2
B
1
B
2
Fig. 1. Self-similarity matrices of the first 94 seconds of an Ormandy
interpretation of Brahm’s Hungarian Dances No. 5. The musical
form A
1
A
2
B
1
B
2
is revealed by the path structure. The left side
shows a matrix with a feature sampling rate of 10 Hz. The right side
shows an enhanced similarity matrix (S
min
10,2
(21, 5)) with a feature
sampling rate of 1 Hz.
of suitable paths revealing the structural similarity relations between
the underlying audio streams. So far, this problem has been studied
under the constant tempo assumption, which typically holds for pop
music, see Sect. 3.1 for references. For the case, however, that musi-
cally similar segments exhibit significant local tempo variations—as
often holds for Western classical music—there are yet no effective
and efficient solutions. The second problem concerns the high time
and space complexity O(NM) to compute and store the similarity
matrices, which makes the usage of similarity matrices infeasible
for large N and M . Here, reducing the number N and M by simply
increasing the feature analysis window often destroys the structural
properties of the similarity matrices, see Fig. 5.
In this paper, we suggest an approach for enhancing the path
structure of similarity matrices, which constitutes an important step
towards a solution of the above mentioned problems. In particular,
we cope with the delicate tradeoff between needing coarse and ro-
bust features on the one hand and requiring sufficient flexibility to
deal with local tempo variations on the other hand. Our basic idea
towards finding a good tradeoff can be summarized as follows. In-
stead of relying on one single mechanism, we take care of the tempo-
ral variations on various levels simultaneously: on the “feature level”
(using statistical features to absorb micro-variations), on the “local
distance measure level” (including flexible contextual information to
account for local variations) as well as on the “path extraction level”
(accounting for coarse global time variations). In Sect. 2, we de-
scribe this approach in detail and apply the techniques to the class of
chroma features. In Sect. 3, we then sketch the impact of our matrix
enhancement techniques to the problems of music summarization
V9142440469X/06/$20.00©2006IEEE ICASSP2006
下载后可阅读完整内容,剩余3页未读,立即下载

rogermansuy
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


