Airbnb流处理框架:事件日志与Kafka Druid解决方案
Airbnb是一家全球知名的在线住宿预订平台,其在处理海量流数据方面有着丰富的实践和经验。本文将深入探讨Airbnb所采用的流处理框架,重点关注两个关键组件:Kafka和Druid,以及它们在事件日志管理、数据存储和计算流程中的角色。
首先,Kafka是Airbnb用来收集和传输实时数据的主要工具。它是一个分布式的发布/订阅消息系统,支持高吞吐量、容错性和可扩展性。Kafka在Airbnb的架构中扮演了核心角色,作为事件(Event)日志的源头(Source),用于捕获用户行为、系统操作等各种实时数据,并通过集群(Cluster)进行分发,确保数据的实时性和可靠性。此外,Kafka还与HDFS(Hadoop Distributed File System)和Hive等大数据存储系统集成,提供数据持久化的能力。
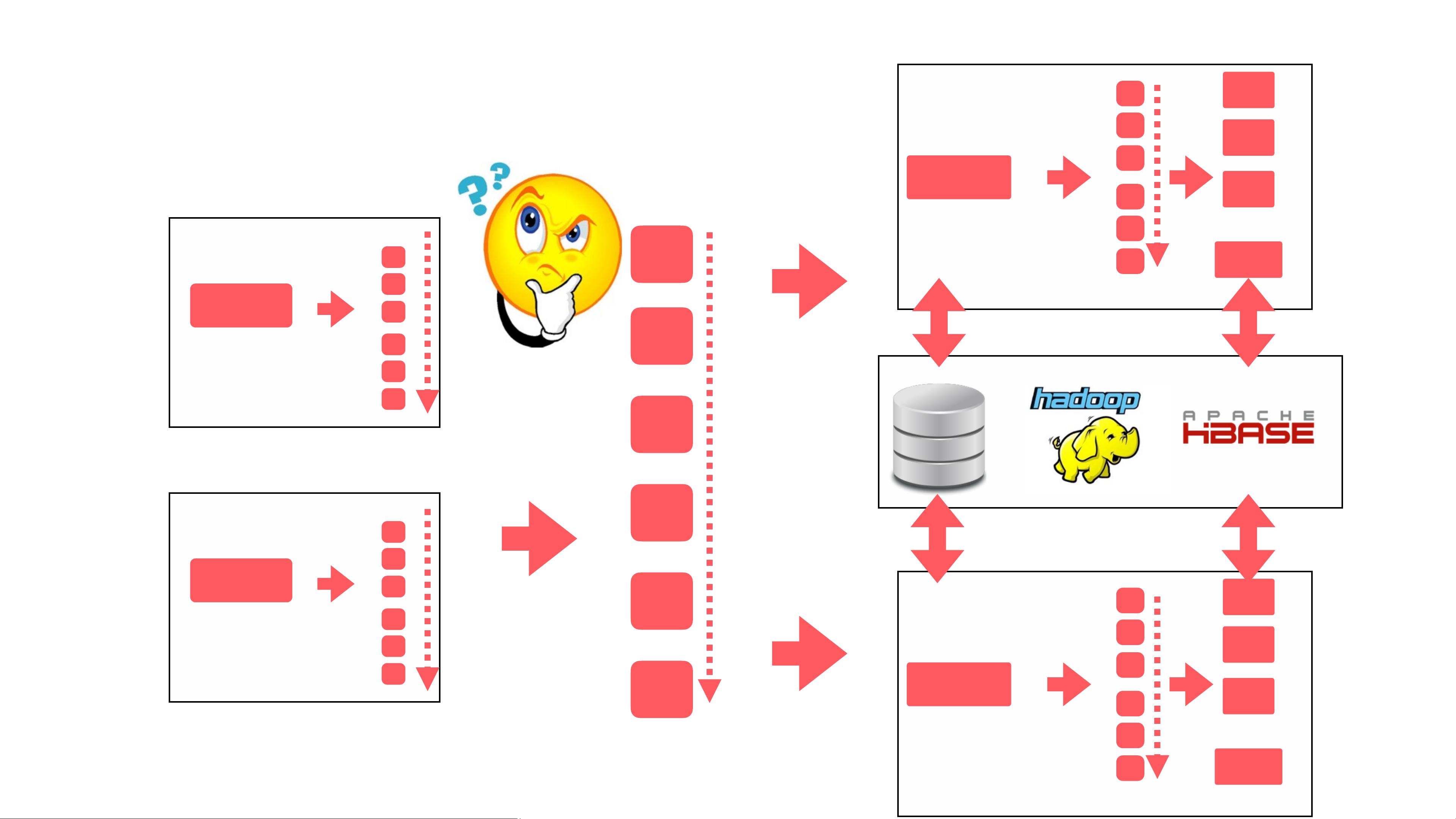
Druid是Airbnb用来进行实时分析的数据库,尤其在数据查询性能和实时报表方面表现出色。它是一个高度优化的SQL查询引擎,特别适合对实时或近实时数据进行复杂的分析。Druid能够处理大量的实时数据流(DStream),并提供实时聚合(Computation)、状态存储(StateStorage)等功能。与Spark Streaming和Spark Cluster结合,Druid支持DataFrame API,使得数据处理过程更加简洁和统一,可以方便地定义多个流处理任务(MultipleStreams),每个任务包含多个数据处理阶段(ProcessA、ProcessB等)和多个sink(Sink1、Sink2等),这些sink负责数据的最终消费和存储,比如MySQL、HBase或者S3。
