Hadoop分布式存储与计算详解
"细解Hadoop——分布式存储与计算框架"
Hadoop是一个开源的分布式计算框架,由Apache基金会开发,主要用于处理和存储大规模数据。它的核心包括两个主要组件:Hadoop Distributed File System (HDFS) 和 MapReduce。这两个组件共同构成了一个高效、容错性强的系统,能够处理PB级别的数据。
### 分布式引例
分布式计算通常面临三类问题:存储、计算和可靠性。例如,如何在多台机器上分布存储文件并保持一致的访问体验?如何对分布式存储的数据进行高效计算?以及如何保证系统的高可用性和数据的持久性?
### Hadoop 1.0 架构
Hadoop 1.0 主要由HDFS和MapReduce构成:
- **HDFS** 是一个分布式文件系统,它将大文件分割成多个块,这些块被复制并分布在不同的节点上,以提高容错性和性能。每个数据块都有多个副本,通常默认是3个。
- **MapReduce** 是一种编程模型,用于大规模数据集的并行处理。它分为Map阶段和Reduce阶段,Map阶段将任务分解,Reduce阶段则负责整合结果。
### Hadoop 1.0 编程
开发者使用Java编写MapReduce程序,通过实现Map和Reduce接口来进行数据处理。Map任务在数据所在的节点上运行,以减少网络传输,而Reduce任务则聚合Map的输出。
### Hadoop 1.0 弊端
Hadoop 1.0 存在一些问题,如JobTracker作为单一控制点,容易成为性能瓶颈,以及MapReduce设计上的局限,使得它不适合迭代计算和交互式查询。
### Hadoop 2.0 架构
为了解决这些问题,Hadoop 2.0 引入了YARN(Yet Another Resource Negotiator),将资源管理和作业调度功能分离。YARN成为整个集群的中央资源调度器,而MapReduce被改造为运行在YARN之上的应用。
### Hadoop 2.0 编程
在Hadoop 2.0中,MapReduce的编程模型基本保持不变,但运行在YARN上,使得资源分配更加灵活,支持更多种类的应用。
### Hadoop 2.0 部署
Hadoop 2.0 可以部署在社区版(开源版本)或商用版(例如Cloudera、 Hortonworks等公司提供的商业发行版)上,提供了更高级的安全性、管理工具和性能优化。