Airbnb在流处理过程中也遇到了一些挑战,如数据的无状态(Stateless)处理和有限的内存管理。无状态设计有助于简化系统,但可能导致数据一致性问题;而内存限制则需要优化计算效率,确保在有限资源下处理大量数据。此外,Airbnb还在尝试通过工具如Airflow进行任务调度,以及利用Tableau等可视化工具来监控和展示流处理结果。
为了实现流处理与批处理的融合(Streaming+Batch),Airbnb可能会利用Spark的灵活性,结合DataFrame API,在同一个数据处理流程中无缝切换,既处理实时数据,又支持批量作业的执行。同时,通过工具如AirPal和Caravel(数据仓库工具)对数据进行管理和分析,进一步提升数据驱动决策的效率。
总结来说,Airbnb的流处理框架围绕Kafka和Druid构建,这两个组件在数据采集、实时分析、存储和可视化等方面发挥了关键作用。通过优化数据管道,Airbnb成功地实现了大规模流数据的高效处理和实时洞察,从而驱动业务的增长和改进。
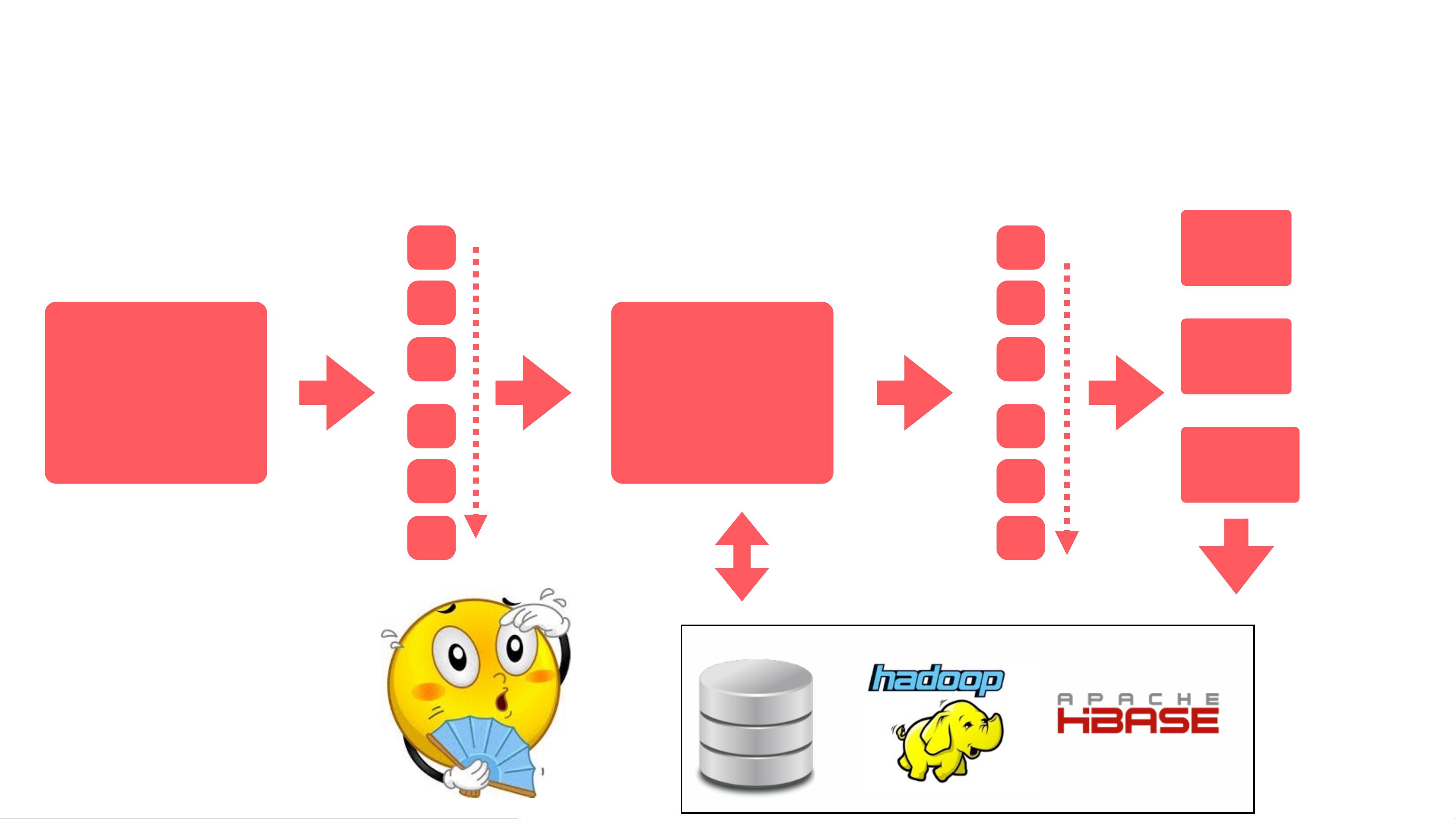
Stateful
Liyin Tang and Jingwei Lu
Computation
Source
DStream DF DF
Sink1
Sink2
Sink N
State Storage
RDD
剩余39页未读,继续阅读
2021-04-01 上传
2021-03-26 上传
2021-02-24 上传
2021-03-26 上传
2021-03-30 上传
2021-05-11 上传
2021-02-17 上传

Dyingbleed
- 粉丝: 2
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