### 结论
Hadoop通过分布式存储和计算,为大数据处理提供了一种有效的方式。从Hadoop 1.0到Hadoop 2.0的演进,体现了分布式系统在解决挑战时的不断进化和优化。无论是在存储还是计算方面,Hadoop都为企业和研究机构处理大规模数据提供了强大的工具。
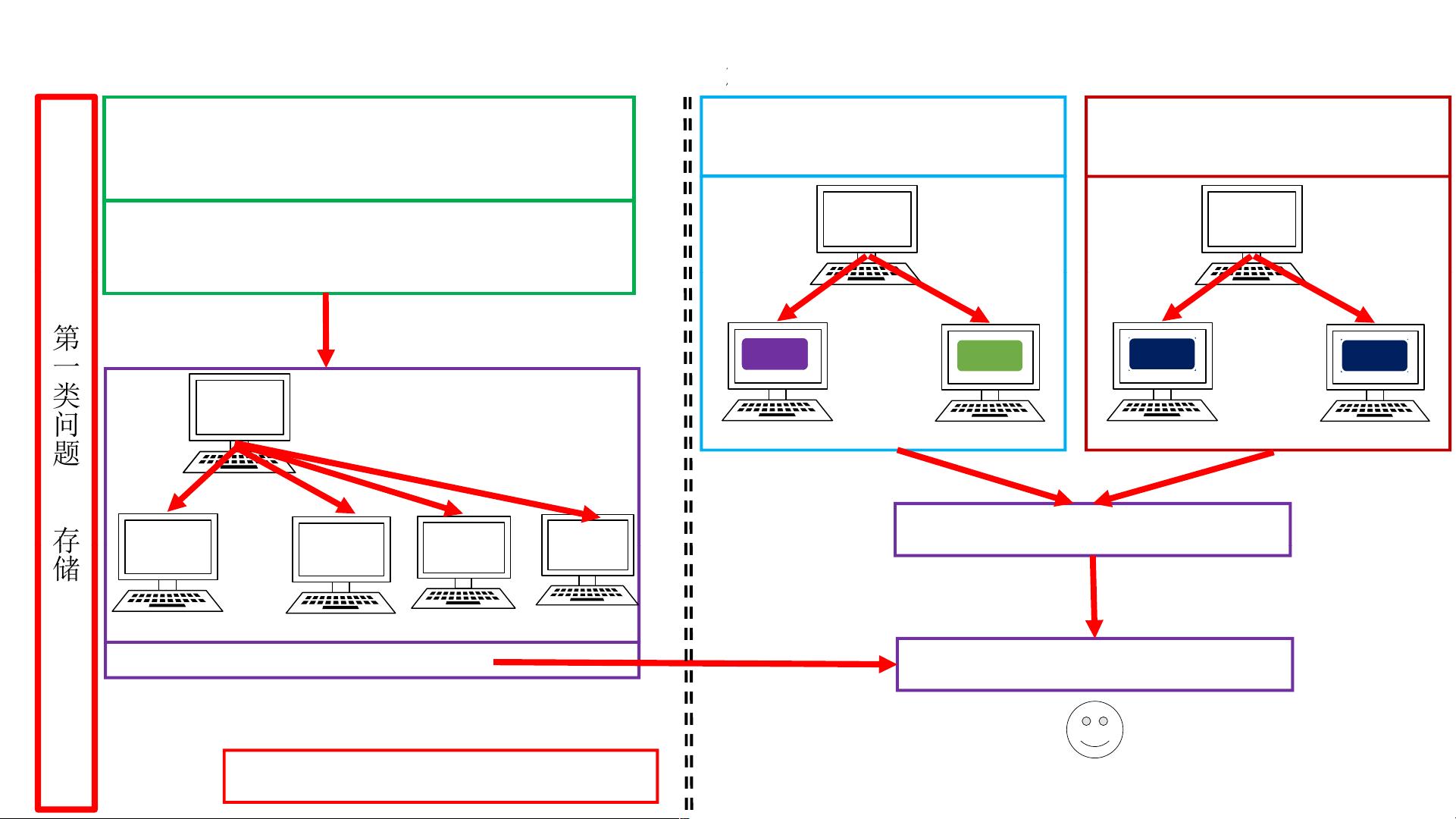
分布式引例
分布式
解决方案
思路
取M01,M02,M99
构建master/slave体系分布式集群
规定
M99:不做存储,统一管理M01,M02硬盘空间
M01,M02:存储具体文件
由于硬盘连在一起
第一类问题
存储
M01,M02:存储具体文件
M99
存储
主节点
分布式存储架构思路
存储
M01
M02
由于采用master/slave架构,很容易添加slave
M03
M0X
分布式引例
解决方案
存储问题②
由于硬盘空间大,可任意存
存储问题①
由于硬盘连在一起
,可任意存
存储
主节点
存储
主节点
M99
M01
M02
M99
M01
M02
file01
file02
file03
file03
采用分布式--存储问题全部解决
Hadoop里Hdfs架构思想

剩余43页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

duheaven
- 粉丝: 36
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- HueDances:我制作的一个随机Node.js程序使您的Philips Hue经常切换颜色
- pwl_uts
- lanarts-moai:说明即将推出
- CaesarCipher:这是一个Java程序,用于执行凯撒密码的加密和解密
- pp_2021_spring_engineers
- Fake-DHCPv6-Attack:虚假DHCPv6攻击
- Propel.Net-开源
- APScheduler-3.7.0-py2.py3-none-any.whl.zip
- CPLEX2210 for Win 无约束限制
- hamidou.tessilimi:我的投资组合
- CI-CD-Deployment-for-Springboot-Application
- AudioRecorder_0.4-62.rar
- asp网页进行串口通信
- OpenRC:包含我用于RC车辆的所有3d打印文件的存储库
- Npcgen Editor.zip
- Multiword Expressions-开源
